溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
和傳統的程序設計語言不同,SPL中集合的應用非常普遍,實際上最常見的序列和序表等本質上都是集合,可以對它們進行真正的集合運算,從而大幅度提高開發效率和代碼性能。因此,在使用SPL時,需要特別重視對集合概念的理解。
SPL中,序列如同整數、字符串一樣是非常常用的基本數據類型,也能進行相應的基本運算。從集合角度出發,SPL提供了兩個集合A、B的交、并、聯、差等基本運算符:A^B,A|B,A&B,A\B等。如果能夠從這些運算開始深刻理解并熟練運用,解決問題時就能更主動地采用集合思維,從而充分利用已知的數據,思路更直接和簡潔,方法也更加簡易清晰。
下面的例子顯示了如何利用集合運算來簡化代碼:
| A | |
|---|---|
| 1 | =demo.query("select EID, NAME, ? SURNAME, GENDER, STATE from EMPLOYEE") |
| 2 | =A1.select(GENDER=="M") |
| 3 | =A1.select(STATE=="California") |
| 4 | =A2^A3 |
| 5 | =A1.select(GENDER=="M" && ? STATE=="California") |
| 6 | =A2&A3 |
| 7 | =A1.select(GENDER=="M" || ? STATE=="California") |
| 8 | =A2\A3 |
| 9 | =A1.select(GENDER=="M" && ? STATE!="California") |
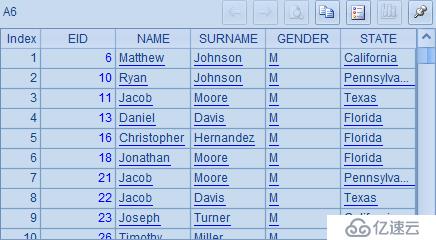
代碼中,A4、A6、A8采用了集合運算,分別統計了California州的男員工、所有男性或者位于California州的員工、不在California州的男員工,形式上和A5、A7、A9的傳統統計方式相比,明顯簡潔了很多。
但是,需要注意的是,A6與A7中雖然獲得的員工資料一致,但結果中記錄的順序不同,如下所示:
 ?
? 
造成這種情況的原因是,與數學上的集合不完全相同,SPL中的集合稱為有序集合,是有次序的,同時也可以有重復的成員。序列、序表、排列等全都是這種有序集合。
| A | |
|---|---|
| 1 | [1,2,3,4] |
| 2 | [1,3,3,2] |
| 3 | =[1,2,3]==[1,3,2] |
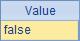
上表中,A2中的序列有重復的成員,而A3中兩個序列中成員順序不同,直接比較時會認為它們不相等,結果為false:
另外,數學上集合的交并運算是可交換的,即A∩BoB∩A和A∪B o B∪A,但由于SPL中的集合是有序集合,因此交換律并不成立,交并運算的結果集合將以左操作數的次序為準。
| A | |
|---|---|
| 1 | [1,2,3] |
| 2 | [3,1,5] |
| 3 | =A1^A2 |
| 4 | =A2^A1 |
| 5 | =A1&A2 |
| 6 | =A2&A1 |
?
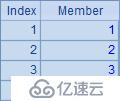
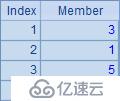
A3,A4,A5和A6中的計算結果依次如下:


由于SPL中的序列是有序集合,因此判斷兩個序列是否有同樣成員不能簡單地用比較符==,而要用函數A.eq(B):
| A | |
|---|---|
| 1 | =[1,2,3]==[3,2,1] |
| 2 | =[1,2,3]==[3,2,1].sort() |
| 3 | =[1,2,3].eq([3,2,1]) |
| 4 | =[1,2,3].eq([3,2,2]) |
| 5 | =[1,2,2,3].eq([3,2,1,2]) |
| 6 | =[1,2,2,3].eq([3,2,3,1]) |
A1與A2中判斷兩個序列是否相同,結果如下:

這是因為A2中[3,2,1]執行sort函數排序后,得到的結果是[1,2,3],次序也和A1一樣了。
A3、A4、A5和A6分別都使用函數A.eq(B)來判斷兩個序列是否有著同樣的成員,結果依次如下:
如果兩個序列中的所有成員全相同,則稱這兩個序列互為置換列。特別的,如果序列中出現了重復的成員,那么它的置換列中,這個成員也需要有同樣的重復數量。
有了集合數據類型,許多針對集合中成員的運算就可以方便地一句寫出來,不再需要編寫循環代碼了。
| A | |
|---|---|
| 1 | [3,4,1,3,6] |
| 2 | =A1.sum() |
| 3 | =A1.avg() |
| 4 | =A1.max()-A1.min() |
上表用到了4個循環函數,A2中的sum()計算序列中成員的總和,A3中的avg()計算序列成員的平均值,A4中的max()和min()計算序列中最大值與最小值的差。它們的計算結果依次如下:



循環函數計算時不僅可以使用集合成員本身的值,而且可以使用成員計算出來的值,包括成員值的計算結果,以及具有結構的集合成員的屬性值。這時可以在函數的參數中指明計算式,其中用符號~表示循環計算中的當前成員。
| A | |
|---|---|
| 1 | [3,4,1,3,6] |
| 2 | =A1.sum(~*~) |
| 3 | =demo.query("select * from ? EMPLOYEE") |
| 4 | =A3.min(~.BIRTHDAY) |
| 5 | =A3.min(BIRTHDAY) |
| 6 | =A3.avg(interval@y(BIRTHDAY,HIREDATE)) |
上表中的A2計算序列中成員的平方和,即循環累加每個成員值的平方,結果如下:

而A4、A5和A6則對A3生成的集合中的每個成員的屬性值進行循環計算。A3對員工信息序表進行查詢后生成集合,其中每個成員是一個員工的信息。A4中計算員工最早的生日,即成員生日的最小值,結果如下:
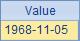
A4表達式中的~.可以省略,寫成A5的樣子,因此計算結果與A4相同。
A6中計算所有員工平均入職年齡,即每個成員入職時間和生日時間的年份差的平均值,結果如下:

執行帶有參數的聚合函數可以被理解為如下兩步:
1)??????? 先根據參數表達式對集合中的每個成員進行計算,結果稱為計算列
2)??????? 再對計算列做聚合計算。
形式上可以表示為:A.f(x)=A.(x).f(),如A1.sum(~*~) 相當于A1.(~*~).sum(),其中A1.(~*~) 為計算列函數,即計算出A1中每個成員的平方,并返回為序列。
?
上面例子中A5、A6省略了符號~,這是因為只使用了一層循環函數,省略~不會引起歧義。如果嵌套使用循環函數,~將被解釋為內層序列的成員,這時如果想引用外層序列成員,就必須在~前加上外層序列名。
| A | |
|---|---|
| 1 | [A,B,C] |
| 2 | [a,b,c] |
| 3 | =A1.(A2.(~/~)) |
| 4 | =A1.(A2.(A1.~/~)) |
| 5 | =A1.(A1.(A1.~/~)) |
| 6 | =A1.((arg=~,A1.(arg/~))) |
這個例子中用到了字符串拼接運算/。A3中,在循環中用/拼接兩個字母,但只用~就只能取到內層序列A2的成員,所以得到的字串只是兩個重復的小寫字母。而A4在循環時指明前一個~所對應的是外層序列,因此得到的是A1大寫字母在前、A2小寫字母在后拼接的結果。A5的表達式中,內層循環即便用了A1.~,但無法識別究竟是哪一層的A1,因此無法引用外層A1成員,所以計算時只能使用內層序列中的成員,因此得到的結果就是重復的大寫字母。這種情況下,如果需要引用外層的成員,就需要采用A6的方法,先將外層成員值賦給臨時變量,再通過臨時變量引用,這樣就可以得到大寫字母交叉拼接的結果了。A3~A6中的計算結果依次如下:

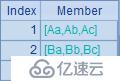
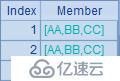
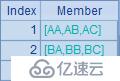
關于~的這個規則同樣適用于序表或排列的循環計算,省略~的字段引用寫法,字段將被優先解釋為內層排列的字段,如果在內層排列找不到指定的屬性字段才會再向外層找。
簡單地說,循環函數在計算時將按原序列的次序依次計算,而我們在使用時可以充分利用這一特點。
| A | |
|---|---|
| 1 | [1,3,2,5,4,8,7] |
| 2 | 0 |
| 3 | =A1.(A2=A2+~) |
| 4 | [1,1,0,0,1,0,0,0,1,0,1,0,0,0] |
| 5 | 0 |
| 6 | =A4.max(if(~==0,A5=A5+1,A5=0)) |
A3中,通過循環,計算出A1中成員累積和序列:
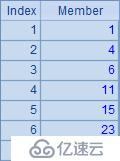
A6中,計算出序列A4中,成員0連續出現的最長個數:

類似的情況很多,我們可以只用一個表達式就寫出等同于簡單循環代碼的效果。
除了上面這些返回單個聚合值的循環函數(如sum, avg),很多情況我們還需要繼續對集合進行計算,除了采用基本的集合并、交、差等運算能夠生成一個新集合外,使用計算序列函數A.(x)返回一個集合,也是很常用的方法。
| A | |
|---|---|
| 1 | [1,2,3] |
| 2 | =A1.(~*~) |
| 3 | =A1.(~) |
| 4 | =A1.() |
| 5 | =A1.(1) |
| 6 | =A1.(if(~%2==0,~,0)) |
| 7 | I love you |
| 8 | =len(A7).(mid(A7,~,1)) |
| 9 | =A8.count(~=="o") |
例子中的A2~A6根據序列A1計算,生成不同的新序列:A2計算每個成員的平方;A3與A4都是用原序列的成員生成新序列;A5循環生成和原序列數量相同的序列,但其中的成員都是1;A6略為復雜些,在循環計算對A1中的成員逐個判斷,如果為奇數,則得到0,否則獲得對應成員的值。A2~A6的計算結果如下:
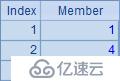
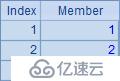
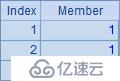
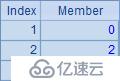
A8的完整寫法是=to(len(A7)).(mid(A7,~,1)),其中to(n)函數生成一個從1到n的數字組成的新序列(熟練后和前面的符號 ~ 一樣,有些情況可以省略),對這個序列進行循環,逐個取出A7中的字符串,從而展開為單字符構成的序列;A9計算出其中字母o出現的次數。A8與A9中的結果如下:


除了返回序列,我們還可以對序列計算后返回序表,這時需要用new函數。
| A | |
|---|---|
| 1 | [1,2,3,4,5] |
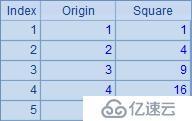
| 2 | =A1.new(~:Origin,~*~:Square) |
| 3 | =demo.query("select * from ? EMPLOYEE") |
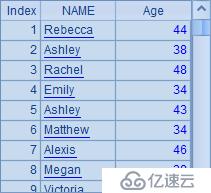
| 4 | =A3.new(NAME,age(BIRTHDAY):Age) |
| 5 | =A3.new(NAME) |
| 6 | =A3.(NAME) |
A2根據A1循環計算返回新的序表,其中包含兩個字段,一個是A1中的成員,另一個則是該成員的平方值。表達式中的 ~ 前面已經介紹過了,表示當前循環到的序列成員,結果如下:
A3從數據表EMPLOYEE中取出數據產生一個序表,A4從中獲取NAME和BIRTHDAY兩個字段,并根據BIRTHDAY計算出該職員的年齡,形成一個新字段Age,最終生成包含了NAME和Age兩個字段的新序表。結果如下:
 ?
?
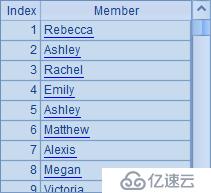
A5和A6看上去類似,但實際上卻有區別,A5從A3序表中取出NAME字段,然后直接生成包含了一個NAME字段的新序表;而A6則是根據A3中序表循環計算出由NAME字段構成的序列,兩個結果的不同在于,序表有數據結構而序列無數據結構:
 ??
??
另外,還有一個僅用于計算的run函數,它直接修改原序列本身,而不是對位計算后返回新的結果序列,一般用于針對排列(序表)修改字段值。
| A | |
|---|---|
| 1 | =demo.query("select * from ? EMPLOYEE") |
| 2 | =A1.new(NAME,age(BIRTHDAY):Age) |
| 3 | =A2.run(Age=Age+1) |
例子中,A2中生成新序表,列出員工的名字并計算出他們的年齡。而在A3中針對新序表A2進行計算,將每位員工的年齡加1。run函數改變的是原序表A2中的數據,因此A2與A3中結果是相同的,將一同返回修改后的結果。使用分步執行可以看到A2中序表的變化:
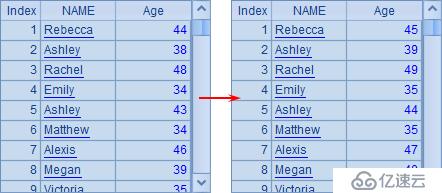
SPL不要求序列成員的數據類型一致,因此完全可以把數值、字串以及復雜的記錄作為同一個序列的成員。
| A | |
|---|---|
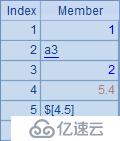
| 1 | [1,a3,2,5.4,$[4.5],2011-8-8] |
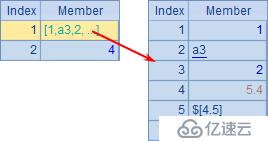
| 2 | =[A1,4] |
A1中包含多種數據類型的成員,而A2中的序列是由序列A1與整數成員構成的,A1與A2中的數據如下:
 ?
? 
?
不過,對于一般的序列,在大多數情況下,將不同類型的數據置于同一序列中并沒有多少實際的業務意義,因此不必過于關注。
但是,對于排列,即以記錄構成的序列,允許由來自不同序表的記錄構成,這一點會有實實在在的方便性。
| A | |
|---|---|
| 1 | =demo.query("select * from ? EMPLOYEE") |
| 2 | =demo.query("select * from ? FAMILY") |
| 3 | =A1|A2 |
| 4 | =A3.count(left(GENDER,1)=="F") |
A4計算員工和家屬中,女性一共有多少人。即使員工表和家屬表結構不同,但只要其中都包含GENDER字段,就可以正常計算。
從這個例子可以看出,SPL并不關心排列中的記錄是否來自同一序表,只要它們有名稱相同的字段就可以對其執行一致的操作,而不必象SQL那樣必須將兩個不同結構的表先用UNION語句聯合成一個新表才能操作。這樣不僅思路清楚、書寫簡單,而且不會占用多余的內存,同時運算效率更高。
特別地,集合成員的任意性還允許集合本身作為成員。同時,當A是集合的集合時,還可以進一步使用A.conj(),A.union(),A.diff(),A.isect()這些函數,計算A中各個集合的和列、并列、差列和交列。
| A | |
|---|---|
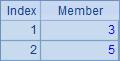
| 1 | [[1,2,3,4,5],[1,3,5,7,9],[2,3,5,7]] |
| 2 | =A1.conj() |
| 3 | =A1.isect() |
| 4 | =A1.(~.sum()) |
| 5 | =A1.(~.(~*~)) |
A1中是一個序列構成的序列。A2,A3,A4和A5分別計算A1中序列成員的和序列、交集序列、各個序列求和的結果以及各個系列每個成員的平方構成的序列。計算后,A2~A5中的結果如下:

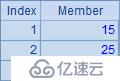

?
類似的,排列也可以作為序列的成員。
| A | |
|---|---|
| 1 | =demo.query("select EID, NAME, ? SURNAME, GENDER, STATE from EMPLOYEE") |
| 2 | =A1.select(STATE=="California") |
| 3 | =A1.select(STATE=="Indiana") |
| 4 | =A1.select(STATE=="Florida") |
| 5 | =[A2,A3,A4] |
| 6 | =A5.(~.count()) |
| 7 | =A5.(~(1).STATE) |
| 8 | =A5.(STATE) |
| 9 | =A5.new(STATE,~.count():Count) |
A2,A3與A4中分別取出California,Indiana和Florida這3個州的員工數據。A5中獲得的就是由A2~A4這3個排列構成的序列,是個集合的集合:
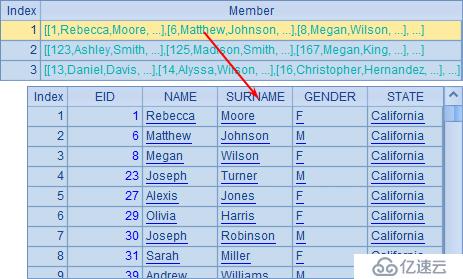
A6分別計算各州員工數,結果如下:
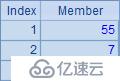
A7中取出各個州的名稱,表達式中的~(1)是可以省略的,也就是說A8與A7是等價的,結果也一樣:

A9效果看上去和A6一樣,也是統計3個州的員工數,但通過new生成了一個新的序表,看上去更加清晰,也方便以后根據州名檢索使用::
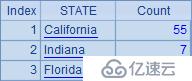
分組是SQL中很常用的運算,但未必所有人都能深刻理解它。
從集合的角度看,分組運算的實質是將一個集合按某種規則拆分成若干子集,也就是說,其返回值應當是若干個集合構成的集合。只不過人們經常不需要直接察看集合中的這些子集,而是對子集的某些匯總值更感興趣,因此,分組常常伴隨著對子集的進一步匯總計算。
SQL正是這樣處理的,它的GROUP BY語句總是配合相應的匯總計算。當然,這也是因為SQL自身沒有顯式的集合數據類型,所以無法直接返回“集合的集合”這類數據,只能把匯總計算強加到分組計算之后。
久而久之,人們習慣了分組總是需要配合后續的匯總計算,而忘記了分組和匯總其實是兩個獨立的步驟。
?
但是無論如何,我們仍然會有對這些分組子集感興趣的時候。而且退一步講,即使只對匯總值有興趣,保持住這些子集也有價值,因為如果可以重復利用,不必每次都重新生成,那么無論在代碼的簡潔還是性能的提升方面都會有很大的幫助。
而對于SPL來說,因為它充分實現了集合思維,所以就能夠做到還原分組運算的本意。事實上,SPL中的基本分組函數就是只做純粹的分組,而把匯總計算剝離出去了。
| A | B | |
|---|---|---|
| 1 | =demo.query("select * from ? EMPLOYEE") | |
| 2 | =A1.group(month(BIRTHDAY),day(BIRTHDAY)) | /將員工按生日(月、日)分組 |
| 3 | =A2.select(~.len()>1) | /有其他人生日與之相同的員工 |
| 4 | =A3.conj() | |
| 5 | =A1.group(STATE) | /將員工按所在州分組 |
| 6 | =A5.new(~(1).STATE:State,~.count():Count) | /用分組結果計算序表,各州員工數 |
| 7 | =A5.new(STATE,~.avg(age(BIRTHDAY)):Age) | /計算序表,各州員工平均年齡 |
?
分組的結果本身是一個集合的集合,因此當然還可以繼續分組。而分組結果集合中的各個成員也是集合,各自也能夠再繼續分組。這是兩種不同的操作,但都會形成多層集合。
| A | B | |
|---|---|---|
| 1 | =demo.query("select * from ? EMPLOYEE") | |
| 2 | =A1.group(year(BIRTHDAY)) | /按員工出生年份分組 |
| 3 | =A2.group(int(year(~(1).BIRTHDAY)%100/10)) | |
| 4 | =A2.group(int(year(BIRTHDAY)%100/10)) | |
| 5 | =A2.(~.group(month(BIRTHDAY))) | /把分組后的結果再次分組,A3、A4、A5都將返回排列的序列 |
如果集合運算結果的層次太深,那么現實的業務含義可能不是很大,但可以用來體會集合的思維方式及運算的實質。
?
在分組的同時,group函數會同時將各個組按照分組表達式的結果排序,如:
| A | B | |
|---|---|---|
| 1 | $ select EID,NAME+' '+SURNAME FULLNAME, ? DEPT from EMPLOYEE | |
| 2 | =A1.group(DEPT) | =A2.new(~.DEPT:DEPT,~.count():Count) |
| 3 | =A2.sort(~.DEPT:-1) | =A3.new(~.DEPT:DEPT,~.count():Count) |
| 4 | =A1.group@u(DEPT) | =A4.new(~.DEPT:DEPT,~.count():Count) |
| 5 | =A1.group@o(DEPT) | =A5.new(~.DEPT:DEPT,~.count():Count) |
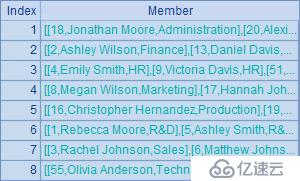
A1中得到的序表如下:

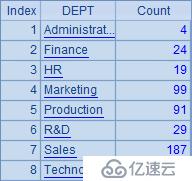
A2中按部門名稱將員工數據分組,默認情況下,A2中的分組結果就會按照部門名稱升序排序。在B列中統計了各種分組情況下各部門的人數,以便通過DEPT列直接查看排序情況。A2和B2中結果如下:
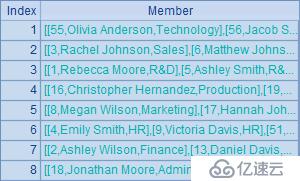
A3將A2中的分組結果改為按照部門降序排序,效果可以在B3中看到,結果如下:

除了將分組結果重新排序,還可以在執行group時添加選項來調整分組順序。
A4中添加通過@u選項在分組時保持各部門在員工表中出現的原始順序。
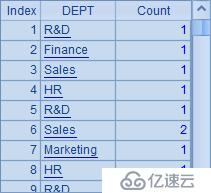
A5中添加的@o選項指定分組時不對記錄做整體排序,而只會將分組表達式相等的相鄰記錄分為一組,因此更像是“相鄰合并”。顯然,這種情況可能會出現的“重復”分組。B4和B5顯示了這兩種情況的效果:

除了常規的group函數,SPL還提供了處理對齊分組的A.align@a()函數和處理枚舉分組的A.enum()函數。
我們稱通過group函數完成的分組為等值分組,它具有這樣的特點:
1)??????? 原集合中任何成員都必須在且只能在某一個子集中,也就是分組后的子集成員完全覆蓋原集合,并且子集之間沒有重疊;
2)??????? 沒有空子集
而對齊分組和枚舉分組則不一定滿足這兩點。
?
對齊分組是指,用集合中成員計算分組表達式,根據計算結果與事先指定的一個序列中的值一一對應,完成分組。對齊分組需要如下幾步:
1)??????? 事先指定一組值
2)??????? 將待分組集合中某個表達式計算結果和指定值相同的成員劃分到同一個子集
3)??????? 結果的每個子集將和事先指定的值一一對應。
在這種分組規則下,可能有某個成員不在任何一個子集中,也可能出現空集,或者某成員在兩個子集中都存在。
如下面的例子,將員工按指定的州序列分組:
| A | |
|---|---|
| 1 | =demo.query("select * from ? EMPLOYEE") |
| 2 | [California,Florida,Chicago] |
| 3 | =A1.align@a(A2,STATE) |
在A3中,將集合A1根據A2對齊分組,將A1成員的州名稱與A2的成員做對應。在這樣的分組過程中,有可能有些員工不在任何一個分組中(其他州的員工),也有可能出現沒有任何成員的空組(Chicago不是州名稱,根本沒有對應的員工)。例如,在某種數據情況下,A3結果:

?
枚舉分組是指,事先指定一組條件,將待分組集合中成員作為參數計算該條件,條件成立者將被劃分到對應的子集。這時也可能有某個成員不在任何一個子集中,以及出現空集,還可能有成員同時在兩個子集中。
如下面的例子,將員工按照指定的年齡段分組:
| A | |
|---|---|
| 1 | =demo.query("select EID, NAME, ? SURNAME, GENDER, BIRTHDAY from EMPLOYEE") |
| 2 | [?<=35,? <=45,?>45] |
| 3 | =A1.enum(A2,age(BIRTHDAY)) |
| 4 | [?<=35,?>20 && ?<=45,?>45] |
| 5 | =A1.enum@r(A4,age(BIRTHDAY)) |
A3中,根據A2中的年齡條件序列進行枚舉分組。enum()函數不指定選項時,不允許分組結果出現重復,也就是說A1中某個員工的記錄可以不在任何分組中(不過例子中的條件是全覆蓋的),但是不會同時出現在兩個分組中(也就是不會重疊)。A3結果如下:
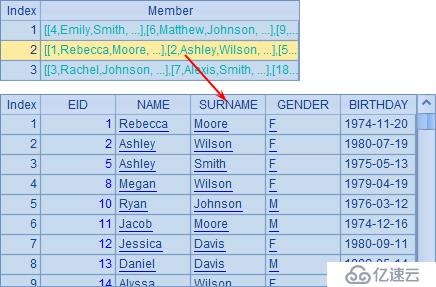
此時,某個年輕的(35歲以下)員工會被分配到第1個分組中。而由于不允許重疊,因此即便他也滿足第二個條件,45歲以下,仍不會再被重復分配到第2組中。
A5也是根據A4中的條件序列進行枚舉分組,不過這里使用enum函數時添加了@r選項,表示分組時可重復。此時,某個員工的記錄有可能同時出現在多個分組中了。例如:
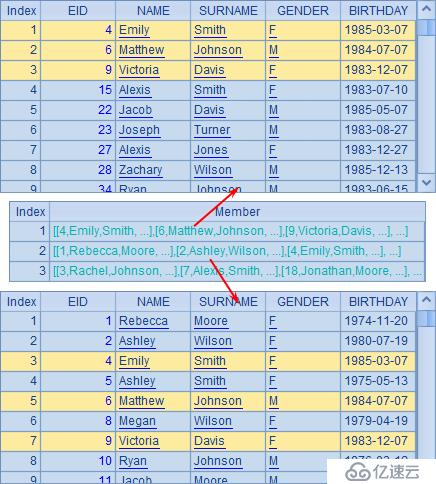
可以看到,某些員工記錄會同時存在于前兩個分組中。
?
align@a函數和enum函數雖然看起來和group函數相差很大,不過在理解了分組運算的本質后,就能明白它們其實都是在做同一件事:即把一個集合拆分成若干個子集,所不同的只是拆分的具體條件和規則不同罷了。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





