溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“如何用Python爬蟲實現模擬知乎登錄”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
Cookie 的原理非常簡單,因為 HTTP 是一種無狀態的協議,因此為了在無狀態的 HTTP 協議之上維護會話(session)狀態,讓服務器知道當前是和哪個客戶在打交道,Cookie 技術出現了 ,Cookie 相當于是服務端分配給客戶端的一個標識。
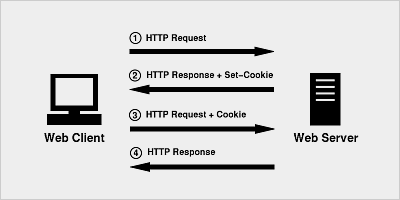
瀏覽器第一次發起 HTTP 請求時,沒有攜帶任何 Cookie 信息
服務器把 HTTP 響應,同時還有一個 Cookie 信息,一起返回給瀏覽器
瀏覽器第二次請求就把服務器返回的 Cookie 信息一起發送給服務器
服務器收到HTTP請求,發現請求頭中有Cookie字段, 便知道之前就和這個用戶打過交道了。
用過知乎的都知道,只要提供用戶名和密碼以及驗證碼之后即可登錄。當然,這只是我們眼中看到的現象。而背后隱藏的技術細節就需要借助瀏覽器來挖掘了。現在我們就用 Chrome 來查看當我們填完表單后,究竟發生了什么?
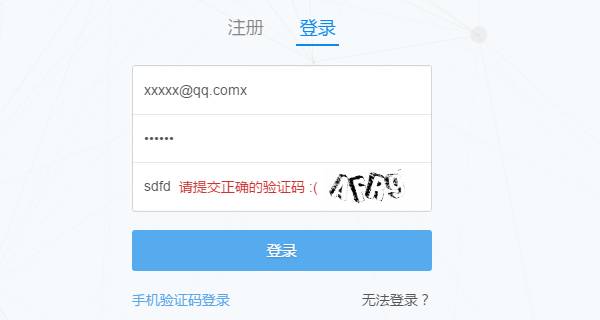
(如果已經登錄的,先退出)首先進入知乎的登錄頁面 https://www.zhihu.com/#signin ,打開 Chrome 的開發者工具條(按 F12)先嘗試輸入一個錯誤的驗證碼觀察瀏覽器是如何發送請求的。

從瀏覽器的請求可以發現幾個關鍵的信息
登錄的 URL 地址是 https://www.zhihu.com/login/email
登錄需要提供的表單數據有4個:用戶名(email)、密碼(password)、驗證碼(captcha)、_xsrf。
獲取驗證碼的URL地址是 https://www.zhihu.com/captcha.gif?r=1490690391695&type=login
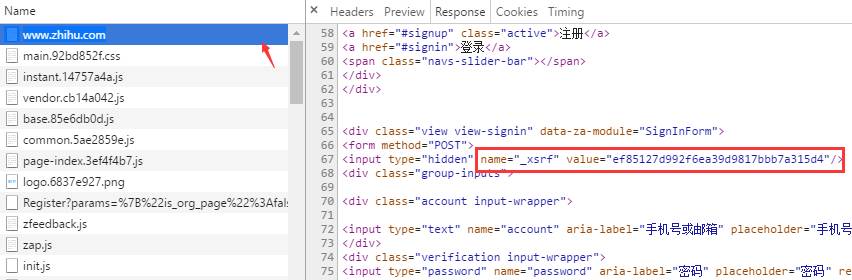
_xsrf 是什么?如果你對CSRF(跨站請求偽造)攻擊非常熟悉的話,那么你一定知道它的作用,xsrf是一串偽隨機數,它是用于防止跨站請求偽造的。它一般存在網頁的 form 表單標簽中,為了證實這一點,可以在頁面上搜索 “xsrf”,果然,_xsrf在一個隱藏的 input 標簽中
摸清了瀏覽器登錄時所需要的數據是如何獲取之后,那么現在就可以開始寫代碼用 Python 模擬瀏覽器來登錄了。登錄時所依賴的兩個第三方庫是 requests 和 BeautifulSoup,先安裝
pip install beautifulsoup4==4.5.3
pip install requests==2.13.0http.cookiejar 模塊可用于自動處理HTTP Cookie,LWPCookieJar 對象就是對 cookies 的封裝,它支持把 cookies 保存到文件以及從文件中加載。
而 session 對象 提供了 Cookie 的持久化,連接池功能,可以通過 session 對象發送請求
首先從cookies.txt 文件中加載 cookie信息,因為首次運行還沒有cookie,所有會出現 LoadError 異常。
from http import cookiejar
session = requests.session()
session.cookies = cookiejar.LWPCookieJar(filename='cookies.txt')
try:
session.cookies.load(ignore_discard=True)
except LoadError:
print("load cookies failed")前面已經找到了 xsrf 所在的標簽,,利用 BeatifulSoup 的 find 方法可以非常便捷的獲取該值
def get_xsrf():
response = session.get("https://www.zhihu.com", headers=headers)
soup = BeautifulSoup(response.content, "html.parser")
xsrf = soup.find('input', attrs={"name": "_xsrf"}).get("value")
return xsrf驗證碼是通過 /captcha.gif 接口返回的,這里我們把驗證碼圖片下載保存到當前目錄,由人工識別,當然你可以用第三方支持庫來自動識別,比如 pytesser。
def get_captcha():
"""
把驗證碼圖片保存到當前目錄,手動識別驗證碼
:return:
"""
t = str(int(time.time() * 1000))
captcha_url = 'https://www.zhihu.com/captcha.gif?r=' + t + "&type=login"
r = session.get(captcha_url, headers=headers)
with open('captcha.jpg', 'wb') as f:
f.write(r.content)
captcha = input("驗證碼:")
return captcha一切參數準備就緒之后,就可以請求登錄接口了。
def login(email, password):
login_url = 'https://www.zhihu.com/login/email'
data = {
'email': email,
'password': password,
'_xsrf': get_xsrf(),
"captcha": get_captcha(),
'remember_me': 'true'}
response = session.post(login_url, data=data, headers=headers)
login_code = response.json()
print(login_code['msg'])
for i in session.cookies:
print(i)
session.cookies.save()請求成功后,session 會自動把服務端的返回的cookie 信息填充到 session.cookies 對象中,下次請求時,客戶端就可以自動攜帶這些cookie去訪問那些需要登錄的頁面了。
“如何用Python爬蟲實現模擬知乎登錄”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





