溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
如何深度學習與 Spark 和 TensorFlow,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
在過去幾年中,神經網絡領域的發展非常迅猛,也是現在圖像識別和自動翻譯領域中最強者。TensorFlow 是谷歌發布的數值計算和神經網絡的新框架。本文中,我們將演示如何使用TensorFlow和Spark一起訓練和應用深度學習模型。
你可能會困惑:在最高性能深度學習實現還是單節點的當下, Spark 的用處在哪里?為了回答這個問題,我們將會演示兩個例子并解釋如何使用 Spark 和機器集群搭配 TensorFlow 來提高深度學習的管道數。
超參數調整: 使用 Spark 來找到最優的神經網絡訓練參數集,減少十倍訓練時間并降低34%的失誤率。
部署模型規模: 使用 Spark 在大量數據上應用訓練完畢的神經網絡模型。
深度機器學習(ML)技術的一個典型應用是人工神經網絡。它們采取一個復雜的輸入,如圖像或音頻記錄,然后對這些信號應用復雜的數學變換。此變換的輸出是更易于由其他ML算法處理的數字向量。人工神經網絡通過模仿人類大腦的視覺皮層的神經元(以相當簡化的形式)執行該轉換。
就像人類學會解讀他們所看到的,人工神經網絡需要通過訓練來識別那些“有趣”的具體模式。可以是簡單的模式,比如邊緣,圓形,但也可以是更復雜的模式。在這里,我們將用NIST提供的經典數據集來訓練神經網絡以識別這些數字:

TensorFlow 庫將會自動創建各種形狀和大小的神經網絡訓練算法。建立一個神經網絡的實際過程,比單純在數據集上跑一些算法要復雜得多。通常會有一些非常重要的超參數(通俗地說,參數配置)需要設置,這將影響該模型是如何訓練的。選擇正確的參數可以讓性能優越,而壞的參數將會導致長時間的訓練和糟糕的表現。在實踐中,機器學習從業者會多次使用不同的超參數重復運行相同的模型,以期找到最佳的集合。這是一個被稱為超參數調整的經典技術。
建立一個神經網絡時,有許多需要精心挑選的重要超參數。 例如:
每層的神經元數目:太少的神經元會降低網絡的表達能力,但太多會大大增加運行時間,并返回模糊噪音。
學習速度:如果過高,神經網絡將只專注于看到過去的幾個樣例,并忽略之前積累的經驗。如果太低,則需要很長時間才能達到一個很好的狀態。
這里有趣的是,即使 TensorFlow 本身不予分發,超參數調整過程是“易并行”(embarrassingly parallel),并且可以使用 Spark 來分配的。在這種情況下,我們可以使用 Spark 廣播通用的元素,例如數據和模型描述,然后以允許錯誤的方式安排機器集群中的個體進行獨立的重復性計算。

如何使用 Spark 提高精度?用默認的超參數設置精度為99.2%。我們在測試集上的最好結果是99.47%的精確度,這減少了34%的測試誤差。分布式計算時間與添加到集群的節點數量成線性關系:使用有13個節點的集群,我們能夠并行培養13個模型,這相比于在同一臺機器一個接著一個訓練速度提升了7倍。這里是相對于該集群上機器的數量的計算時間(以秒計)的曲線圖:
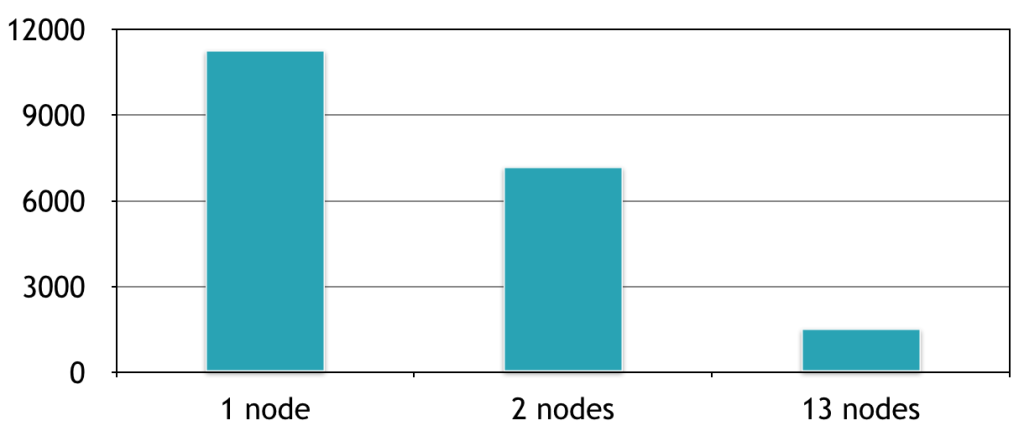
最重要的是,我們分析了大量訓練過程中的超參數的靈敏度。例如,我們相對于不同數目的神經元所得學習率繪制了最終測試性能圖:
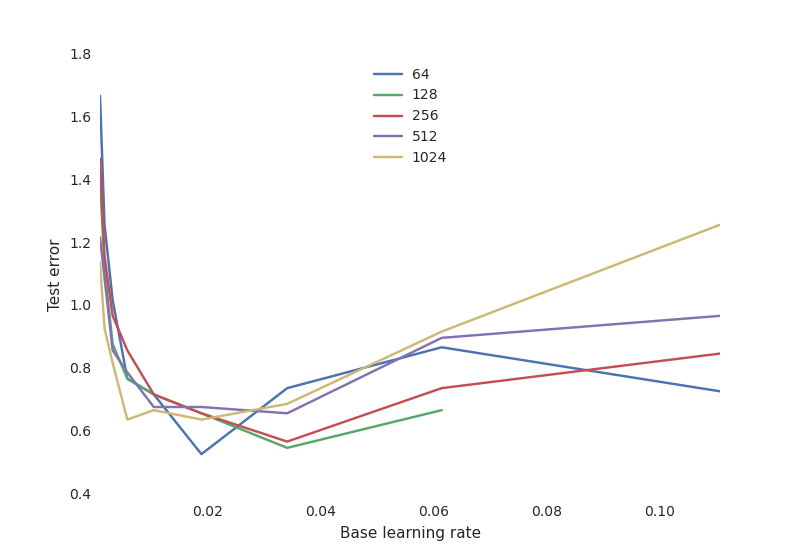
這顯示了一個典型的神經網絡權衡曲線:
學習速度是非常關鍵的:如果它太低,神經網絡沒有學到任何東西(高測試誤差)。如果它太高,訓練過程可能發生隨機振蕩甚至在某些配置下出現發散。
神經元的數目對于獲得良好的性能來說沒有那么重要,并且有更多神經元的網絡的學習率更加敏感。這是奧卡姆剃刀原則:對大多數目標來說,簡單的模型往往已經“足夠好”。除非你在訓練中投入大量的時間和資源,并找到合適的超參數來除去這缺少的1%測試誤差,這才會有所不同。
通過使用參數稀疏樣本,我們可以在最優的參數集下取得零失誤率。
盡管 TensorFlow 可以使用每一個 worker 上的所有核心,但每個工人同一時間只能運行一個任務,我們可以將它們打包以限制競爭。TensorFlow 庫可以按照[instructions on the TensorFlow website](https://www.tensorflow.org/get_started/os_setup.html)上的指示在 Spark 集群上作為一個普通的Python庫進行安裝。下面的筆記展示了用戶如何安裝 TensorFlow 庫并重復該文章的實驗:
使用 TensorFlow 進行圖像分布式處理
使用 TensorFlow 進行圖像分布式處理測試
TensorFlow 模型可以直接在管道內嵌入對數據集執行的復雜識別任務。作為一個例子,我們將展示我們如何能夠使用一個已經訓練完成的股票神經網絡模型標注一組圖片
首先使用 Spark 內置的廣播機制將該模型分發到集群中的worker上:
with gfile.FastGFile( 'classify_image_graph_def.pb', 'rb') as f: model_data = f.read() model_data_bc = sc.broadcast(model_data)
之后,這個模型被加載到每個節點上,并且應用于圖片。這是每個節點運行的代碼框架:
def apply_batch(image_url):
# Creates a new TensorFlow graph of computation and imports the model
with tf.Graph().as_default() as g:
graph_def = tf.GraphDef()
graph_def.ParseFromString(model_data_bc.value)
tf.import_graph_def(graph_def, name='')
# Loads the image data from the URL:
image_data = urllib.request.urlopen(img_url, timeout=1.0).read()
# Runs a tensor flow session that loads the
with tf.Session() as sess:
softmax_tensor = sess.graph.get_tensor_by_name('softmax:0')
predictions = sess.run(softmax_tensor, {'DecodeJpeg/contents:0': image_data})
return predictions通過將圖片打包在一起,這份代碼可以運行地更快。 下面是圖片的一個樣例: 
這是神經網絡對于這張圖片的解釋,相當精確:
('coral reef', 0.88503921),
('scuba diver', 0.025853464),
('brain coral', 0.0090828091),
('snorkel', 0.0036010914),
('promontory, headland, head, foreland', 0.0022605944)])看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





