溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Impala的特點有哪些”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Impala的特點有哪些”吧!
Impala 是參照google 的新三篇論文Dremel(大批量數據查詢工具)的開源實現,功能類似shark(依賴于hive)和Drill(apache),impala 是clouder 公司主導開發并開源,基于hive 并使用內存進行計算,兼顧數據倉庫,具有實時,批處理,多并發等優點。是使用cdh 的首選PB 級大數據實時查詢分析引擎。(Impala 依賴cdh 是完全沒有問題的,官網說可以單獨運行,但是他單獨運行會出現好多的問題)
Impala與Shark、sparkSQL、Drill等的簡單比較
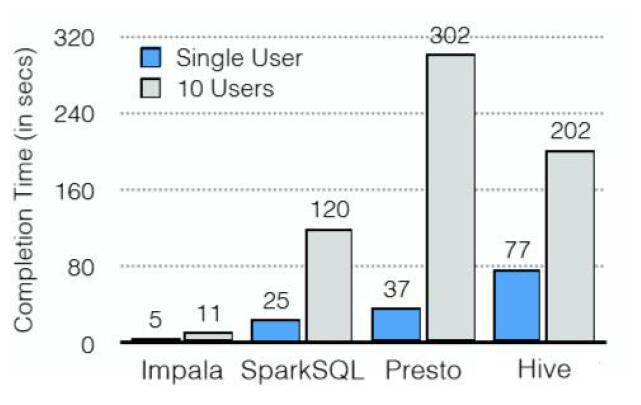
Impala起步較早,目前能夠商用的為數不多的大數據查詢引擎之一;
CDH5不支持sparkSQL;
Drill起步晚,尚不成熟;
shark功能和架構上同Impala相似,該項目已經停止開發。
Impala特點
基于內存進行計算,能夠對PB級數據進行交互式實時查詢/分析;
無需轉換為MR,直接讀取HDFS數據
C++編寫,LLVM統一編譯運行
兼容HiveSQL
具有數據倉庫的特性,可對hive數據直接做數據分析
支持Data Local
支持列式存儲
支持JDBC/ODBC遠程訪問
支持sql92標準,并具有自己的解析器和優化器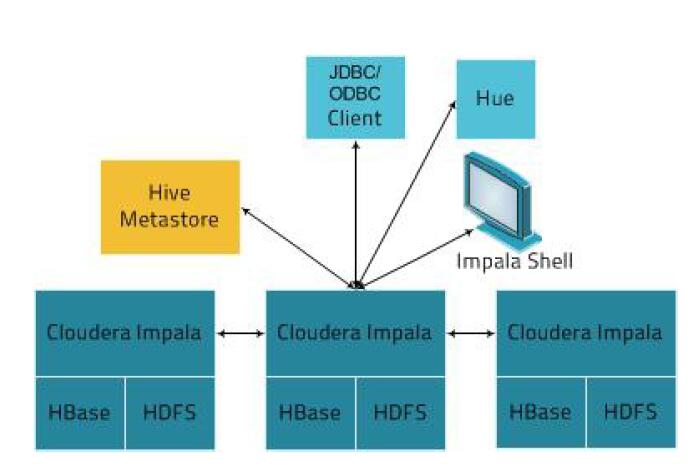
Impala核心組件
對于impala 來講,是沒有主節點的,而要理解主節點,impala statestore 和catalog server兩個角色,就具備集群調節的功能,根據以上的特點,對impala 進行配置優化配置impala 內存,每一個deamon 都需要配置內存,因為真正做查詢工作的就是deamon 所在的節點,所以impala 的總內存,就是所有deamon 節點的內存之和;如果要在哪臺機器上面匯總,就需要在那一臺機器上的內存調大一些;我們了解到的,真正提供查詢的是deamon,那么我們連接哪一臺呢?Impala,你可以連接其中deamon 任何一個都行,可以根據自己的需求來,(1)當你查詢的量相對大的時候,你就連接內存大的機器,(2)當每臺機器都適合查詢的情況下也可以隨機找一臺機器,自己寫一個輪詢或者權重算法;解決高并發問題
Statestore Daemon
負責收集分布在集群中各個impalad 進程的資源信息,各節點健康狀況、同步節點信息.
負責query 的調度.(并非絕對,倘若他存在,那就幫忙,若不存在,那就不用他)
對于一個正常運轉的集群,并不是一個關鍵進程.
Catalog Daemon(1.2 版本之后才加入)
把impala表的metadata分發到各個impalad 中,說他是基于hive 的,所以就需要metadata數據分到impalad 中,以前沒有此進程,就是手動來進行同步的。雖然之后加入了,但是也沒有那么智能,并不是保證所有的數據都能同步,比如你插入一些數據,他可以把數據發到其他節點,但是比如創建表ddl 語句,建議去手動做一下。接收來自statestore 的所有請求,當impala deamon節點插入或者查詢數據時候(數據改變的時候),他把自己的操作結果匯報給state deamon,然后state store 請求catelog deamon,告知重新更新元數據信息給impalad 中,所以catalog deamon 與statedeamon 放到一臺機器上,而且不建議在此機器上再去安裝impala deamon 進程,避免造成提供查詢造成集群管理出問題
Impala Daemon(主要來提供查詢)
主要接收查詢請求,接收client、hue、jdbc 或者odbc 請求、query 執行并返回給中心協調節點(對應的服務實例是impalad)子節點上的守護進程,負責向statestore 保持通信,匯報工作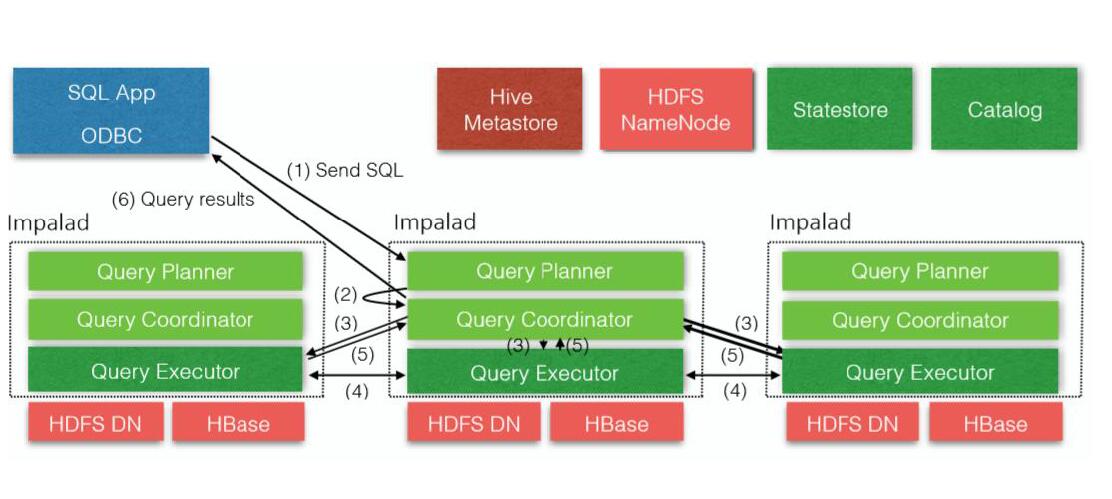
Client(shell,jdbc,odbc)發送請求到impalad 進程上,發送節點可以是隨機的,impalad 之間,也有相互通信
Statestore 和catelog 劃到同一節點,目的就是這兩個進程在協調工作時候,避免因網絡問題造成失敗
Hive metastore 是比較重要的,此時statestore 和catelog 通信,將數據同步到其他節點
Impalad 最好與hdfsDataNode 在同一節點,這樣能更快速的查詢計算,然后返回結果即可(理想狀態的就是數據本地化)
Query planner(查詢解析器)
ii. Query coordinator(中心協調節點)
Query executor(查詢執行器)
將我們的字符串sql 語句解釋成為執行計劃,
由這個組件來指定來查詢的主節點(頭),指定好之后通知其他節點我的主節點作用,待你們查詢完成之后的結果,返回給頭節點
而做查詢工作的是就是executor
Impalad 里面包含三個組件
impala 外部shell
-h(--help)幫助-------查看所有命令的幫助文檔
-r(--refresh_after_connect)刷新所有元數據(當hive 創建數據的時候,你需要刷新到,才能看到hive 元數據的改變)整體刷新*---全量刷新,萬不得已才能用;不建議定時去刷新hive 源數據,數據量太大時候,一個刷新,很有可能會掛掉;創建hive 表,然后刷新。
-B(--delimited)去格式化輸出* 大量數據加入格式化,性能受到影響
--output_delimiter=character 指定分隔符與其他命令整合
--print_header 打印列名(去格式化,但是顯示列名字)
-v 查看對應版本(會有坑)
Impala 的查詢會以最新版本為準,如果版本不一致,會造成查詢結果失敗
mpala-shell 與impala 的版本查看,必須版本一致
-f 執行查詢文件*
select name,count(name) as name_count from person group by name--創建包含該sql的文件
--query_file 指定查詢文件(建議sql 語句寫到一行,因為shell 會讀取文件一行一行的命令)
Impala-shell --query_file=xxx
-i 連接到對應的impalad
--impalad 指定impalad 去執行任務
--fe_port 指定備用端口(通常不用去指定)
-o 保存執行結果到文件***
--output_file 指定輸出文件名
組合應用:
impala-shell -B --Print_header -f test.sss -o result.txt Impala-shell -B -f test.xxx -o result.txt
非重要的shell
Impala-shell --user root
Impala-shell -d database(database 指定數據庫名稱)
--quiet 不顯示多余信息
impala-shell -q "select * from impala.rstest limit 5">
--user 指定用戶執行shell 命令
--ssl 通過ssl 驗證方式方式執行
--ca_cert 指定第三方用戶證書
--config_file 臨時指定配置文件
-u 執行某一用戶運行impala-shell
-p 顯示執行計劃
-q 不進入impala-shell 執行查詢
-c 忽略錯誤語句繼續執行
-d 指定進入某一個數據庫
mpala-shell 命令用法:
Impala-shell(內部shell)
幫助選項
help
連接到某個impalad 實例
connect <hostname>
刷新某個表元數據
*refresh <tablename> //屬于增量刷新
刷新元數據庫
*invalidate metadata //全量刷新,性能消耗較大
顯示一個查詢的執行計劃及各步驟信息
*explain <sql> //可以設置set explain_level 四個級別0開始,一般用2級別即可,查看執行計劃等詳細信息
不退出impala-shell 執行操作系統命令
shell <shell>
shell ls
顯示查詢底層信息(底層執行計劃,用于性能優化)
*profile //在查詢完成之后執行
執行計劃存儲下來分析
impala-shell -q "select name from person" -p >> impalalog.123
查看StateStore(監控管理)
– http://cdh2:25020/
查看Catalog(監控管理)
– http://cdh3:25010/
Impala 存儲與分區
需要注意的是impala 除了全部支持hive 的文件類型,自己還支持parquet 這樣的文件類型,當然了,這個類型并不是impala 自己獨有的,比如spark sql,shark sql 都支持這樣的類型;Rcfile 本身快一些,但是不如text 才做起來更方便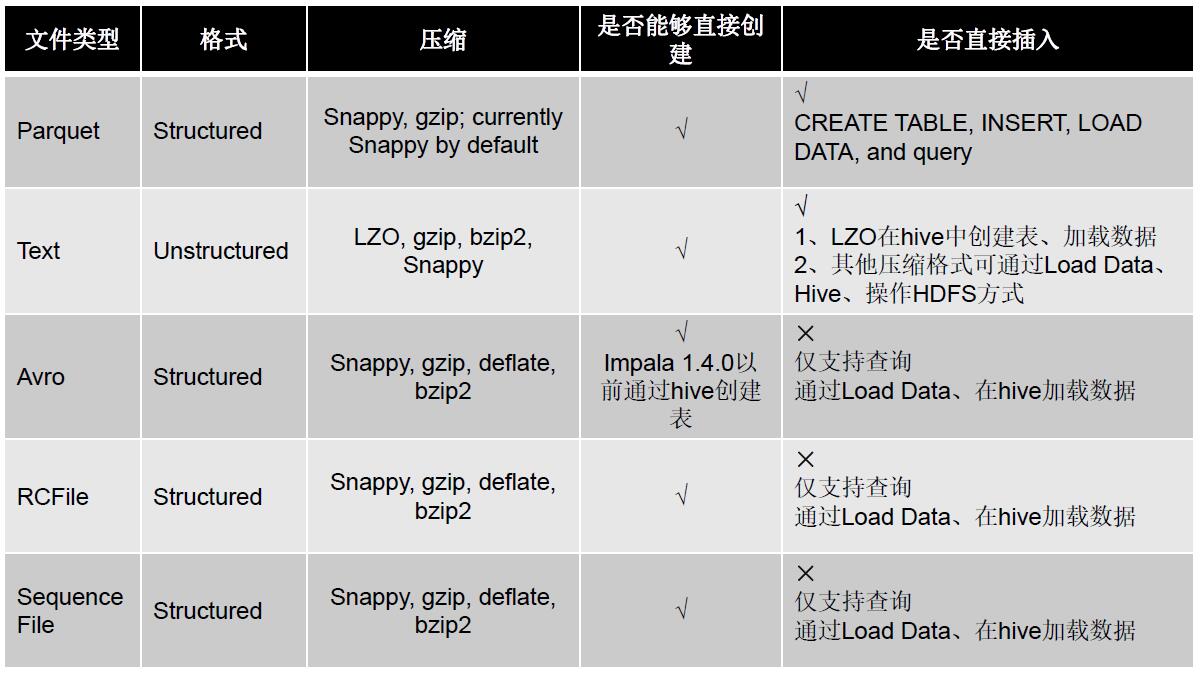
壓縮方式
添加分區方式
--1、partitioned by 創建表時,添加該字段指定分區列表 --2、使用alter table 進行分區的添加和刪除操作 ? create table t_person(id int, name string, age int) partitioned by (type string); ? alter table t_person add partition (type='man'); ? alter table t_person drop partition (type='man'); ? alter table t_person drop partition (sex='man',type='boss');
分區內添加數據
insert into t_person partition (type='boss') values (1,'zhangsan',18),(2,'lisi',23) insert into t_person partition (type='coder') values (3,'wangwu',22),(4,'zhaoliu’,28),(5,'tianqi',24)
查詢指定分區數據
select id,name from t_person where type='coder'
impala-SQL、JDBC、性能優化
加載數據:
insert 語句:插入數據時每條數據產生一個數據文件,不建議用此方式加載批量數據
load data 方式:在進行批量插入時使用這種方式比較合適
來自中間表:此種方式使用于從一個小文件較多的大表中讀取文件并寫入新的表生產少量的數據文件。也可以通過此種方式進行格式轉換。
空值處理:
impala 將“\n”表示為NULL,在結合sqoop 使用是注意做相應的空字段過濾,也可以使用以下方式進行處理:
alter table name set tblproperties (“serialization.null.format”=“null”)
配置:
– impala.driver=org.apache.hive.jdbc.HiveDriver – impala.url=jdbc:hive2://node2:21050/;auth=noSasl – impala.username= – impala.password=
盡量使用PreparedStatement執行SQL語句:
性能上PreparedStatement要好于Statement
Statement存在查詢不出數據的情況
執行計劃
– 查詢sql執行之前,先對該sql做一個分析,列出需要完成這一項查詢的
詳細方案(命令:explain sql、profile)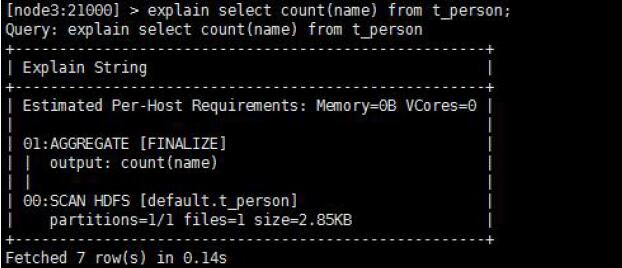
總結:
1、SQL優化,使用之前調用執行計劃
2、選擇合適的文件格式進行存儲
3、避免產生很多小文件(如果有其他程序產生的小文件,可以使用中間
表)
4、使用合適的分區技術,根據分區粒度測算
5、使用compute stats進行表信息搜集
6、網絡io的優化:
a.避免把整個數據發送到客戶端
b.盡可能的做條件過濾
c.使用limit字句
d.輸出文件時,避免使用美化輸出
7、使用profile輸出底層信息計劃,在做相應環境優化
Impala SQL VS HiveQL
支持數據類型
INT
TINYINT
SMALLINT
BIGINT
BOOLEAN
CHAR
VARCHAR
STRING
FLOAT
DOUBLE
REAL
DECIMAL
TIMESTAMP
CDH5.5版本以后才支持一下類型
ARRAY
MAP
STRUCT
Complex
此外,Impala不支持HiveQL以下特性:
covar_pop, covar_samp, corr, percentile,percentile_approx, histogram_numeric, collect_set
Impala僅支持:AVG,COUNT,MAX,MIN,SUM
– 多Distinct查詢
– HDF、UDAF
– 可擴展機制,例如:TRANSFORM、自定義文件格式、自定義SerDes
– XML、JSON函數
– 某些聚合函數:
Impala SQL(和Hive類似)
視圖
不能向impala的視圖進行插入操作
insert 表可以來自視圖
– 創建視圖:create view v1 as select count(id) as total from tab_3 ;
– 查詢視圖:select * from v1;
– 查看視圖定義:describe formatted v1
到此,相信大家對“Impala的特點有哪些”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





