溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“TensorFlow Serving在Kubernetes中怎么配置”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
下面是TensorFlow Serving的架構圖:
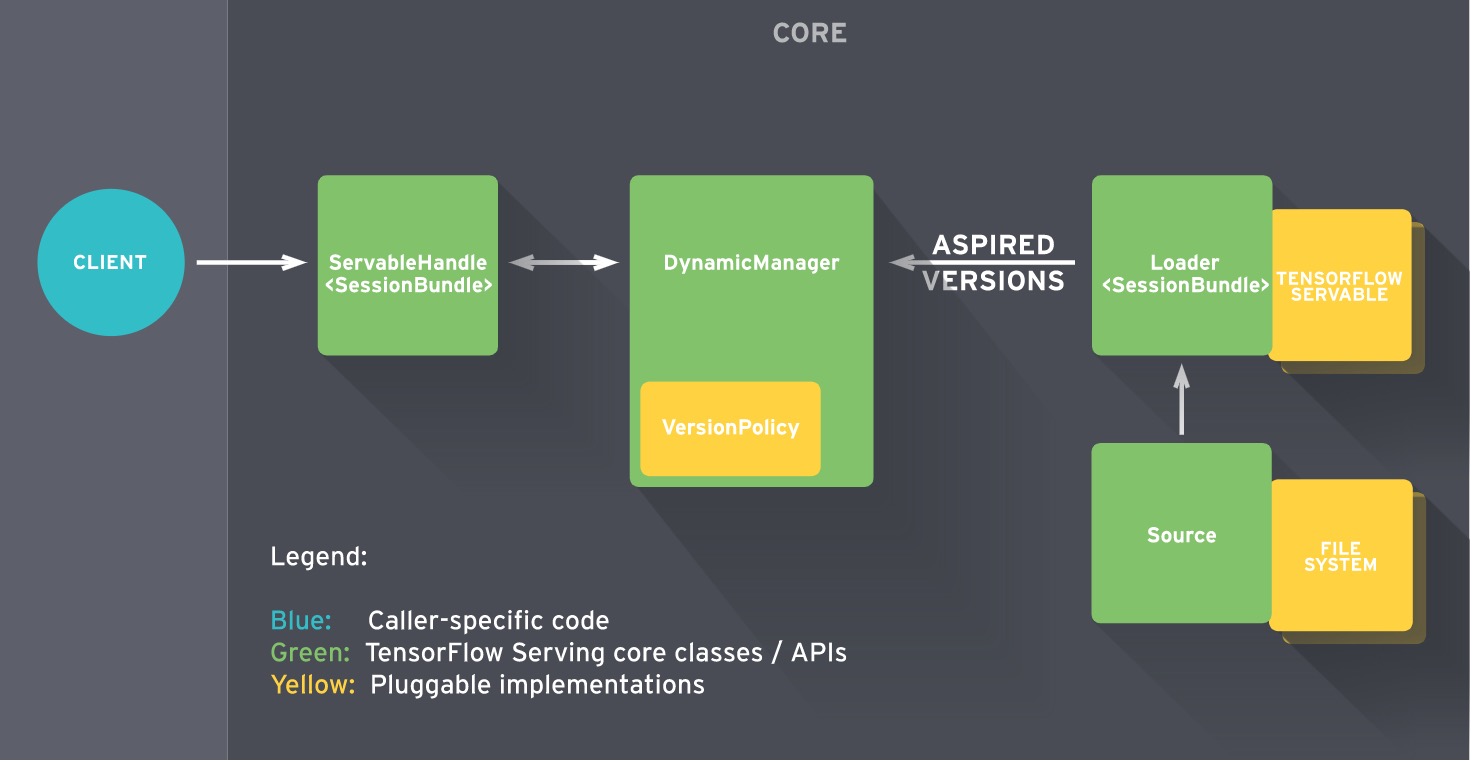
關于TensorFlow Serving的更多基礎概念等知識,請看官方文檔,翻譯的再好也不如原文寫的好。
這里,我總結了下面一些知識點,我認為是比較重要的:
TensorFlow Serving通過Model Version Policy來配置多個模型的多個版本同時serving;
默認只加載model的latest version;
支持基于文件系統的模型自動發現和加載;
請求處理延遲低;
無狀態,支持橫向擴展;
可以使用A/B測試不同Version Model;
支持從本地文件系統掃描和加載TensorFlow模型;
支持從HDFS掃描和加載TensorFlow模型;
提供了用于client調用的gRPC接口;
當我翻遍整個TensorFlow Serving的官方文檔,我還是沒找到一個完整的model config是怎么配置的,很沮喪。沒辦法,發展太快了,文檔跟不上太正常,只能擼代碼了。
在model_servers的main方法中,我們看到tensorflow_model_server的完整配置項及說明如下:
tensorflow_serving/model_servers/main.cc#L314
int main(int argc, char** argv) {
...
std::vector<tensorflow::Flag> flag_list = {
tensorflow::Flag("port", &port, "port to listen on"),
tensorflow::Flag("enable_batching", &enable_batching, "enable batching"),
tensorflow::Flag("batching_parameters_file", &batching_parameters_file,
"If non-empty, read an ascii BatchingParameters "
"protobuf from the supplied file name and use the "
"contained values instead of the defaults."),
tensorflow::Flag("model_config_file", &model_config_file,
"If non-empty, read an ascii ModelServerConfig "
"protobuf from the supplied file name, and serve the "
"models in that file. This config file can be used to "
"specify multiple models to serve and other advanced "
"parameters including non-default version policy. (If "
"used, --model_name, --model_base_path are ignored.)"),
tensorflow::Flag("model_name", &model_name,
"name of model (ignored "
"if --model_config_file flag is set"),
tensorflow::Flag("model_base_path", &model_base_path,
"path to export (ignored if --model_config_file flag "
"is set, otherwise required)"),
tensorflow::Flag("file_system_poll_wait_seconds",
&file_system_poll_wait_seconds,
"interval in seconds between each poll of the file "
"system for new model version"),
tensorflow::Flag("tensorflow_session_parallelism",
&tensorflow_session_parallelism,
"Number of threads to use for running a "
"Tensorflow session. Auto-configured by default."
"Note that this option is ignored if "
"--platform_config_file is non-empty."),
tensorflow::Flag("platform_config_file", &platform_config_file,
"If non-empty, read an ascii PlatformConfigMap protobuf "
"from the supplied file name, and use that platform "
"config instead of the Tensorflow platform. (If used, "
"--enable_batching is ignored.)")};
...
}因此,我們看到關于model version config的配置,全部在--model_config_file中進行配置,下面是model config的完整結構:
tensorflow_serving/config/model_server_config.proto#L55
// Common configuration for loading a model being served.
message ModelConfig {
// Name of the model.
string name = 1;
// Base path to the model, excluding the version directory.
// E.g> for a model at /foo/bar/my_model/123, where 123 is the version, the
// base path is /foo/bar/my_model.
//
// (This can be changed once a model is in serving, *if* the underlying data
// remains the same. Otherwise there are no guarantees about whether the old
// or new data will be used for model versions currently loaded.)
string base_path = 2;
// Type of model.
// TODO(b/31336131): DEPRECATED. Please use 'model_platform' instead.
ModelType model_type = 3 [deprecated = true];
// Type of model (e.g. "tensorflow").
//
// (This cannot be changed once a model is in serving.)
string model_platform = 4;
reserved 5;
// Version policy for the model indicating how many versions of the model to
// be served at the same time.
// The default option is to serve only the latest version of the model.
//
// (This can be changed once a model is in serving.)
FileSystemStoragePathSourceConfig.ServableVersionPolicy model_version_policy =
7;
// Configures logging requests and responses, to the model.
//
// (This can be changed once a model is in serving.)
LoggingConfig logging_config = 6;
}我們看到了model_version_policy,那便是我們要找的配置,它的定義如下:
tensorflow_serving/sources/storage_path/file_system_storage_path_source.proto
message ServableVersionPolicy {
// Serve the latest versions (i.e. the ones with the highest version
// numbers), among those found on disk.
//
// This is the default policy, with the default number of versions as 1.
message Latest {
// Number of latest versions to serve. (The default is 1.)
uint32 num_versions = 1;
}
// Serve all versions found on disk.
message All {
}
// Serve a specific version (or set of versions).
//
// This policy is useful for rolling back to a specific version, or for
// canarying a specific version while still serving a separate stable
// version.
message Specific {
// The version numbers to serve.
repeated int64 versions = 1;
}
}因此model_version_policy目前支持三種選項:
all: {} 表示加載所有發現的model;
latest: { num_versions: n } 表示只加載最新的那n個model,也是默認選項;
specific: { versions: m } 表示只加載指定versions的model,通常用來測試;
因此,通過tensorflow_model_server —port=9000 —model_config_file=<file>啟動時,一個完整的model_config_file格式可參考如下:
model_config_list: {
config: {
name: "mnist",
base_path: "/tmp/monitored/_model",mnist
model_platform: "tensorflow",
model_version_policy: {
all: {}
}
},
config: {
name: "inception",
base_path: "/tmp/monitored/inception_model",
model_platform: "tensorflow",
model_version_policy: {
latest: {
num_versions: 2
}
}
},
config: {
name: "mxnet",
base_path: "/tmp/monitored/mxnet_model",
model_platform: "tensorflow",
model_version_policy: {
specific: {
versions: 1
}
}
}
}其實TensorFlow Serving的編譯安裝,在github setup文檔中已經寫的比較清楚了,在這里我只想強調一點,而且是非常重要的一點,就是文檔中提到的:
Optimized build It's possible to compile using some platform specific instruction sets (e.g. AVX) that can significantly improve performance. Wherever you see 'bazel build' in the documentation, you can add the flags -c opt --copt=-msse4.1 --copt=-msse4.2 --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-O3 (or some subset of these flags). For example: bazel build -c opt --copt=-msse4.1 --copt=-msse4.2 --copt=-mavx --copt=-mavx2 --copt=-mfma --copt=-O3 tensorflow_serving/... Note: These instruction sets are not available on all machines, especially with older processors, so it may not work with all flags. You can try some subset of them, or revert to just the basic '-c opt' which is guaranteed to work on all machines.
這很重要,開始的時候我們并沒有加上對應的copt選項進行編譯,測試發現這樣編譯出來的tensorflow_model_server的性能是很差的(至少不能滿足我們的要求),client并發請求tensorflow serving的延遲很高(基本上所有請求延遲都大于100ms)。加上這些copt選項時,對同樣的model進行同樣并發測試,結果99.987%的延遲都在50ms以內,對比懸殊。
關于使用--copt=O2還是O3及其含義,請看gcc optimizers的說明,這里不作討論。(因為我也不懂...)
那么,是不是都是按照官方給出的一模一樣的copt選項進行編譯呢?答案是否定的!這取決于你運行TensorFlow Serving的服務器的cpu配置,通過查看/proc/cpuinfo可知道你該用的編譯copt配置項:

由于TensorFlow支持同時serve多個model的多個版本,因此建議client在gRPC調用時盡量指明想調用的model和version,因為不同的version對應的model不同,得到的預測值也可能大不相同。
將訓練好的模型復制導入到model base path時,盡量先壓縮成tar包,復制到base path后再解壓。因為模型很大,復制過程需要耗費一些時間,這可能會導致導出的模型文件已復制,但相應的meta文件還沒復制,此時如果TensorFlow Serving開始加載這個模型,并且無法檢測到meta文件,那么服務器將無法成功加載該模型,并且會停止嘗試再次加載該版本。
如果你使用的protobuf version <= 3.2.0,那么請注意TensorFlow Serving只能加載不超過64MB大小的model。可以通過命令 pip list | grep proto查看到probtobuf version。我的環境是使用3.5.0 post1,不存在這個問題,請你留意。更多請查看issue 582。
官方宣稱支持通過gRPC接口動態更改model_config_list,但實際上你需要開發custom resource才行,意味著不是開箱即用的。可持續關注issue 380。
將TensorFlow Serving以Deployment方式部署到Kubernetes中,下面是對應的Deployment yaml:
apiVersion: extensions/v1beta1 kind: Deployment metadata: name: tensorflow-serving spec: replicas: 1 template: metadata: labels: app: "tensorflow-serving" spec: restartPolicy: Always imagePullSecrets: - name: harborsecret containers: - name: tensorflow-serving image: registry.vivo.xyz:4443/bigdata_release/tensorflow_serving1.3.0:v0.5 command: ["/bin/sh", "-c","export CLASSPATH=.:/usr/lib/jvm/java-1.8.0/lib/tools.jar:$(/usr/lib/hadoop-2.6.1/bin/hadoop classpath --glob); /root/tensorflow_model_server --port=8900 --model_name=test_model --model_base_path=hdfs://xx.xx.xx.xx:zz/data/serving_model"] ports: - containerPort: 8900
“TensorFlow Serving在Kubernetes中怎么配置”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





