溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
干貨走起,閑話不多說,以下就是小編整理的大數據學習思路
第一階段:linux系統
本階段為大數據學習入門基礎課程,幫大家進入大數據領取打好Linux基礎,以便更好的學習Hadoop、habse、NoSQL、saprk、storm等眾多技術要點。
另:目前企業中無疑例外是使用Linux來搭建或部署項目的
在這里還是要推薦下我自己建的大數據學習交流群:529867072,群里都是學大數據開發的,如果你正在學習大數據 ,小編歡迎你加入,大家都是軟件開發黨,不定期分享干貨(只有大數據軟件開發相關的),包括我自己整理的一份最新的大數據進階資料和高級開發教程,歡迎進階中和進想深入大數據的小伙伴加入。
第二階段:大型網站高并發處理
本階段的學習是為了讓大家能夠了解大數據的源頭,數據從而而來,繼而更好的了解大數據。通過學習處理大型網站高并發問題反向的更加深入的學習Linux,同事站在了更高的角度去觸探架構
第三階段:Hadoop學習
1、Hadoop分布式文件系統:HDFS
詳細解剖HDFS,了解其工作原理,打好學習大數據的基礎
2、Hadoop分布式計算框架:MapReduce
MapReduce可以說是任何一家大數據公司都會用到的計算框架,也是每個大數據工程師應該熟練掌握的
3、Hadoop離線體系:Hive
hive是使用SQL盡心計算的Hadoop框架,工作中經常會使用,也是面授的重點
4、Hadoop離線計算體系:HBASE
HBASE的重要性不言而喻,即便是工作多年的大數據工程師也是需要去重點學習HBASE性能優化的
第四階段:zookeeper開發
zookeeper在分布式集群中的地位越來越突出,對分布式應用的開發也提供了極大的便利,學習zookeeper的時候,我們主要學習zookeeper的深入,客戶端開發、日常運維、web界面監控等等。學好此部分的內容對后面技術的學習也是至關重要的。
第五階段:elasticsearch分布式搜索
第六階段:CDH集群管理
第七階段:storm實時數據處理
本階段覆蓋storm內部機制和原理,掌握從數據采集到實時極端到數據存儲再到前臺展示,一人講所有的工作全部完成,知識覆蓋面廣
第八階段:Redis緩存數據庫
對Redis做個全部的學習,包括其特點、散列集合類型、字符串類型等等,最后到優化,做個詳細的學習
第九階段:spark核心部分
本階段內容覆蓋了spark生態系統的概述及其編程模型,深入內核的研究,Spark on Yarn,Spark Streaming流式計算原理與實踐,Spark SQL,Spark的多語言編程以及SparkR的原理和運行。
在了解了以上知識點后,云計算機器學習的部分也是至關重要的。通常在云計算這部分內容,我們會對Docker、虛擬化KVM、云平臺OpenStack做個了解和學習,防止在以后的工作中會遇到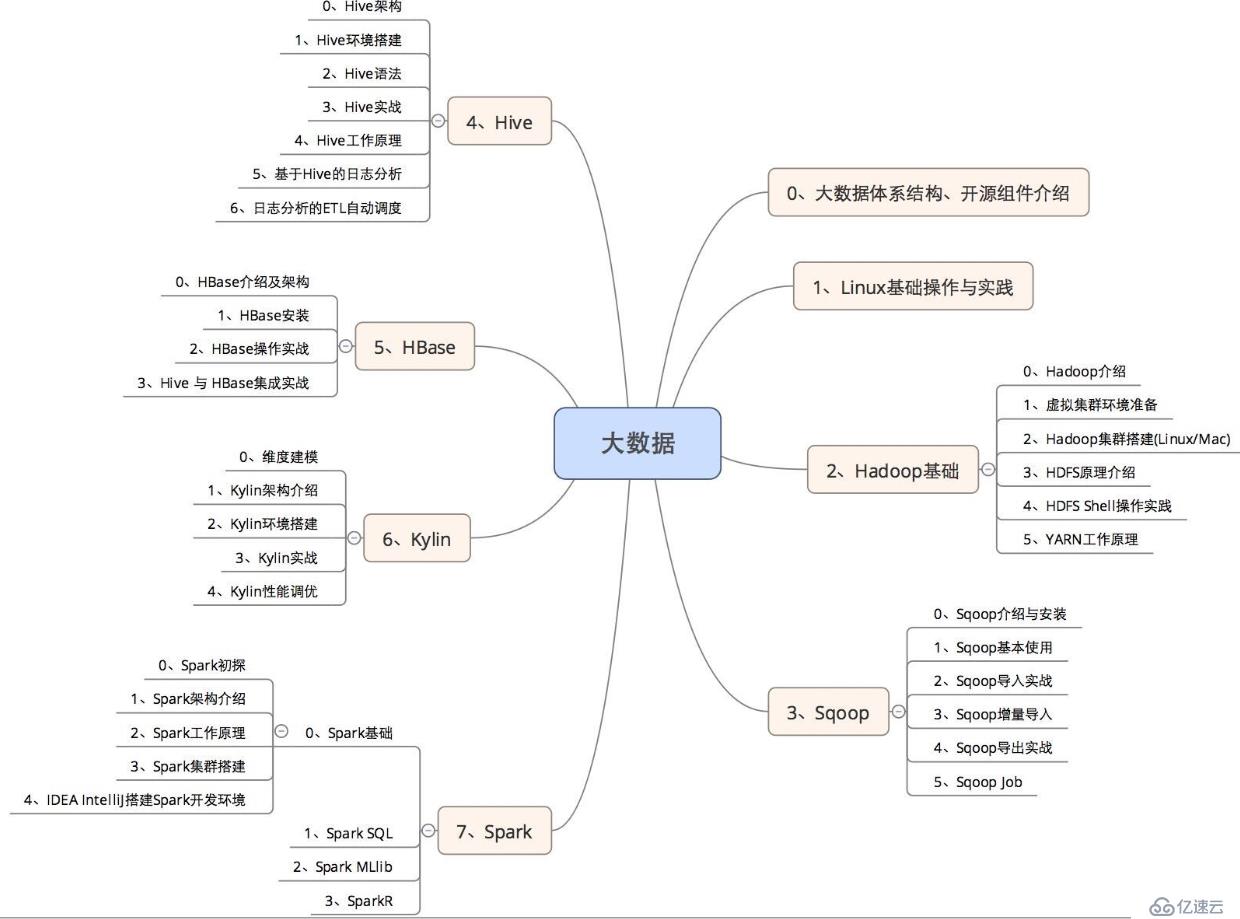
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





