溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
一、hive在執行sql時會以mapreduce的方式對數據進行接入和處理,其主要包含以下幾個階段:
1.hive首先根據sql語句中的表從hdfs文件中獲取數據,對數據文件進行split操作,使其可以一行一行將所需數據讀入內存;
2.map函數將內存中的數據按照key值進行映射,形成一行一行的key-value值,比如用戶表中的性別字段,內存中map處理后的記錄如下: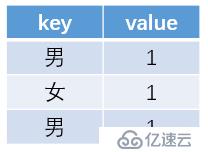
3.在實際應用中會有多臺機器參與map處理,map完成后需要將帶有相同key的數據分發到同一臺集群去進行后續處理,此時的操作稱為shuffle;
4.如果sql中包含有join、count、sum,此時還會進行reduce操作,比如count,其完成reduce后數據情況如下: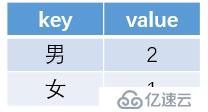
二、在hive底層,同時還會將上面的sql進行編譯,其過程主要包含以下六點: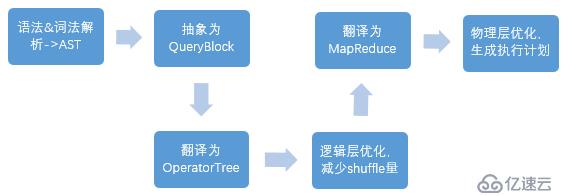
為便于理解,我們拿一個簡單的查詢語句進行展示,對5月30號的地區維表進行查詢:
select * from dim.dim_region where dt = '2019-05-30'1.根據Antlr定義的sql語法規則,將相關sql進行詞法、語法解析,轉化為抽象語法樹AST Tree
ABSTRACT SYNTAX TREE:
TOK_QUERY
TOK_FROM
TOK_TABREF
TOK_TABNAME
dim
dim_region
TOK_INSERT
TOK_DESTINATION
TOK_DIR
TOK_TMP_FILE
TOK_SELECT
TOK_SELEXPR
TOK_ALLCOLREF
TOK_WHERE
=
TOK_TABLE_OR_COL
dt
'2019-05-30'2.遍歷AST Tree,抽象出查詢的基本組成單元QueryBlock
AST Tree生成后由于其復雜度依舊較高,不便于翻譯為mapreduce程序,需要進行進一步抽象和結構化,形成QueryBlock。QueryBlock是一條SQL最基本的組成單元,包括三個部分:輸入源,計算過程,輸出。簡單來講一個QueryBlock就是一個子查詢。QB的生成過程為一個遞歸過程,先序遍歷 AST Tree ,遇到不同的Token 節點(理解為特殊標記),保存到相應的屬性中,主要包含以下幾個過程:
3.遍歷QueryBlock,翻譯為執行操作樹OperatorTree
Hive最終生成的MapReduce任務,Map階段和Reduce階段均由OperatorTree組成。邏輯操作符,就是在Map階段或者Reduce階段完成單一特定的操作。
基本的操作符包括TableScanOperator,SelectOperator,FilterOperator,JoinOperator,GroupByOperator,ReduceSinkOperator
ReduceSinkOperator將Map端的字段組合序列化為Reduce Key/value, Partition Key,只可能出現在Map階段,同時也標志著Hive生成的MapReduce程序中Map階段的結束。
Operator在Map Reduce階段之間的數據傳遞都是一個流式的過程。每一個Operator對一行數據完成操作后之后將數據傳遞給childOperator計算。
由于Join/GroupBy/OrderBy均需要在Reduce階段完成,所以在生成相應操作的Operator之前都會先生成一個ReduceSinkOperator,將字段組合并序列化為Reduce Key/value, Partition Key。
4..Logical Optimizer對OperatorTree進行優化操作
使用ReduceSinkOperator,減少shuffle數據量。大部分邏輯層優化器通過變換 OperatorTree ,合并操作符,達到減少 MapReduce Job ,減少 shuffle 數據量的目的。
5.遍歷OperatorTree,并翻譯為MapReduce任務
OperatorTree 轉化為 Task tree的過程分為下面幾個階段
對輸出表生成 MoveTask
從 OperatorTree 的其中一個根節點向下深度優先遍歷
ReduceSinkOperator 標示 Map/Reduce 的界限,多個 Job 間的界限
遍歷其他根節點,遇過碰到 JoinOperator 合并 MapReduceTask
生成 StatTask 更新元數據
剪斷 Map 與 Reduce 間的 Operator 的關系
6.物理層優化器對MapReduce任務進行優化,生成最終的執行計劃
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





