溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關機器學習使用場景有哪些,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
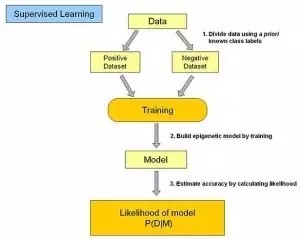
在監督式學習下,輸入數據被稱為“訓練數據”,每組訓練數據有一個明確的標識或結果,如對防垃圾郵件系統中“垃圾郵件”“非垃圾郵件”,對手寫數字識別中的“1“,”2“,”3“,”4“等。在建立預測模型的時候,監督式學習建立一個學習過程,將預測結果與“訓練數據”的實際結果進行比較,不斷的調整預測模型,直到模型的預測結果達到一個預期的準確率。監督式學習的常見應用場景如分類問題和回歸問題。常見算法有邏輯回歸(Logistic Regression)和反向傳遞神經網絡(Back Propagation Neural Network)。
在非監督式學習中,數據并不被特別標識,學習模型是為了推斷出數據的一些內在結構。非監督學習模型是用來從原始數據(無訓練數據)中找到隱藏的模式或者關系,因而非監督學習模型是基于未標記數據集的.常見的應用場景包括關聯規則的學習以及聚類等。常見算法包括Apriori算法以及k-Means算法。例子: 社交網絡,語言預測
在此學習方式下,輸入數據部分被標識,部分沒有被標識,這種學習模型可以用來進行預測,但是模型首先需要學習數據的內在結構以便合理的組織數據來進行預測。應用場景包括分類和回歸,算法包括一些對常用監督式學習算法的延伸,這些算法首先試圖對未標識數據進行建模,在此基礎上再對標識的數據進行預測。如圖論推理算法(Graph Inference)或者拉普拉斯支持向量機(Laplacian SVM.)等。例子:圖像分類、語音識別
在這種學習模式下,輸入數據作為對模型的反饋,不像監督模型那樣,輸入數據僅僅是作為一個檢查模型對錯的方式,在強化學習下,輸入數據直接反饋到模型,模型必須對此立刻作出調整。強化學習模型通過不同的行為來尋找目標回報函數最大化。常見的應用場景包括動態系統以及機器人控制,人工智能 AI等。常見算法包括Q-Learning以及時間差學習(Temporal difference learning)。
在企業數據應用的場景下, 人們最常用的可能就是監督式學習和非監督式學習的模型。 在圖像識別等領域,由于存在大量的非標識的數據和少量的可標識數據, 目前半監督式學習是一個很熱的話題。 而強化學習更多的應用在機器人控制及其他需要進行系統控制的領域。
根據算法的功能和形式的類似性,我們可以把算法分類,比如說基于樹的算法,基于神經網絡的算法等等。當然,機器學習的范圍非常龐大,有些算法很難明確歸類到某一類。而對于有些分類來說,同一分類的算法可以針對不同類型的問題。這里,我們盡量把常用的算法按照最容易理解的方式進行分類。
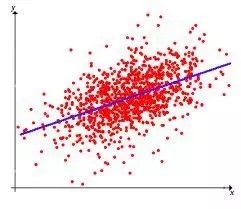
回歸算法是試圖采用對誤差的衡量來探索變量之間的關系的一類算法。回歸算法是統計機器學習的利器。在機器學習領域,人們說起回歸,有時候是指一類問題,有時候是指一類算法,這一點常常會使初學者有所困惑。常見的回歸算法包括:最小二乘法(Ordinary Least Square),邏輯回歸(Logistic Regression),逐步式回歸(Stepwise Regression),多元自適應回歸樣條(Multivariate Adaptive Regression Splines)以及本地散點平滑估計(Locally Estimated Scatterplot Smoothing)。
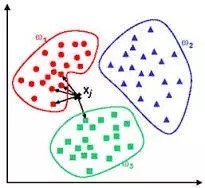
基于實例的算法常常用來對決策問題建立模型,這樣的模型常常先選取一批樣本數據,然后根據某些近似性把新數據與樣本數據進行比較。通過這種方式來尋找最佳的匹配。因此,基于實例的算法常常也被稱為“贏家通吃”學習或者“基于記憶的學習”。常見的算法包括 k-Nearest Neighbor(KNN), 學習矢量量化(Learning Vector Quantization, LVQ),以及自組織映射算法(Self-Organizing Map , SOM)
正則化方法是其他算法(通常是回歸算法)的延伸,根據算法的復雜度對算法進行調整。正則化方法通常對簡單模型予以獎勵而對復雜算法予以懲罰。常見的算法包括:Ridge Regression, Least Absolute Shrinkage and Selection Operator(LASSO),以及彈性網絡(Elastic Net)。
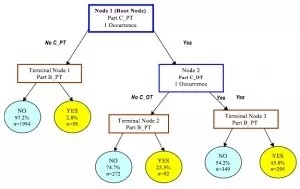
決策樹算法根據數據的屬性采用樹狀結構建立決策模型, 決策樹模型常常用來解決分類和回歸問題。常見的算法包括:分類及回歸樹(Classification And Regression Tree, CART), ID3 (Iterative Dichotomiser 3), C4.5, Chi-squared Automatic Interaction Detection(CHAID), Decision Stump, 隨機森林(Random Forest), 多元自適應回歸樣條(MARS)以及梯度推進機(Gradient Boosting Machine, GBM)
貝葉斯方法算法是基于貝葉斯定理的一類算法,主要用來解決分類和回歸問題。常見算法包括:樸素貝葉斯算法,平均單依賴估計(Averaged One-Dependence Estimators, AODE),以及Bayesian Belief Network(BBN)。
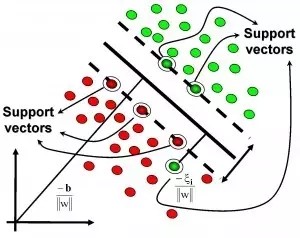
基于核的算法中最著名的莫過于支持向量機(SVM)了。 基于核的算法把輸入數據映射到一個高階的向量空間, 在這些高階向量空間里, 有些分類或者回歸問題能夠更容易的解決。 常見的基于核的算法包括:支持向量機(Support Vector Machine, SVM), 徑向基函數(Radial Basis Function ,RBF), 以及線性判別分析(Linear Discriminate Analysis ,LDA)等
聚類,就像回歸一樣,有時候人們描述的是一類問題,有時候描述的是一類算法。聚類算法通常按照中心點或者分層的方式對輸入數據進行歸并。所以的聚類算法都試圖找到數據的內在結構,以便按照最大的共同點將數據進行歸類。常見的聚類算法包括 k-Means算法以及期望最大化算法(Expectation Maximization, EM)。
關聯規則學習通過尋找最能夠解釋數據變量之間關系的規則,來找出大量多元數據集中有用的關聯規則。常見算法包括 Apriori算法和Eclat算法等。
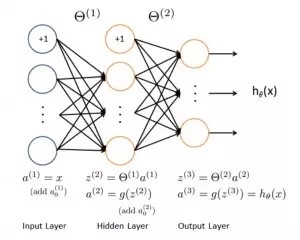
人工神經網絡算法模擬生物神經網絡,是一類模式匹配算法。通常用于解決分類和回歸問題。人工神經網絡是機器學習的一個龐大的分支,有幾百種不同的算法。(其中深度學習就是其中的一類算法,我們會單獨討論),重要的人工神經網絡算法包括:感知器神經網絡(Perceptron Neural Network), 反向傳遞(Back Propagation), Hopfield網絡,自組織映射(Self-Organizing Map, SOM)。學習矢量量化(Learning Vector Quantization, LVQ)
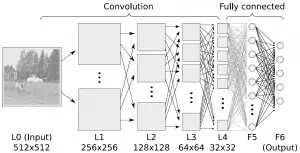
深度學習算法是對人工神經網絡的發展。 在近期贏得了很多關注, 特別是百度也開始發力深度學習后, 更是在國內引起了很多關注。 在計算能力變得日益廉價的今天,深度學習試圖建立大得多也復雜得多的神經網絡。很多深度學習的算法是半監督式學習算法,用來處理存在少量未標識數據的大數據集。常見的深度學習算法包括:受限波爾茲曼機(Restricted Boltzmann Machine, RBN), Deep Belief Networks(DBN),卷積網絡(Convolutional Network), 堆棧式自動編碼器(Stacked Auto-encoders)。
像聚類算法一樣,降低維度算法試圖分析數據的內在結構,不過降低維度算法是以非監督學習的方式試圖利用較少的信息來歸納或者解釋數據。這類算法可以用于高維數據的可視化或者用來簡化數據以便監督式學習使用。常見的算法包括:主成份分析(Principle Component Analysis, PCA),偏最小二乘回歸(Partial Least Square Regression,PLS), Sammon映射,多維尺度(Multi-Dimensional Scaling, MDS), 投影追蹤(Projection Pursuit)等。
集成算法用一些相對較弱的學習模型獨立地就同樣的樣本進行訓練,然后把結果整合起來進行整體預測。集成算法的主要難點在于究竟集成哪些獨立的較弱的學習模型以及如何把學習結果整合起來。這是一類非常強大的算法,同時也非常流行。常見的算法包括:Boosting, Bootstrapped Aggregation(Bagging), AdaBoost,堆疊泛化(Stacked Generalization, Blending),梯度推進機(Gradient Boosting Machine, GBM),隨機森林(Random Forest)。
機器學習算法太多了,分類、回歸、聚類、推薦、圖像識別領域等等,要想找到一個合適算法真的不容易,所以在實際應用中,我們一般都是采用啟發式學習方式來實驗。
通常最開始我們都會選擇大家普遍認同的算法,諸如SVM,GBDT,Adaboost,現在深度學習很火熱,神經網絡也是一個不錯的選擇。
假如你在乎精度(accuracy)的話,最好的方法就是通過交叉驗證(cross-validation)對各個算法一個個地進行測試,進行比較,然后調整參數確保每個算法達到最優解,最后選擇最好的一個。
但是如果你只是在尋找一個“足夠好”的算法來解決你的問題,或者這里有些技巧可以參考,下面來分析下各個算法的優缺點,基于算法的優缺點,更易于我們去選擇它。
在統計學中,一個模型好壞,是根據偏差和方差來衡量的,所以我們先來普及一下偏差和方差:
偏差:描述的是預測值(估計值)的期望E’與真實值Y之間的差距。偏差越大,越偏離真實數據。
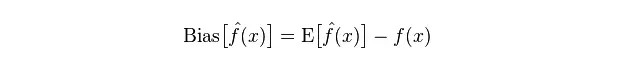
方差:描述的是預測值P的變化范圍,離散程度,是預測值的方差,也就是離其期望值E的距離。方差越大,數據的分布越分散。
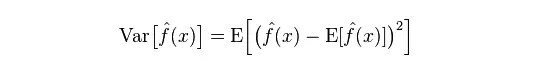
模型的真實誤差是兩者之和,如下圖: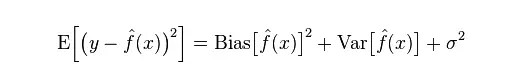
如果是小訓練集,高偏差/低方差的分類器(例如,樸素貝葉斯NB)要比低偏差/高方差大分類的優勢大(例如,KNN),因為后者會過擬合。
但是,隨著你訓練集的增長,模型對于原數據的預測能力就越好,偏差就會降低,此時低偏差/高方差分類器就會漸漸的表現其優勢(因為它們有較低的漸近誤差),此時高偏差分類器此時已經不足以提供準確的模型了。
當然,你也可以認為這是生成模型(NB)與判別模型(KNN)的一個區別。
首先,假設你知道訓練集和測試集的關系。簡單來講是我們要在訓練集上學習一個模型,然后拿到測試集去用,效果好不好要根據測試集的錯誤率來衡量。
但很多時候,我們只能假設測試集和訓練集的是符合同一個數據分布的,但卻拿不到真正的測試數據。這時候怎么在只看到訓練錯誤率的情況下,去衡量測試錯誤率呢?
由于訓練樣本很少(至少不足夠多),所以通過訓練集得到的模型,總不是真正正確的。(就算在訓練集上正確率100%,也不能說明它刻畫了真實的數據分布,要知道刻畫真實的數據分布才是我們的目的,而不是只刻畫訓練集的有限的數據點)。
而且,實際中,訓練樣本往往還有一定的噪音誤差,所以如果太追求在訓練集上的完美而采用一個很復雜的模型,會使得模型把訓練集里面的誤差都當成了真實的數據分布特征,從而得到錯誤的數據分布估計。
這樣的話,到了真正的測試集上就錯的一塌糊涂了(這種現象叫過擬合)。但是也不能用太簡單的模型,否則在數據分布比較復雜的時候,模型就不足以刻畫數據分布了(體現為連在訓練集上的錯誤率都很高,這種現象較欠擬合)。
過擬合表明采用的模型比真實的數據分布更復雜,而欠擬合表示采用的模型比真實的數據分布要簡單。
在統計學習框架下,大家刻畫模型復雜度的時候,有這么個觀點,認為Error = Bias + Variance。這里的Error大概可以理解為模型的預測錯誤率,是有兩部分組成的,一部分是由于模型太簡單而帶來的估計不準確的部分(Bias),另一部分是由于模型太復雜而帶來的更大的變化空間和不確定性(Variance)。
所以,這樣就容易分析樸素貝葉斯了。它簡單的假設了各個數據之間是無關的,是一個被嚴重簡化了的模型。所以,對于這樣一個簡單模型,大部分場合都會Bias部分大于Variance部分,也就是說高偏差而低方差。
在實際中,為了讓Error盡量小,我們在選擇模型的時候需要平衡Bias和Variance所占的比例,也就是平衡over-fitting和under-fitting。
偏差和方差與模型復雜度的關系使用下圖更加明了:
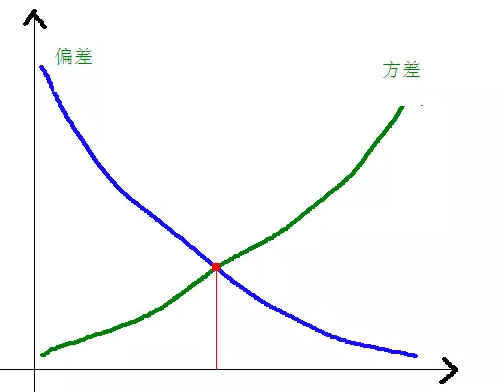
當模型復雜度上升的時候,偏差會逐漸變小,而方差會逐漸變大。
樸素貝葉斯屬于生成式模型(關于生成模型和判別式模型,主要還是在于是否是要求聯合分布),非常簡單,你只是做了一堆計數。
如果注有條件獨立性假設(一個比較嚴格的條件),樸素貝葉斯分類器的收斂速度將快于判別模型,如邏輯回歸,所以你只需要較少的訓練數據即可。即使NB條件獨立假設不成立,NB分類器在實踐中仍然表現的很出色。
它的主要缺點是它不能學習特征間的相互作用,用mRMR中R來講,就是特征冗余。引用一個比較經典的例子,比如,雖然你喜歡Brad Pitt和Tom Cruise的電影,但是它不能學習出你不喜歡他們在一起演的電影。
樸素貝葉斯模型發源于古典數學理論,有著堅實的數學基礎,以及穩定的分類效率。
對小規模的數據表現很好,能個處理多分類任務,適合增量式訓練;
對缺失數據不太敏感,算法也比較簡單,常用于文本分類。
需要計算先驗概率;
分類決策存在錯誤率;
對輸入數據的表達形式很敏感。
屬于判別式模型,有很多正則化模型的方法(L0, L1,L2,etc),而且你不必像在用樸素貝葉斯那樣擔心你的特征是否相關。
與決策樹與SVM機相比,你還會得到一個不錯的概率解釋,你甚至可以輕松地利用新數據來更新模型(使用在線梯度下降算法,online gradient descent)。
如果你需要一個概率架構(比如,簡單地調節分類閾值,指明不確定性,或者是要獲得置信區間),或者你希望以后將更多的訓練數據快速整合到模型中去,那么使用它吧。
Sigmoid函數:
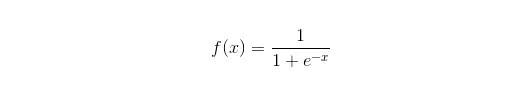
實現簡單,廣泛的應用于工業問題上;
分類時計算量非常小,速度很快,存儲資源低;
便利的觀測樣本概率分數;
對邏輯回歸而言,多重共線性并不是問題,它可以結合L2正則化來解決該問題;
當特征空間很大時,邏輯回歸的性能不是很好;
容易欠擬合,一般準確度不太高
不能很好地處理大量多類特征或變量;
只能處理兩分類問題(在此基礎上衍生出來的softmax可以用于多分類),且必須線性可分;
對于非線性特征,需要進行轉換;
線性回歸是用于回歸的,而不像Logistic回歸是用于分類,其基本思想是用梯度下降法對最小二乘法形式的誤差函數進行優化,當然也可以用normal equation直接求得參數的解,結果為:
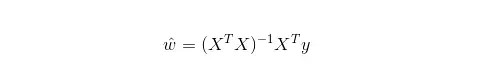
而在LWLR(局部加權線性回歸)中,參數的計算表達式為:
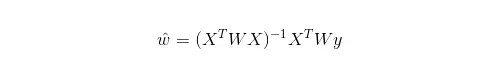
由此可見LWLR與LR不同,LWLR是一個非參數模型,因為每次進行回歸計算都要遍歷訓練樣本至少一次。
實現簡單,計算簡單
不能擬合非線性數據.
KNN即最近鄰算法,其主要過程為:
1. 計算訓練樣本和測試樣本中每個樣本點的距離(常見的距離度量有歐式距離,馬氏距離等);
2. 對上面所有的距離值進行排序;
3. 選前k個最小距離的樣本;
4. 根據這k個樣本的標簽進行投票,得到最后的分類類別;
如何選擇一個最佳的K值,這取決于數據。一般情況下,在分類時較大的K值能夠減小噪聲的影響。但會使類別之間的界限變得模糊。
一個較好的K值可通過各種啟發式技術來獲取,比如,交叉驗證。另外噪聲和非相關性特征向量的存在會使K近鄰算法的準確性減小。
近鄰算法具有較強的一致性結果。隨著數據趨于無限,算法保證錯誤率不會超過貝葉斯算法錯誤率的兩倍。對于一些好的K值,K近鄰保證錯誤率不會超過貝葉斯理論誤差率。
理論成熟,思想簡單,既可以用來做分類也可以用來做回歸;
可用于非線性分類;
訓練時間復雜度為O(n);
對數據沒有假設,準確度高,對outlier不敏感;
計算量大;
樣本不平衡問題(即有些類別的樣本數量很多,而其它樣本的數量很少);
需要大量的內存;
易于解釋。它可以毫無壓力地處理特征間的交互關系并且是非參數化的,因此你不必擔心異常值或者數據是否線性可分(舉個例子,決策樹能輕松處理好類別A在某個特征維度x的末端,類別B在中間,然后類別A又出現在特征維度x前端的情況)。
它的缺點之一就是不支持在線學習,于是在新樣本到來后,決策樹需要全部重建。
另一個缺點就是容易出現過擬合,但這也就是諸如隨機森林RF(或提升樹boosted tree)之類的集成方法的切入點。
另外,隨機森林經常是很多分類問題的贏家(通常比支持向量機好上那么一丁點),它訓練快速并且可調,同時你無須擔心要像支持向量機那樣調一大堆參數,所以在以前都一直很受歡迎。
決策樹中很重要的一點就是選擇一個屬性進行分枝,因此要注意一下信息增益的計算公式,并深入理解它。
信息熵的計算公式如下:
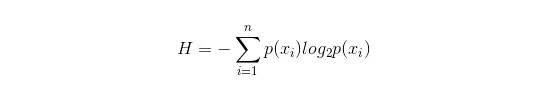
其中的n代表有n個分類類別(比如假設是2類問題,那么n=2)。分別計算這2類樣本在總樣本中出現的概率p1和p2,這樣就可以計算出未選中屬性分枝前的信息熵。
現在選中一個屬性xixi用來進行分枝,此時分枝規則是:如果xi=vxi=v的話,將樣本分到樹的一個分支;如果不相等則進入另一個分支。
很顯然,分支中的樣本很有可能包括2個類別,分別計算這2個分支的熵H1和H2,計算出分枝后的總信息熵H’ =p1 H1+p2 H2,則此時的信息增益ΔH = H - H’。以信息增益為原則,把所有的屬性都測試一邊,選擇一個使增益最大的屬性作為本次分枝屬性。
計算簡單,易于理解,可解釋性強;
比較適合處理有缺失屬性的樣本;
能夠處理不相關的特征;
在相對短的時間內能夠對大型數據源做出可行且效果良好的結果。
容易發生過擬合(隨機森林可以很大程度上減少過擬合);
忽略了數據之間的相關性;
對于那些各類別樣本數量不一致的數據,在決策樹當中,信息增益的結果偏向于那些具有更多數值的特征(只要是使用了信息增益,都有這個缺點,如RF)。
Adaboost是一種加和模型,每個模型都是基于上一次模型的錯誤率來建立的,過分關注分錯的樣本,而對正確分類的樣本減少關注度,逐次迭代之后,可以得到一個相對較好的模型。是一種典型的boosting算法。下面是總結下它的優缺點。
adaboost是一種有很高精度的分類器。
可以使用各種方法構建子分類器,Adaboost算法提供的是框架。
當使用簡單分類器時,計算出的結果是可以理解的,并且弱分類器的構造極其簡單。
簡單,不用做特征篩選。
不容易發生overfitting。
關于隨機森林和GBDT等組合算法,參考這篇文章:機器學習-組合算法總結
缺點:
對outlier比較敏感
高準確率,為避免過擬合提供了很好的理論保證,而且就算數據在原特征空間線性不可分,只要給個合適的核函數,它就能運行得很好。
在動輒超高維的文本分類問題中特別受歡迎。可惜內存消耗大,難以解釋,運行和調參也有些煩人,而隨機森林卻剛好避開了這些缺點,比較實用。
可以解決高維問題,即大型特征空間;
能夠處理非線性特征的相互作用;
無需依賴整個數據;
可以提高泛化能力;
當觀測樣本很多時,效率并不是很高;
對非線性問題沒有通用解決方案,有時候很難找到一個合適的核函數;
對缺失數據敏感;
對于核的選擇也是有技巧的(libsvm中自帶了四種核函數:線性核、多項式核、RBF以及sigmoid核):
第一,如果樣本數量小于特征數,那么就沒必要選擇非線性核,簡單的使用線性核就可以了;
第二,如果樣本數量大于特征數目,這時可以使用非線性核,將樣本映射到更高維度,一般可以得到更好的結果;
第三,如果樣本數目和特征數目相等,該情況可以使用非線性核,原理和第二種一樣。
對于第一種情況,也可以先對數據進行降維,然后使用非線性核,這也是一種方法。
分類的準確度高;
并行分布處理能力強,分布存儲及學習能力強,
對噪聲神經有較強的魯棒性和容錯能力,能充分逼近復雜的非線性關系;
具備聯想記憶的功能。
神經網絡需要大量的參數,如網絡拓撲結構、權值和閾值的初始值;
不能觀察之間的學習過程,輸出結果難以解釋,會影響到結果的可信度和可接受程度;
學習時間過長,甚至可能達不到學習的目的。
關于“機器學習使用場景有哪些”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





