溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
作者:Anton H?gerstrand
翻譯:楊振濤
目錄:
Meltwater每天要處理數百萬量級的帖子數據,因此需要一種能處理該量級數據的存儲和檢索技術。
從0.11.X 版本開始我們就已經是Elasticsearch的忠實用戶了。在經歷了一些波折之后,最終我們認為做出了正確的技術選型。
Elasticsearch 用于支持我們的主要媒體監控應用,客戶通過該應用可以檢索和分析媒體數據,比如新聞文章、(公開的)Facebook帖子、Instagram帖子、博客和微博。我們通過使用一個混合API來收集這些內容,并爬取和稍作加工,使得它們可被 Elasticsearch 檢索到。
本文將分享我們所學到的經驗、如何調優 Elasticsearch,以及要繞過的一些陷阱。
如果想了解更多關于我們在Elasticsearch方面的點滴,可參考之前博文中的 numad issues 和 batch percolator。
每天都有數量相當龐大的新聞和微博產生;在高峰期需要索引大約300多萬社論文章,和近1億條社交帖子數據。其中社論數據長期保存以供檢索(可回溯到2009年),社交帖子數據保存近15個月的。當前的主分片數據使用了大約200 TB的磁盤空間,副本數據大約600 TB。
我們的業務每分鐘有3千次請求。所有的請求通過一個叫做 “search-service” 的服務,該服務會依次完成所有與 Elasticsearch 集群的交互。大部分檢索規則比較復雜,包括在面板和新聞流中。比如,一個客戶可能對 Tesla 和 Elon Musk 感興趣,但希望排除所有關于 SpaceX 或 PayPal 的信息。用戶可以使用一種與 Lucene 查詢語法類似的靈活語法,如下:
Tesla AND "Elon Musk" NOT (SpaceX OR PayPal)
我們最長的此類查詢有60多頁。重點是:除了每分鐘3千次請求以外,沒有一個查詢是像在 Google 里查詢 “Barack Obama” 這么簡單的;這簡直就是可怕的野獸,但ES節點必須努力找出一個匹配的文檔集。

我們運行的是一個基于 Elasticsearch 1.7.6 的定制版本。該版本與1.7.6 主干版本的唯一區別是,我們向后移植(backport)了 roaring bitsets/bitmaps 作為緩存。該功能是從 Lucene 5 移植到 Lucene 4 的,對應移植到了 ES 1.X 版本。Elasticsearch 1.X 中使用默認的 bitset 作為緩存,對于稀疏結果來說開銷非常大,不過在 Elasticsearch 2.X 中已經做了優化。
為何不使用較新版本的 Elasticsearch 呢?主要原因是升級困難。在主版本間滾動升級只適用于從ES 5到6(從ES 2到5應該也支持滾動升級,但沒有試過)。因此,我們只能通過重啟整個集群來升級。宕機對我們來說幾乎不可接受,但或許可以應對一次重啟所帶來的大約30-60分鐘宕機時間;而真正令人擔心的,是一旦發生故障并沒有真正的回滾過程。
截止目前我們選擇了不升級集群。當然我們希望可以升級,但目前有更為緊迫的任務。實際上該如何實施升級尚未有定論,很可能選擇創建另一個新的集群,而不是升級現有的。
我們自2017年6月開始在AWS上運行主集群,使用i3.2xlarge實例作為數據節點。之前我們在COLO(Co-located Data Center)里運行集群,但后續遷移到了AWS云,以便在新機器宕機時能贏得時間,使得我們在擴容和縮容時更加彈性。
我們在不同的可用區運行3個候選 master 節點,并設置 discovery.zen.minimum_master_nodes 為2。這是避免腦裂問題 split-brain problem 非常通用的策略。
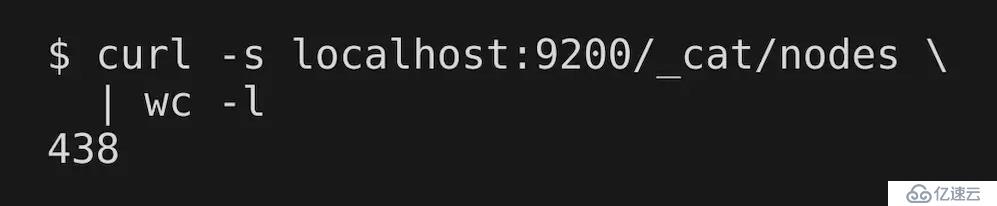
我們的數據集在存儲方面,要求80%容量和3個以上的副本,這使得我們運行了430個數據節點。起初打算使用不同層級的數據,在較慢的磁盤上存儲較舊的數據,但是由于我們只有相關的較低量級舊于15個月的數據(只有編輯數據,因為我們丟棄了舊的社交數據),然而這并未奏效。每個月的硬件開銷遠大于運行在COLO中,但是云服務支持擴容集群到2倍,而幾乎不用花費多少時間。
你可能會問,為何選擇自己管理維護ES集群。其實我們考慮過托管方案,但最后還是選擇自己安裝,理由是: AWS Elasticsearch Service
暴露給用戶的可控性太差了,Elastic Cloud 的成本比直接在EC2上運行集群要高2-3倍。
為了在某個可用區宕機時保護我們自身,節點分散于eu-west-1的所有3個可用區。我們使用 AWS plugin 來完成該項配置。它提供了一個叫做aws_availability_zone 的節點屬性,我們把 cluster.routing.allocation.awareness.attributes 設置為 aws_availability_zone。這保證了ES的副本盡可能地存儲在不同的可用區,而查詢盡可能被路由到相同可用區的節點。
這些實例運行的是 Amazon Linux,臨時掛載為 ext4,有約64GB的內存。我們分配了26GB用于ES節點的堆內存,剩下的用于磁盤緩存。為何是26GB?因為 JVM 是在一個黑魔法之上構建的 。
我們同時使用 Terraform 自動擴容組來提供實例,并使用 Puppet 完成一切安裝配置。
因為我們的數據和查詢都是基于時間序列的,所以使用了 time-based indexing ,類似于ELK (elasticsearch, logstash, kibana) stack。同時也讓不同類型的數據保存在不同的索引庫中,以便諸如社論文檔和社交文檔類數據最終位于不同的每日索引庫中。這樣可以在需要的時候只丟棄社交索引,并增加一些查詢優化。每個日索引運行在兩個分片中的一個。
該項設置產生了大量的分片(接近40k)。有了這么多的分片和節點,集群操作有時變得更特殊。比如,刪除索引似乎成為集群master的能力瓶頸,它需要把集群狀態信息推送給所有節點。我們的集群狀態數據約100 MB,但通過TCP壓縮可減少到3 MB(可以通過 curl localhost:9200/_cluster/state/_all 查看你自己集群的狀態數據)。Master 節點仍然需要在每次變更時推送1.3 GB數據(430 節點 x 3 MB 狀態大小)。除了這1.3 GB數據外,還有約860 MB必須在可用區(比如 最基本的通過公共互聯網)之間傳輸。這會比較耗時,尤其是在刪除數百個索引時。我們希望新版本的 Elasticsearch 能優化這一點,首先從 ES 2.0支持僅發送集群狀態的差分數據 這一特性開始。
如前所述,我們的ES集群為了滿足客戶的檢索需求,需要處理一些非常復雜的查詢。
為應對查詢負載,過去幾年我們在性能方面做了大量的工作。我們必須嘗試公平分享ES集群的性能測試,從下列引文就可以看出。
不幸的是,當集群宕機的時候,不到三分之一的查詢能成功完成。我們相信測試本身導致了集群宕機。
—— 摘錄自使用真實查詢在新ES集群平臺上的第一次性能測試
為了控制查詢執行過程,我們開發了一個插件,實現了一系列自定義查詢類型。通過使用這些查詢類型來提供Elasticsearch官方版本不支持的功能和性能優化。比如,我們實現了 phrases 中的 wildcard 查詢,支持在 SpanNear 查詢中執行;另一個優化是支持“*”代替 match-all-query ;還有其他一系列特性。
Elasticsearch 和 Lucene 的性能高度依賴于具體的查詢和數據,沒有銀彈。即便如此,仍可給出一些從基礎到進階的參考:
限制你的檢索范圍,僅涉及相關數據。比如,對于每日索引庫,只按相關日期范圍檢索。對于檢索范圍中間的索引,避免使用范圍查詢/過濾器。
使用wildcards時忽略前綴wildcards - 除非你能對term建立倒排索引。雙端wildcards難以優化。
關注資源消耗的相關跡象 數據節點的CPU占用持續飆高嗎?IQ等待走高嗎?看看GC統計。這些可以從profilers工具或者通過 JMX 代理獲得。如果 ParNewGC 消耗了超過15%的時間,去檢查下內存日志。如果有任何的 SerialGC 停頓,你可能真的遇到問題了。不太了解這些內容?
沒關系,這個系列博文很好地介紹了JVM性能 。記住,ES和G1垃圾回收器一起并非最佳 。
如果遇到垃圾回收問題,請不要嘗試調整GC設置。這一點經常發生,因為默認設置已經很合理了。相反,應該聚焦在減少內存分配上。具體怎么做?參考下文。
如果遇到內存問題,但沒有時間解決,可考慮查詢Azul Zing。這是一個很貴的產品,但僅僅使用它們的JVM就可以提升2倍的吞吐量。不過最終我們并沒有使用它,因為我們無法證明物有所值。
考慮使用緩存,包括 Elasticsearch 外緩存和 Lucene 級別的緩存。在 Elasticsearch 1.X 中可以通過使用 filter 來控制緩存。之后的版本中看起來更難一些,但貌似可以實現自己用于緩存的查詢類型。我們在未來升級到2.X的時候可能會做類似的工作。
查看是否有熱點數據(比如某個節點承擔了所有的負載)。可以嘗試均衡負載,使用分片分配過濾策略 shard allocation filtering ,或者嘗試通過集群重新路由 cluster rerouting 來自行遷移分片。我們已經使用線性優化自動重新路由,但使用簡單的自動化策略也大有幫助。
搭建測試環境(我更喜歡筆記本)可從線上環境加載一部分代表性的數據(建議至少有一個分片)。使用線上的查詢回放加壓(較難)。使用本地設置來測試請求的資源消耗。
綜合以上各點,在 Elasticsearch 進程上啟用一個 profiler。這是本列表中最重要的一條。
我們同時通過Java Mission Control 和 VisualVM 使用飛行記錄器。在性能問題上嘗試投機(包括付費顧問/技術支持)的人是在浪費他們(以及你自己)的時間。排查下 JVM 哪部分消耗了時間和內存,然后探索下 Elasticsearch/Lucene 源代碼,檢查是哪部分代碼在執行或者分配內存。
一旦搞清楚是請求的哪一部分導致了響應變慢,你就可以通過嘗試修改請求來優化(比如,修改term聚合的執行提示 ,或者切換查詢類型)。修改查詢類型或者查詢順序,可以有較大影響。如果不湊效,還可以嘗試優化 ES/Lucene 代碼。這看起來太夸張,卻可以為我們降低3到4倍的CPU消耗和4到8倍的內存使用。某些修改很細微(比如 indices query ),但其他人可能要求我們完全重寫查詢執行。最終的代碼嚴重依賴于我們的查詢模式,所以可能適合也可能不適合他人使用。因此目前為止我們并沒有開源這部分代碼。不過這可能是下一篇博文的好素材。
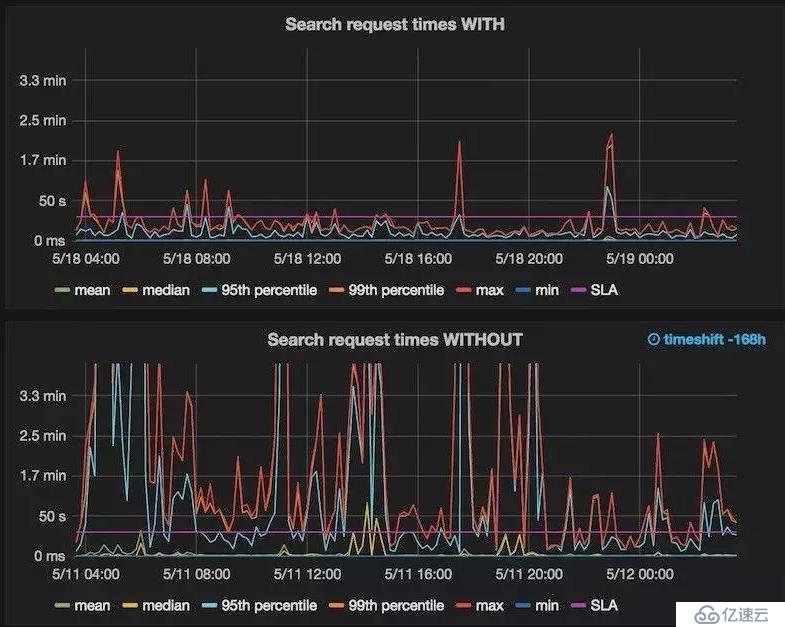
圖表說明:響應時間。有/沒有 重寫 Lucene 查詢執行。同時也表明不再有節點每天多次發生內存不足。
順便說明下,因為我知道會面臨一個問題:從上一次性能測試我們知道通過升級到 ES 2.X 能小幅提升性能,但是并不能改變什么。話雖如此,但如果你已經從 ES 1.X 集群遷移到了 ES 2.X,我們很樂意聽取關于你如何完成遷移的實踐經驗。
如果讀到了這里,說明你對 Elasticsearch 是真愛啊(或者至少你是真的需要它)。我們很樂意學習你的經驗,以及任何可以分享的內容。歡迎在評論區分享你的反饋和問題。
英文原文鏈接:http://underthehood.meltwater.com/blog/2018/02/06/running-a-400+-node-es-cluster/
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





