溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“RDD怎么向spark傳遞函數”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
RDD的轉換操作都是惰性求值的。
惰性求值意味著我們對RDD調用轉化操做(例如map操作)并不會立即執行,相反spark會在內部記錄下所要求執行的操作的相關信息。
把數據讀取到RDD的操作同樣也是惰性的,因此我們調用sc.textFile()時數據沒有立即讀取進來,而是有必要時才會讀取。和轉化操作一樣讀取數據操作也有可能被多次執行。這在寫代碼時要特別注意。
關于惰性求值,對新手來說可能有與直覺相違背之處。有接觸過函數式語言類如haskell的應該不會陌生。
在最初接觸spark時,我們也會有這樣的疑問。
也參與過這樣的討論:
val sc = new SparkContext("local[2]", "test")
val f:Int ? Int = (x:Int) ? x + 1
val g:Int ? Int = (x:Int) ? x + 1
val rdd = sc.parallelize(Seq(1,2,3,4),1)
//1
val res1 = rdd.map(x ? g(f(x))).collect
//2
val res2 = rdd.map(g).map(f).collect第1和第2兩種操作均能得到我們想要的結果,但那種操作更好呢?
直觀上我們會覺得第1種操作更好,因為第一種操作可以僅僅需要一次迭代就能得到我們想要的結果。第二種操作需要兩次迭代操作才能完成。
是我們想象的這樣嗎?讓我們對函數f和g的調用加上打印。按照上面的假設。1和2的輸出分別是這樣的:
1: f g f g f g f g 2: g g g g f f f f
代碼:
val sc = new SparkContext("local[2]", "test")
val f:Int ? Int = (x:Int) ? {
print("f\t")
x + 1
}
val g:Int ? Int = (x:Int) ? {
print("g\t")
x + 1
}
val rdd = sc.parallelize(Seq(1,2,3,4), 1
//1
val res1 = rdd.map(x ? g(f(x))).collect()
//2
val res2 = rdd.map(f).map(g).collect()將上面的代碼copy試著運行一下吧,我們在控制臺得到的結果是這樣的。
f g f g f g f g f g f g f g f g
是不是大大出乎我們的意料?這說明什么?說明spark是懶性求值的! 我們在調用map(f)時并不會真正去計算, map(f)只是告訴spark數據是怎么計算出來的。map(f).map(g)其實就是在告訴spark數據先通過f在通過g計算出來的。然后在collect()時,spark在一次迭代中先后對數據調用f、g。
繼續回到我們最初的問題,既然兩種調用方式,在性能上毫無差異,那種調用方式更好呢?我們更推薦第二種調用方式,除了api更加清晰之外。在調用鏈很長的情況下,我們可以利用spark的檢查點機制,在中間添加檢查點,這樣數據恢復的代價更小。而第一種方式調用鏈一旦出錯,數據只能從頭計算。
那么spark到底施加了何種魔法,如此神奇?讓我們來撥開spark的層層面紗。最好的方式當然是看源碼了。以map為例:
RDD的map方法
/**
* Return a new RDD by applying a function to all elements of this RDD.
*/
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}和MapPartitionsRDD的compute方法
override def compute(split: Partition, context: TaskContext): Iterator[U] = f(context, split.index, firstParent[T].iterator(split, context))
關鍵是這個 iter.map(cleanF)),我們調用一個map方法其實是在iter對象上調用一個map方法。iter對象是scala.collection.Iterator的一個實例。
在看一下Iterator的map方法
def map[B](f: A => B): Iterator[B]=
new AbstractIterator[B] {
def hasNext = self.hasNext
def next() = f(self.next())
}聯想到我們剛才說的我們在RDD上調用一個map方法只是告訴spark數據是怎么計算出來的,并不會真正計算。是不是恍然大悟了。
我們可以把定義好的內聯函數、方法的引用或靜態方法傳遞給spark。就像scala的其它函數式API一樣。我們還要考慮一些細節,比如傳遞的函數及其引用的變量是可序列話的(實現了java的Serializable接口)。除此之外傳遞一個對象的方法或字段時,會包含對整個對象的引用。我們可以把該字段放到一個局部變量中,來避免傳遞包含該字段的整個對象。
scala中的函數傳遞
class SearchFunctions(val query:String){
def isMatch(s:String) = s.contains(query)
def getMatchFuncRef(rdd:RDD[String])
:RDD[String]= {
//isMatch 代表this.isMatch因此我們要傳遞整個this
rdd.map(isMatch)
}
def getMatchFieldRef(rdd:RDD[String])={
//query表示this.query因此我們要傳遞整個this
rdd.map(x=>x.split(query))
}
def getMatchsNoRef(rdd:RDD[String])={
//安全只要把我們需要的字段放到局部變量中
val q = this.query
rdd.map(x=>x.split(query))
}
}如果在scala中出現了NotSerializableException,通常問題就在我們傳遞了一個不可序列化類中的函數或字段。傳遞局部可序列變量或頂級對象中的函數始終是安全的。
如前所述,spark的RDD是惰性求值的,有時我們希望能過多次使用同一個RDD。如果只是簡單的對RDD調用行動操作,spark每次都會重算RDD和它的依賴。這在迭代算法中消耗巨大。 可以使用RDD.persist()讓spark把RDD緩存下來。
讓我們來看看兩種workCount的方式,一種使用reduceByKey,另一種使用groupByKey。
val words = Array("one", "two", "two", "three", "three", "three")
val wordPairsRDD = sc.parallelize(words).map(word => (word, 1))
val wordCountsWithReduce = wordPairsRDD
.reduceByKey(_ + _)
.collect()
val wordCountsWithGroup = wordPairsRDD
.groupByKey()
.map(t => (t._1, t._2.sum))
.collect()雖然兩種方式都能產生正確的結果,但reduceByKey在大數據集時工作的更好。這時因為spark會在shuffling數據之前,為每一個分區添加一個combine操作。這將大大減少shuffling前的數據。
看下圖來理解 reduceBykey的過程
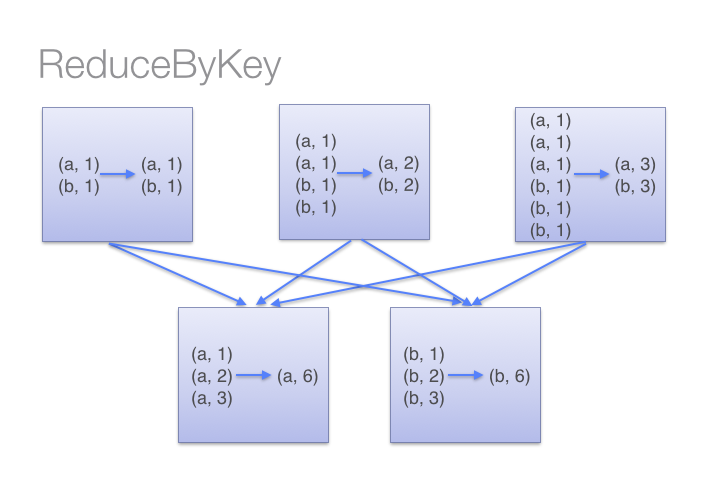
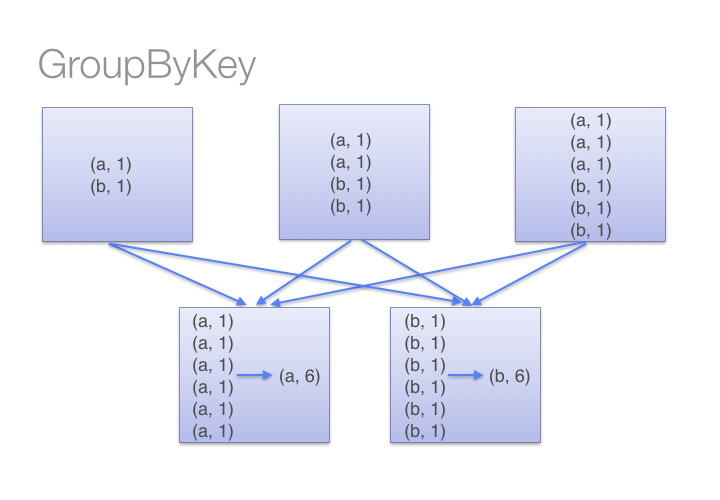
而groupBykey會shuff所有的數據,這大大加重了網絡傳輸的數據量。另外如果一個key對應很多value,這樣也可能引起out of memory。
如圖,groupby的過程
“RDD怎么向spark傳遞函數”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





