溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關如何在window上使用VirtualBox搭建Ubuntu15.04全分布Hadoop2.7.1集群,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
先給大家看看配置好的集群截圖:
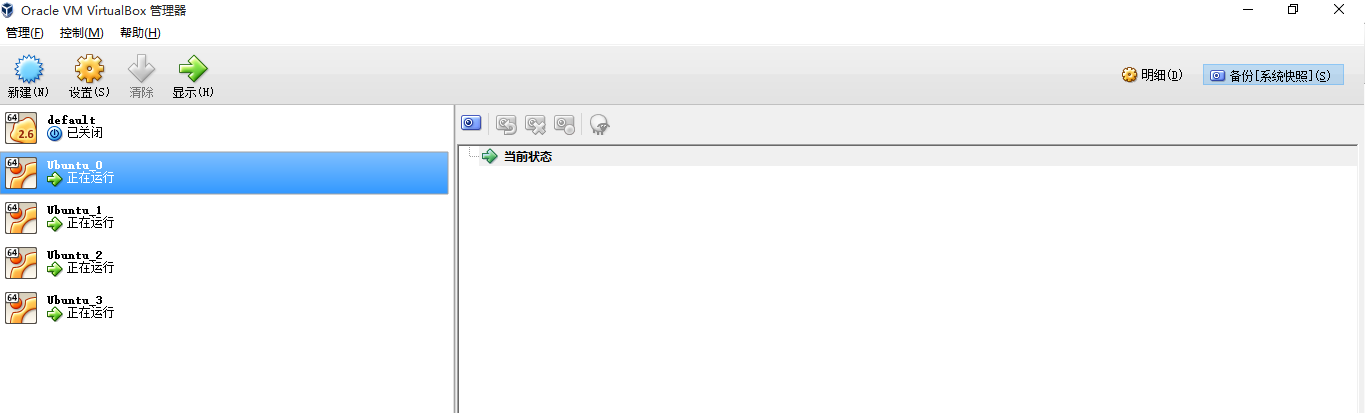
注意(default是docker的,大家不用管,下面四臺才是,其中Ubuntu_0是master,Ubuntu_1,2,3是slave節點)
一.新建虛擬機,配置基礎java環境,配置網絡訪問
下載Ubuntu15.04,打開VirtualBox,新建Ubuntu虛擬機,用戶名linux1,不截圖了,內存選1G就夠了
接下來,下載并安裝JDK:
下載:去官網下載對應版本的JDK,我這里是jdk-8u60-linux-x64.tar.gz
新建安裝目錄:
sudo mkdir /usr/local/java
解壓JDK:
sudo tar xvf ~/Downloads/jdk-8u60-linux-x64.tar.gz -C /usr/local/java
設置全局環境變量:
sudo gedit ~/.bashrc
文件末尾添加:
export JAVA_HOME=/usr/local/java/jdk1.8.0_60
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH驗證:新開終端,輸入java驗證(當前終端內不生效)
接下來,配置網絡(為啥要配置:因為你搭的是集群,用的是集群的服務,肯定想除了集群以外的機器能訪問,而不是像網上那些人省事,直接在master上安裝Eclipse,進行開發,這樣是不對的,舉個例子,我的宿主機是Windows,用VirtualBox搭的集群,我想在windows上使用Eclipse進行編程,使用集群的Hadoop服務,我可不想在master上安裝Eclipse開發,雖然會省掉不少錯誤解決的麻煩事,但是是不對的!服務就是要遠程調用的)
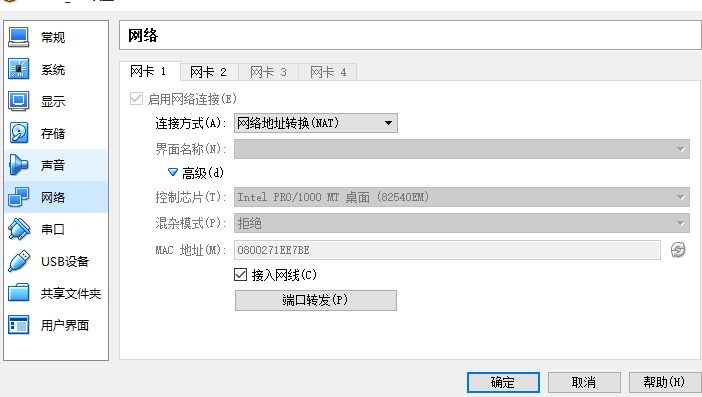
設置第一個網卡:NAT可以使虛擬機使用宿主機的IP上網,這樣,你的虛擬機就可以缺什么軟件就安什么了,方便!
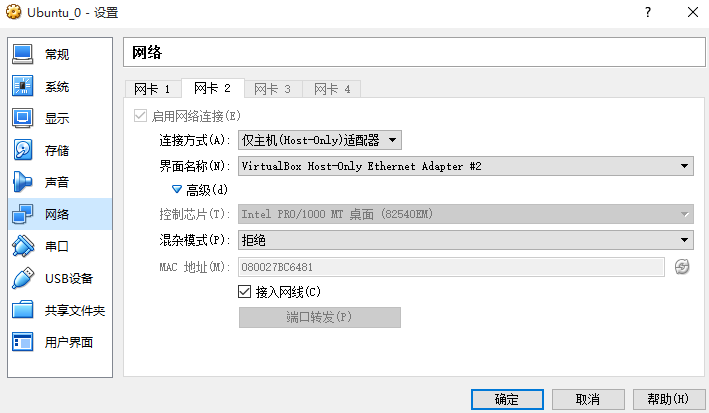
接下來設置第二個網卡:這使得宿主機能夠ping通虛擬機
二.克隆虛擬機
選中第一臺ubuntu_0(一定要關閉它),你會發現右側的綿羊 (你應該知道為啥是綿羊吧)圖標是可以點擊的,我現在用著集群呢,懶得關,索性找張別人的圖,點開后的樣子是這樣的:
(你應該知道為啥是綿羊吧)圖標是可以點擊的,我現在用著集群呢,懶得關,索性找張別人的圖,點開后的樣子是這樣的:
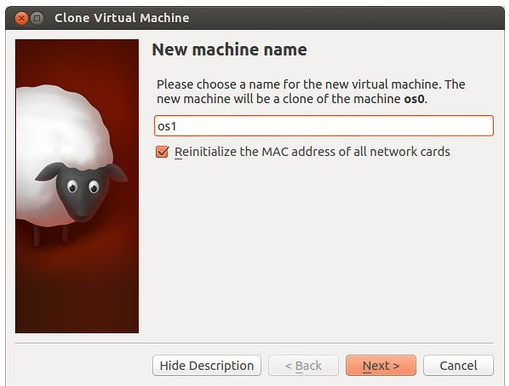
注意要重置網卡設置,命名隨便了。我一共clone了3個虛擬機,名字分別是Ubuntu_1,Ubuntu_2,Ubuntu_3,“完全復制”,一直點確定。
三.設置虛擬機靜態IP
為啥要設置呢?虛擬機默認是DHCP的,如果你搭建Hadoop集群,不能總是讓Hadoop集群所在的機器啟動一次就換一次IP吧,那麻煩了。所以,設置靜態IP很有必要。
我對網絡這塊迷糊,我就說我的方法了。
下面的操作適用于所有4個虛擬機。
sudo gedit /etc/network/interfaces
在
auto lo iface lo inet loopback
下加入:
auto eth2 #這是第二塊網卡 iface eth2 inet static
address 192.168.99.101 #在終端輸入ifconfig查看下,然后每臺機器這個地址最后一段(共四段)自增1(這四臺機器是101(用作master),100,102,103(這三個用作slave)) netmask 255.255.255.0 #ifconfig gateway 10.0.2.2 # route查看,第一行就是
靜態IP弄好了,接下來,就是設置主機名了。
命令:
sudo gedit /etc/hostname
命令:
sudo gedit /etc/hosts
修改成需要的主機名(我這里是linux0-cloud,linux1-cloud,linux2-cloud,linux3-cloud),重啟?等下,還沒完事呢。
接下來修改hosts文件:
為什么要設置hosts,hosts是干嘛的,我的理解是,根據主機名找IP,所以呢,
修改所有虛擬機的hosts文件, 命令:sudo gedit /etc/hosts。設置為如圖所示:
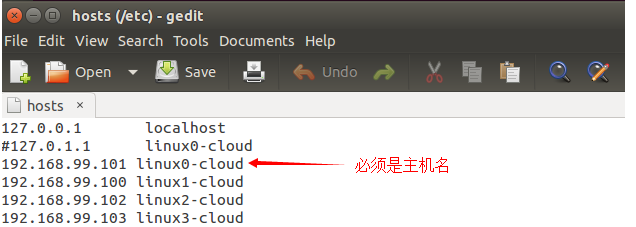
以上操作四臺機器必須都應用!好了,重啟吧!
四.安裝SSH,使得master可以無密碼登錄所有slave節點(不解釋原因)
所有主機安裝ssh
命令:
sudo apt-get install ssh
在master節點上,
命令:
ssh-keygen -t rsa -P "" cat .ssh/id_rsa.pub >>.ssh/authorized_keys,
使用ssh localhost查看是否能夠無密碼登錄
下面會進行master在無密碼情況下ssh連接到slave節點
其他所有節點執行命令:
ssh-keygen -t rsa -P ""
接下來,只要將master的公鑰放到其它slave節點即可使用無密碼登錄ssh節點
將master .ssh/authorized_keys使用scp命令拷貝到其它slave節點上,做到master訪問slave不需要密碼(如果slave訪問master,那么過程相反)
在master上執行命令:
scp .ssh/authorized_keys linux1@linux1-cloud:~/.ssh/authorized_keys scp .ssh/authorized_keys linux1@linux2-cloud:~/.ssh/authorized_keys scp .ssh/authorized_keys linux1@linux3-cloud:~/.ssh/authorized_keys
五.安裝Hadoop2.7.1
下面先對master節點進行配置,然后將配置好的文件復制到其余機器上
在master上
新建目錄,命令:mkdir ~/hadoop
解壓hadoop,命令:tar xvf ~/Downloads/hadoop-2.7.1.tar.gz -C ~/hadoop
新建hdfs文件夾(不能使用sudo創建,權限問題):
mkdir ~/dfs mkdir ~/dfs/name mkdir ~/dfs/data mkdir ~/tmp
修改hadoop/hadoop-2.7.1/etc/hadoop/hadoop-env.sh配置文件 ,
export JAVA_HOME=/usr/local/java/jdk1.8.0_60
修改/etc/hadoop/slaves文件:
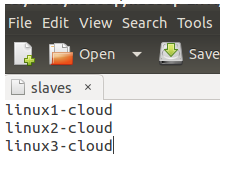
修改/etc/hadoop/core-site.xml文件,
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://linux0-cloud:8020</value> </property> <property> <name>io.file.buffer.size</name> <value>131072</value> </property> <property> <name>hadoop.tmp.dir</name> <value>/home/linux1/tmp</value> <description>Abase for other temporary directories.</description> </property> </configuration>
修改/etc/hadoop/hdfs-site.xml文件,
<configuration> <property> <name>dfs.namenode.secondary.http-address</name> <value>linux0-cloud:9001</value> <description> 這里使namenode同時作為secondary namenode,實際應該設置其他機器的比如linux1-cloud:9001 你可以訪問linux0-cloud:50070也可以訪問linux0-cloud:9001(或者其他比如:linux1-cloud:8001)查看hadoop概況(namenode們狀態是同步的) </description> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/home/linux1/dfs/name</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/home/linux1/dfs/data</value> </property> <property> <name>dfs.replication</name> <value>3</value> </property> <property> <name>dfs.webhdfs.enabled</name> <value>true</value> </property> </configuration>
修改etc/hadoop/mapred-site.xml,
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> <property> <name>mapreduce.jobhistory.address</name> <value>linux0-cloud:10020</value> </property> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>linux0-cloud:19888</value> </property> </configuration>
修改yarn-site.xml文件,
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> <property> <name>yarn.resourcemanager.address</name> <value>linux0-cloud:8032</value> </property> <property> <name>yarn.resourcemanager.scheduler.address</name> <value>linux0-cloud:8030</value> </property> <property> <name>yarn.resourcemanager.resource-tracker.address</name> <value>linux0-cloud:8031</value> </property> <property> <name>yarn.resourcemanager.admin.address</name> <value>linux0-cloud:8033</value> </property> <property> <name>yarn.resourcemanager.webapp.address</name> <value>linux0-cloud:8088</value> </property> </configuration>
下面將hadoop復制到其它slave節點:
命令:
sudo scp -r ~/hadoop linux1@linux1-cloud:~/ sudo scp -r ~/hadoop linux1@linux2-cloud:~/ sudo scp -r ~/hadoop linux1@linux3-cloud:~/
設置所有節點環境變量:
gedit ~/.bashrc
添加:
export HADOOP_HOME=/home/linux1/hadoop/hadoop-2.7.1 export HADOOP_MAPRED_HOME=$HADOOP_HOME export HADOOP_COMMON_HOME=$HADOOP_HOME export HADOOP_HDFS_HOME=$HADOOP_HOME export YARN_HOME=$HADOOP_HOME export HADOOP_YARN_HOME=$HADOOP_HOME export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop export YARN_CONF_DIR=$HADOOP_HOME/etc/hadoop export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
應用環境變量:
source ~/.bashrc
六.啟動Hadoop
首先格式化:
hdfs namenode -format
啟動hdfs:
start-dfs.sh
啟動yarn:
start-yarn.sh
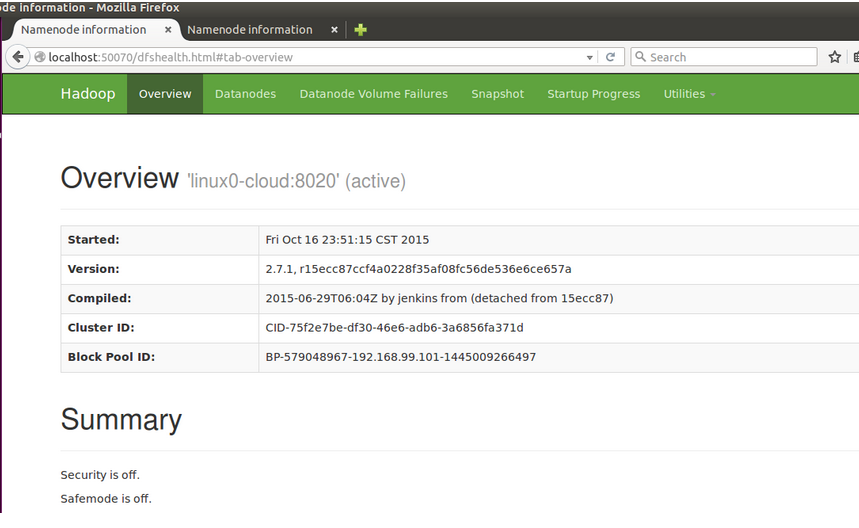
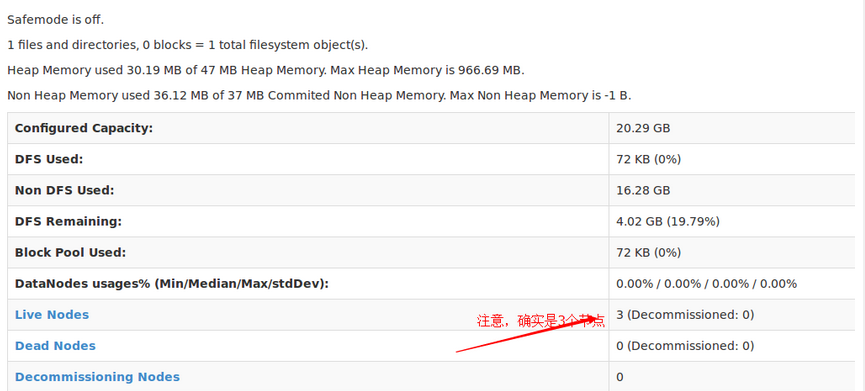
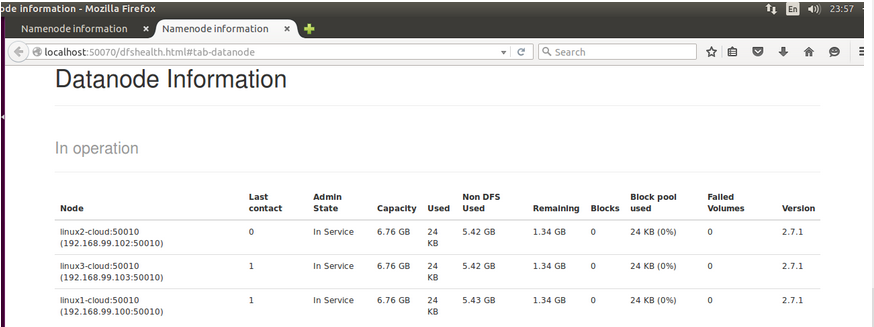
你也可以輸入192.168.99.101:50070訪問,不給你們截圖,宿主機瀏覽器有不少標簽
看完上述內容,你們對如何在window上使用VirtualBox搭建Ubuntu15.04全分布Hadoop2.7.1集群有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





