溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
python中怎么利用jieba模塊提取關鍵詞,相信很多沒有經驗的人對此束手無策,為此本文總結了問題出現的原因和解決方法,通過這篇文章希望你能解決這個問題。
1.讀取一個用戶的全部數據時,注意區分read(), readline()和readlines()的區別,read()讀取文件全部內容并存在一個字符串變量中,readline()每次只讀取文件里面的一行,readlines()返回一個行的列表。
2.注意將一個列表以字符串表達的寫法:','.join(list).例如:list = [1,2,3],則可輸出1,2,3
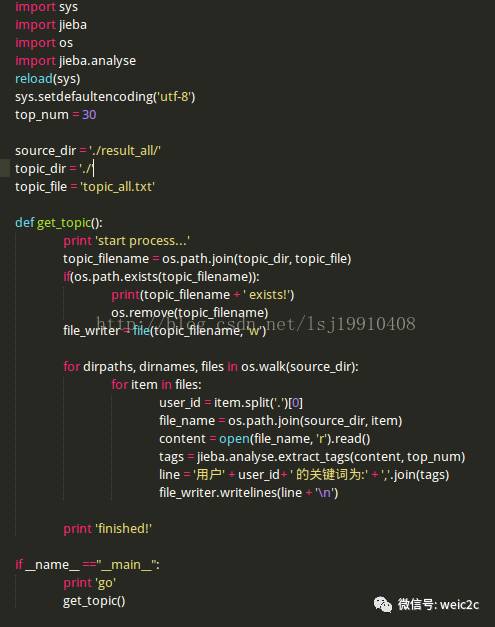
代碼如下:
文本分析--關鍵詞獲取(jieba分詞器,TF-IDF模型)
關鍵詞獲取可以通過兩種方式來獲取:
1、在使用jieba分詞對文本進行處理之后,可以通過統計詞頻來獲取關鍵詞:jieba.analyse.extract_tags(news, topK=10),獲取詞頻在前10的作為關鍵詞。
2、使用TF-IDF權重來進行關鍵詞獲取,首先需要對文本構建詞頻矩陣,其次才能使用向量求TF-IDF值。
# -*-coding:utf-8-*-
import uniout # 編碼格式,解決中文輸出亂碼問題
import jieba.analyse
from sklearn import feature_extraction
from sklearn.feature_extraction.text import TfidfTransformer
from sklearn.feature_extraction.text import CountVectorizer
"""
TF-IDF權重:
1、CountVectorizer 構建詞頻矩陣
2、TfidfTransformer 構建tfidf權值計算
3、文本的關鍵字
4、對應的tfidf矩陣
"""
# 讀取文件
def read_news():
news = open('news.txt').read()
return news
# jieba分詞器通過詞頻獲取關鍵詞
def jieba_keywords(news):
keywords = jieba.analyse.extract_tags(news, topK=10)
print keywords
def tfidf_keywords():
# 00、讀取文件,一行就是一個文檔,將所有文檔輸出到一個list中
corpus = []
for line in open('news.txt', 'r').readlines():
corpus.append(line)
# 01、構建詞頻矩陣,將文本中的詞語轉換成詞頻矩陣
vectorizer = CountVectorizer()
# a[i][j]:表示j詞在第i個文本中的詞頻
X = vectorizer.fit_transform(corpus)
print X # 詞頻矩陣
# 02、構建TFIDF權值
transformer = TfidfTransformer()
# 計算tfidf值
tfidf = transformer.fit_transform(X)
# 03、獲取詞袋模型中的關鍵詞
word = vectorizer.get_feature_names()
# tfidf矩陣
weight = tfidf.toarray()
# 打印特征文本
print len(word)
for j in range(len(word)):
print word[j]
# 打印權重
for i in range(len(weight)):
for j in range(len(word)):
print weight[i][j]
# print '\n'
if __name__ == '__main__':
news = read_news()
jieba_keywords(news)
tfidf_keywords()
看完上述內容,你們掌握python中怎么利用jieba模塊提取關鍵詞的方法了嗎?如果還想學到更多技能或想了解更多相關內容,歡迎關注億速云行業資訊頻道,感謝各位的閱讀!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





