溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何使用spark-sql-perf,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
刀片機:1臺 126G內存 64核心 centos 7.2
virtualbox安裝四臺虛擬機(centos 7.2,16G內存,4核):master,worker1,worker2,worker3(centos下)
spark版本:2.0
hadoop版本:2.6
安裝請參考:hadoop安裝或者Spark On Yarn安裝
安裝后的截圖
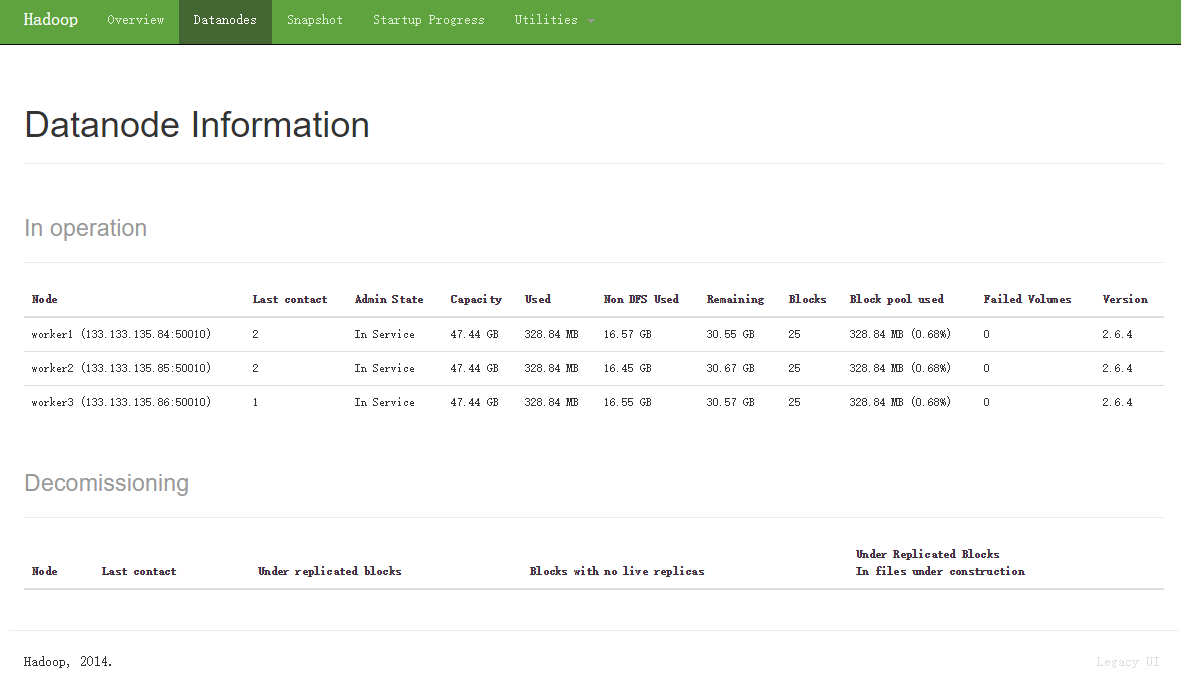
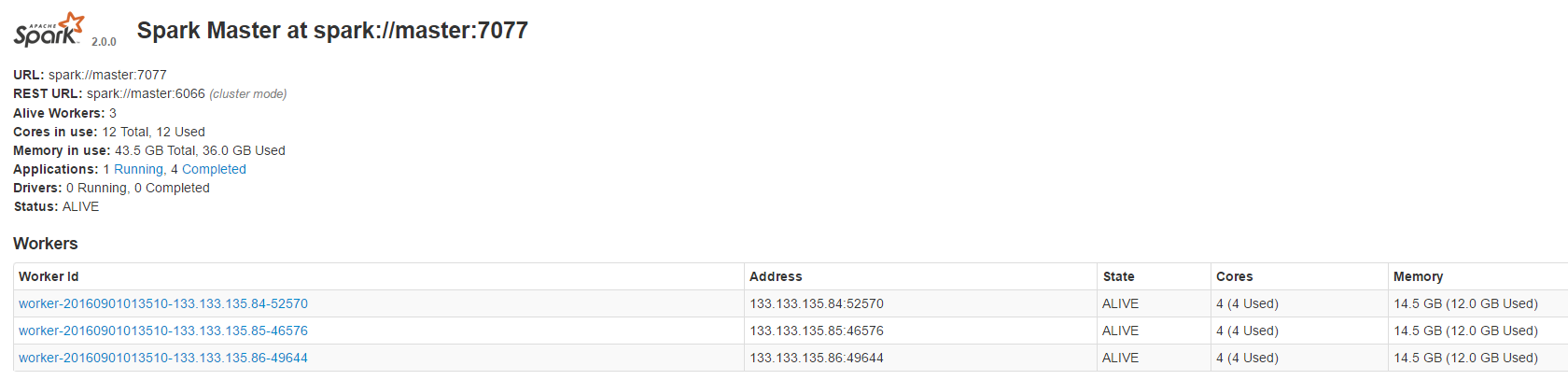
davies/tpcds-kit是用來生成測試數據的工具
git clone https://github.com/davies/tpcds-kit.git
任選一臺機器(這里我們選擇master)安裝以下編譯工具(默認軟件里沒有編譯工具)
yum install gcc gcc-c++ bison flex cmake ncurses-devel cd tpcds-kit/tools cp Makefile.suite Makefile #復制Makefile.suite為Makefile make #運行make命令
接下來,拷貝tpcds-kit到所有機器的相同目錄下(重要)
scp -r /目錄/tpcds-kit root@worker1:/目錄/tpcds-kit #執行三次該命令復制到worker1,worker2,worker3
git clone https://github.com/databricks/spark-sql-perf.git
使用sbt package打包的jar在使用時會出現依賴找不到情況,我們使用Intellij Idea導入該工程
修改sbt.build,更改scala版本為2.11.8 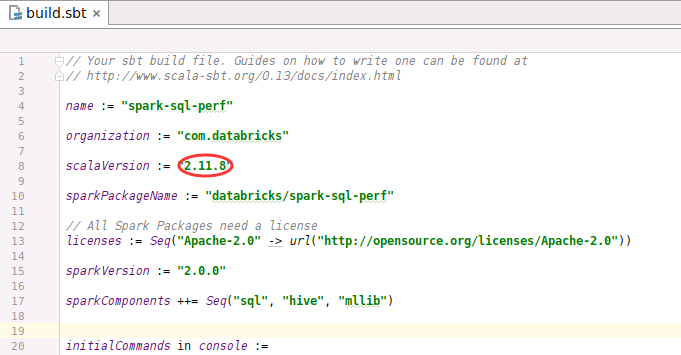
打包成jar包
設置Project Structure
設置Artifacts
Build

jar包不需要每個節點都有
SPARK_DRIVER_MEMORY=8G #依具體情況而定
cd spark-2.0.0-bin-hadoop2.6 ./bin/spark-shell --jars /jar包目錄/spark-sql-perf.jar --num-executors 20 --executor-cores 2 --executor-memory 8G --master spark://master:7077
// 創建sqlContext
val sqlContext=new org.apache.spark.sql.SQLContext(sc)
import sqlContext.implicits._
// 生成數據 參數1:sqlContext 參數2:tpcds-kit目錄 參數3:生成的數據量(GB)
val tables=new Tables(sqlCotext,"/目錄/tpcds-kit/tools",1)
tables.genData("hdfs://master:8020:tpctest","parquet",true,false,false,false,false);
// 創建表結構(外部表或者臨時表)
// talbles.createExternalTables("hdfs://master:8020:tpctest","parquet","mytest",false)
talbles.createTemporaryTables("hdfs://master:8020:tpctest","parquet")
import com.databricks.spark.sql.perf.tpcds.TPCDS
val tpcds=new TPCDS(sqlContext=sqlContext)
//運行測試
val experiment=tpcds.runExperiment(tpcds.tpcds1_4Queries)在spark-shell中我們可以調用 _experiment.html_查看執行狀態
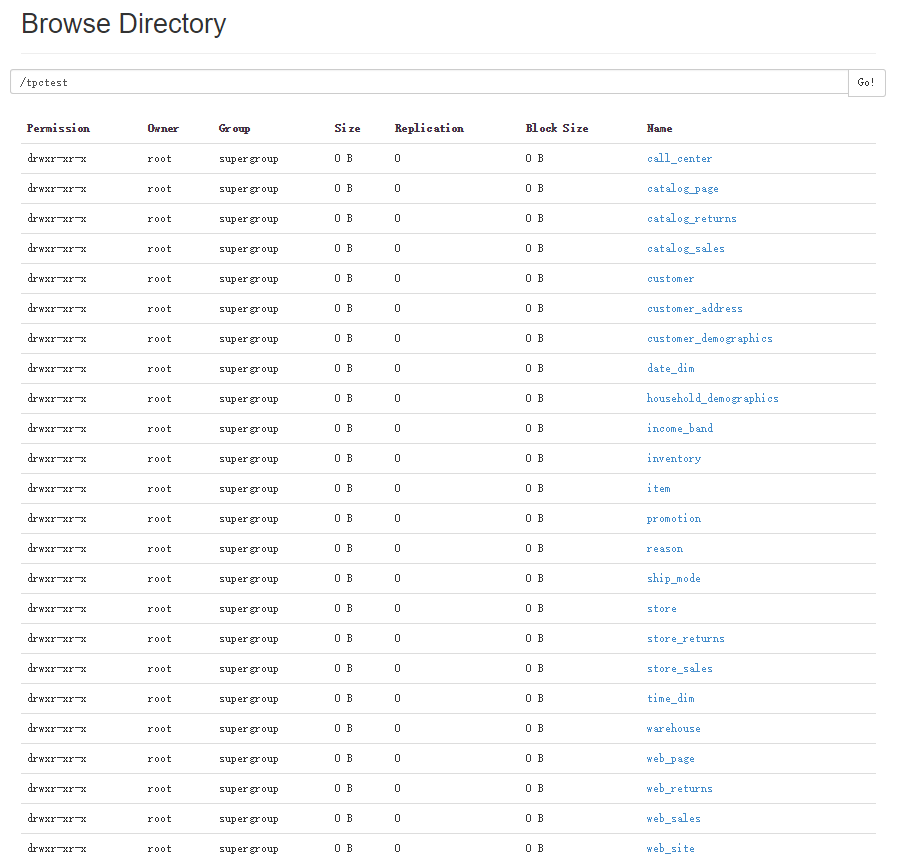
HDFS上生成的數據截圖
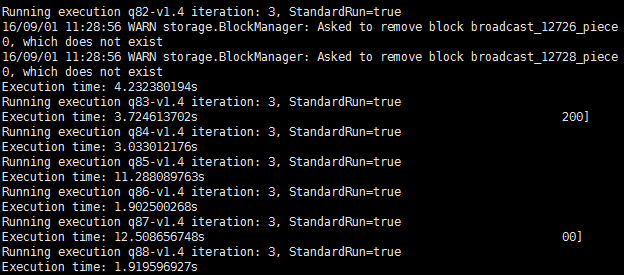
運行截圖
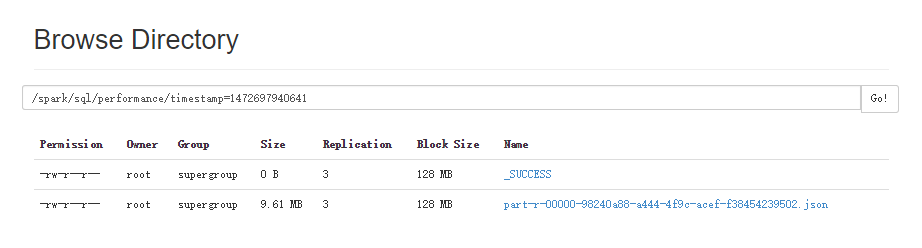
運行結果保存在spark/performance目錄下
HDFS上的評測結果截圖
關于如何使用spark-sql-perf問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





