溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“spark2.0集群環境的安裝步驟”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
spark2.0已經在apache的官網進行公布。大家可以去下載。今天我就帶大家進行安裝spark2.0
.spark2.0要求是hadoop2.7.2 +scala2.11+java7 版本不夠的請先升級
1.安裝hadoop2.7.2
下載地址是:http://hadoop.apache.org/releases.html
下載好后進行解壓 tar -zxvf
我在這里用的是偽分布虛擬機的配置
如果對hadoop不熟悉的同學可以參考http://www.linuxidc.com/Linux/2016-02/128729.htm?1456669335754進行安裝
提示:對于hadoop測試不要只用jps看進程,這是不準確的。正確的操作是通過頁面訪問50070和8088端口
2.安裝scala2.11
下載地址是http://www.scala-lang.org/download/
下載后進行解壓
配置環境變量 vi /etc/profile
這些操作簡單。估計大家都會。我再這里不詳細描述 不了解的可以去百度
對于scala的測試是scala -version
3.安裝spark2.0
下載地址是http://spark.apache.org/news/spark-2-0-0-released.html
下載后也是進行解壓tar -zxvf
解壓后開始配置
首先在/etc/profile 把spark的環境變量配上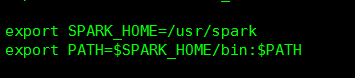
然后配置spark的conf/slaves
把slaves的主機名添加上
然后進行啟動
sbin/start-all.sh
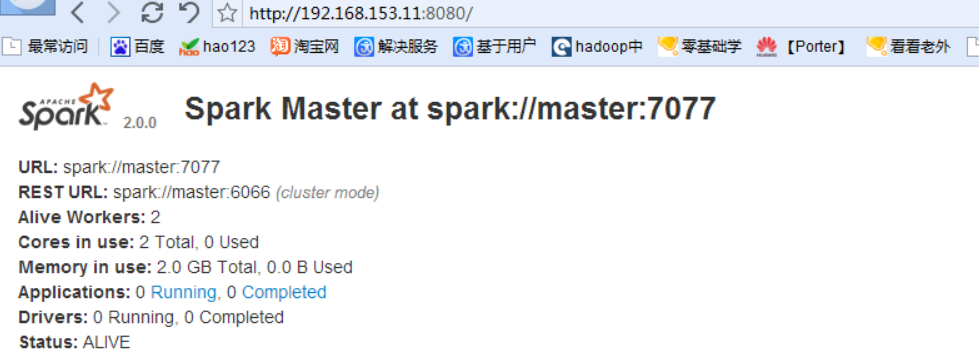
啟動成功后可以訪問上面的界面注意是master的ip,端口是8080
這樣spark環境就安裝成功
然后可以跑個demo進行測試例如
bin/run-example org.apache.spark.example.SparkPi
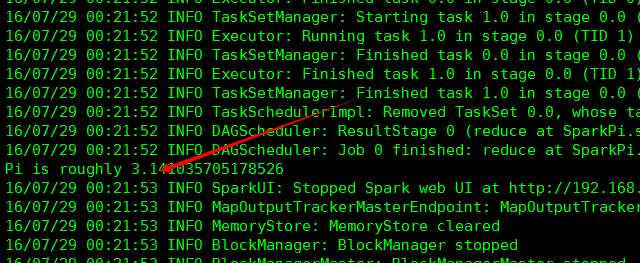
運行成功算出pi的近似值。至此spark環境搭建已經完成
“spark2.0集群環境的安裝步驟”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





