溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章為大家展示了可行的 JavaScript 高速緩存區攻擊,內容簡明扼要并且容易理解,絕對能使你眼前一亮,通過這篇文章的詳細介紹希望你能有所收獲。
##摘要
我們將展示首個完全運行在瀏覽器里的針對微架構的邊信道攻擊手段。與這個領域里的其它研究成果不同,這一手段不需要攻擊者在受害者的電腦上安裝任何的 應用程序來展開攻擊,受害者只需要打開一個由攻擊者控制的惡意網頁。這種攻擊模型可伸縮性高,易行,貼近當今的網絡環境,特別是由于絕大多數桌面瀏覽器連接到 Internet 因此幾乎無法防御。這種攻擊手段基于 Yarom 等人在 文[23] 提出的 LLC攻擊,可以讓攻擊者遠程獲得屬于其它進程、用戶甚至是虛擬機的信息, 只要它們和受害者的瀏覽器運行在運行在同一臺物理主機上。我們將闡述這種攻擊背后的基本原理,然后用一種高帶寬的隱藏通道驗證它的效果,最后 用它打造了一個覆蓋整個系統的鼠標和網絡活動記錄器。抵御這種攻擊是可能的,但是所需的反制措施對瀏覽器和電腦的正常使用所產生的代價有點不實際。
##1 引言
邊信道分析是里一種非常強大的密碼分析攻擊。攻擊者通過分析安全設備內部在進行安全運算時所產生的的物理信號(功率,輻射,熱量等)來取得秘密信息[15]。 據說在二戰中便有情報部門在使用,Kocher 等人在1996年首次在學術情境下討論了這個問題[14]。邊信道分析被證實可以用來侵入無數的現實世界中的系統,從汽車報警器 到高安全性的密碼協處理器[8][18]。緩存攻擊(Cache Attack)是和個人電腦相關的一種邊信道攻擊,因為高速緩沖區被不同的進程和用戶使用而導致了信息的泄露[17][11]。
雖然邊信道攻擊的能力無可置疑,但是要實際應用到系統上還是相對受限的。影響邊信道攻擊可行性的一個主要因素是對不確定的攻擊模型的假設:除了基于網絡的 時序攻擊,大部分的邊信道攻擊都要求攻擊者非常接近受害者。緩存攻擊一般會假設攻擊者能夠在受害者的機器上執行任意的二進制的代碼。雖然這個假設 適用于像 Amazon 云計算平臺這樣的 IaaS 或者 PaaS 環境,但是對于其它環境就不那么貼切了。
在這篇報告里,我們用一種約束更少、更可行的攻擊者模型挑戰了這一限制性的安全假設。在我們的攻擊模型里,受害者只需要訪問一個網頁,這個網頁 由攻擊者所擁有。我們會展示,即使在這么簡單的攻擊者模型里,攻擊者依然能夠在可行的時間周期里,從被攻擊的系統中提取出有意義的信息。為了和這樣的 計算設定保持一致,我們把注意力集中在了跟蹤用戶行為而不是獲取密匙上。報告中的攻擊方式因此是高度可行的:對于攻擊者的假設和限定是 實際的;運行的時間是實際的;給攻擊者帶來的好處也是實際的。據我們了解,這是首個可以輕松擴展至上百萬個目標的邊信道攻擊方式。
我們假設攻擊中受害者使用的個人電腦配備有較新型號的的 Intel CPU ,并進一步假設用戶用支持 HTML5 的瀏覽器訪問網頁。這覆蓋了絕大部分連接到 Internet 的 個人電腦,見 章節5.1 。用戶被強迫訪問一個頁面,這個頁面上有一個由攻擊者控制的元素比如廣告。攻擊代碼自己會執行基于 JavaScript 的 緩存攻擊,見 章節2,持續地訪問被攻擊系統的 LLC 。因為所有的 CPU 內核,用戶,進程,保護環等共享同一個高速緩存區,所以可為攻擊者提供被攻擊用戶和系統的詳細信息。
###1.1 現代 Intel CPU 的內存架構 現代的計算機系統通常會采用一個高速的中央處理器(CPU)和一個容量大但是速度較慢的隨機存取器(RAM)。為了克服這兩個模塊的性能鴻溝,現代的計算機系統會采用 高速緩存 - 一種容量小但是速度更快的內存結構,里面保存了 RAM 中最近被 CPU 訪問過的子集。高速緩存通常會采用** 分層** 設計,即在 CPU 和 RAM 之間 分層 放置一些列逐漸變大和變慢的內存結構。圖1 取自 文[22],展示了 Intel Ivy Bridge 的緩存結構,包括:較小的 level 1(L1) cache,大一些的** level 2 (L2) cache **,最下方是最大的 level 3 (L3) cache 并和 RAM 相連。Intel 目前代號為 Haswell 的新一代 CPU 采用了另一種嵌入式的 DRAM(eDRAM) 設計,所以不在本文討論范圍內。如果 CPU 需要訪問的數據當前不在緩存里,會觸發一個 未命中 ,當前緩存里的一項必須被 **淘汰 **來給新元素騰出空間。
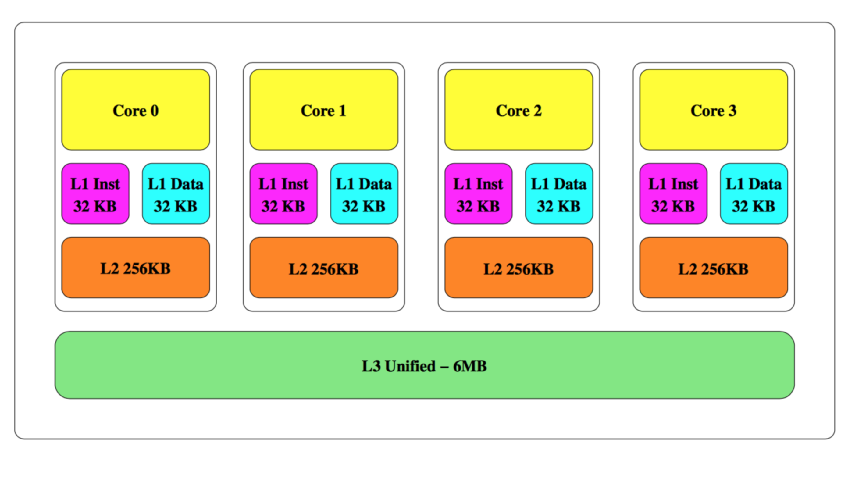 圖1:Intel Ivy Bridge
圖1:Intel Ivy Bridge
Intel 的緩存微架構是 **嵌套的 **- 所有一級緩存里的數據必須同時存在二級和三級緩存里。倒過來,如果某個元素在三級緩存里被淘汰,那它也會立刻被 從二級和一級緩存里移走。需要注意的是 AMD 緩存微架構的設計是非嵌套的,所以本文描述的方法并不能立刻應用到該平臺上。
本文重點關注第三級緩存,通常也被稱為 LLC。由于 LLC 較大,CPU 訪問內存的時候如果把整個 LLC 的內容都搜索一遍效率會很低。 為了避免這個問題,LLC 通常被分成不同的 組,每一組都對應者內存空間的一個固定的子集。每個組包含若干緩存線。例如,Intel Haswell 系列中的 Core i7-3720QM 處理器擁有 8192 = 2^13 個組,每個組有 12 條 64 = 2^6 字節的緩存線,共同組成 8192 x 12 x 64 = 6 MB 的高速緩存。 CPU 如果要檢查一個給定的物理地址是否在三級緩存里,會先計算出組,然后只檢查組內的緩存線。結果就是,某個物理地址的緩存未命中,會導致同一個組的 為數不多的緩存線中的一條被淘汰,這個事實會被我們的攻擊反復運用。由64比特長度的物理地址到13比特長度的組索引的映射方法已經被 Hund 等人在2013年 通過逆向工程得出來[12]。在表示物理地址的64個比特位里,5到0被忽略,16到6被直接用來作為組索引的低11位,63到17散列后得到組索引的高2位。 LLC 被所有的內核、線程、進程、用戶,乃至運行在同一塊 CPU 芯片上的虛擬機所共享,而不論特權環或其它類似的保護措施。
現代的個人電腦采用了一種 虛擬內存機制,在這種機制里,用戶進程一般無法直接得到或訪問系統的物理內存。取而代之的是,進程會被分配不同的虛擬內存頁。 如果某個虛擬內存頁被當前執行的進程訪問,操作系統會在物理內存里動態地分配一個頁框。CPU 的內存管理單元(MMU)負責把不同進程對虛擬內存地址的訪問 映射到物理內存。Intel 處理器的頁和頁框大小一般是4KB,并且頁和頁框的是按照頁對齊的 - 每頁的開始地址是頁大小的倍數。這意味著,任何虛擬地址 的低12位和對應的虛擬地址是一一對應的,這一事實也在我們的攻擊中用到。
###1.2 緩存攻擊 緩存攻擊是針對微架構的攻擊手段中一個典型的代表, Aciamez 在他的出色的調查中將這類攻擊定義為利用 “信任架構邊界下方的底層處理器結構” 從不同的安全系統中 獲取秘密信息。緩存攻擊基于這樣的事實:盡管在上層有諸多像沙箱、虛擬內存、特權環,宿主這樣的保障機制,安全和不安全進程通過高速緩存區的共用可以互相影響。 攻擊者構造一個“間諜”進程后可以通過被共用的緩存來測量和干擾其它安全進程的內部狀態。Hu 在1992年的首次發現[11],在隨后的一些研究成果里顯示了邊信道攻擊可被用來獲取 AES密匙[17][4],RSA密匙[19],甚至可以允許一臺虛擬機侵入宿主上的其它機器。
我們的攻擊建立在 填充+探測 模型的基礎上,這個方法由 Osvik 在[17]中首次描述,不過是針對一級緩存的。之后由 Yarom 等人在[23]中擴展到啟用了 較大內存頁系統的 LLC。我們把這個方法擴展了一下支持更加常見的 4K 的頁大小。總的來說,填充+探測有四個步驟。第一步,攻擊者建立一個 或多個** 移除集**。移除集是內存中的一系列地址,這些地址被訪問的時候會占據受害者進程使用的一條緩存線。第二步,攻擊者通過訪問移除集填充整個組。 這會強制受害者的代碼或指令被從組中淘汰,并使組進入一個已知的狀態。第三步,攻擊者觸發或只是等待受害者執行和可能使用組。最后,攻擊者通過再次訪問移除集來探測組。如果訪問的延遲比較低,意味著攻擊者的指令或數據還在緩存里。否則,較高的訪問延遲意味著受害者的代碼用到了組,因此攻擊者可以了解受害者的內部狀態。 實際的時間測量是用非特權的匯編指令RDTSC進行的,這個指令可以得到處理器非常準確的周期數。再次遍歷鏈表還有第二個目的,那就是強制組進入 受攻擊者控制的狀態,為下一輪的測量做好準備。
###1.3 Web 運行環境 JavaScript 是一種擁有動態類型,基于對象的運行時求值的腳本語言,它支撐著現代互聯網的客戶端。JavaScript 代碼以源碼的形式傳到瀏覽器端,由瀏覽器 即時編譯(JIT) 機制來編譯和優化。不同瀏覽器廠商之間的激烈競爭使不斷改進 JavaScript 性能備受關注。結果就是,在某些場景下,JavaScript 執行的效率已經 可以和機器語言相媲美。
JavaScript 語言的核心功能是由 ECMA 產業協會在 ECMA-262 標準中定義的。語言標準由萬維網協會(W3C)定義的一系 API 所補充,因此適合開發 Web 內容。 JavaScript API 的集合是不斷演進的,瀏覽器廠商依照自己的開發計劃不斷增加新的 API 支持。我們的工作中用到兩個具體的API: 第一個是類型數組的定義9,通過它可以高效地訪問非結構化的二進制數組。 第二個是高精度時間API16,讓應用程序可以進行毫秒以下時間的測量。 如 章節5.1 所示,大部分當今主流的瀏覽器都同時支持這兩個API。
JavaScript 代碼運行在高度沙箱化的環境里 - 用 JavaScript 交付的代碼對系統的訪問非常受限。例如,JavaScript 代碼如果沒有用戶的允許不能打開和讀取文件。 JavaScript 代碼不能執行機器語言或者加載本地的代碼庫。 最值得注意的是,JavaScript 代碼沒有指針的概念,所以你連一個 JavaScript 變量虛擬地址都沒法知道。
###1.4 我們的工作 我們的目的是構造一個可以通過 Web 部署的 LLC 攻擊。這個過程是充滿挑戰的,因為 JavaScript 代碼沒法加載共享庫或者執行本機語言的程序, 并且由于無法直接調用專用的匯編指令而被迫調用腳本語言的函數進行時間的測量。盡管有這些挑戰,我們還是成功地把緩存攻擊擴展到了基于 Web 環境:
我們展示了一種用來在 LLC 上的建立 非典型移除集 特別方法。與[23]不同,我們的方法不要求系統配置成支持較大的內存頁,所以能夠很快的 應用到廣泛的桌面和服務器系統。我們展示了該方法雖然是使用 JavaScript 實現的,但是依然可以在實際的時間周期里完成。
我們展示了一種 功能完善的用無需特權的 JavaScript 發動 LLC 攻擊 的方法。我們用隱藏通道的方式,評估了它的性能,包括在同一個機器、不同進程之間 和在虛擬機與它的主機之間。基于 JavaScript 的通道與[23]中用機器語言實現的方法類似,都可以達到每秒幾百 kb 的速度。
我們展示了怎么利用基于緩存的方法來有效地跟蹤用戶行為。緩存攻擊的這一應用與我們的攻擊模型更相關,這與密碼分析在其它成果中的應用不同。
最后,我們分析了針對攻擊可能的反制措施和整個系統的代價。
文檔結構: 第二章,攻擊方法不同階段的設計與實現。 第三章,基于攻擊方法建立起來的隱藏通道,這個通道也被用來驗證方法的性能。 第四章,緩存攻擊如何被用來跟蹤用戶在瀏覽器內外的行為。 第五章,總結,提出反制措施和仍未解決的研究挑戰。
##2 攻擊方法
正如前文所訴,一次成功的 填充+探測 攻擊包含幾個步驟:為一個或多個相關組建立移除集,填充緩存,觸發受害者的操作,最后再次探測組。 雖然填充和探測實現起來很簡單,但是要找到對應于某個系統操作的組并且為它建立移除集就不那么容易了。在本章里,我們描述了這幾個步驟用 JavaScript 如何實現。
###2.1 建立一個移除集 ####2.1.1 設計 正如[23]寫到,填充+探測攻擊方法的第一步是為某個與被攻擊進程共享的組建立一個移除集。這個移除集包含一系列的變量,而且這些變量都被 CPU 映射到相同的 組里。根據 文[20] 的建議,使用鏈表可以避免 CPU 的內存預讀和流水線優化。我們首先展示如何為任意一個組建立一個移除集,然后解決尋找與受害者共享組的問題。
文[17]指出,一級緩存是依據虛擬地址的低位的比特來決定組分配的。假設攻擊者知道變量的虛擬地址,那么在基于一級緩存的攻擊模型里建立移除集很容易。 但是,LLC 里變量的組分配是依照物理內存的地址進行的,而且一般情況下,非特權進程無法知道。文[23]的作者為了規避這個問題,假設系統用的是 頁較大的模型,在這個模型里,物理地址和虛擬地址的低21位是相同的,并通過迭代算法來獲得組索引的高位。
在我們所考慮的攻擊模型里,系統運行在 4K 的頁大小模型下,物理地址和虛擬地址只有最低的12位是相同的。然而更大的難題是,JavaScript沒有指針的概念, 所以即使是自己定義的變量,虛擬地址也是不知道的。
從64位物理地址到13位的組索引的映射關系已經被 Hund 等人研究過[12]。他們發現,當訪問物理內存里一段連續的、8MB大小的 “淘汰緩沖區” 時會讓三級緩存里的所有組 都失效。雖然我們在用戶態下沒有辦法分配這樣的一個“淘汰緩沖區” (實際上,文章[12]是通過內核模式的驅動實現的),我們用 JavaScript 在 虛擬內存里分配了一個 8MB 大小的數組(這其實是由系統分配的隨機、不連續的 4K 大小物理內存頁的集合),然后測量遍歷這個緩沖區在全系統造成的影響。 我們發現在迭代訪問了這個淘汰緩沖區后如果立即訪問內存中其它不相關的變量,訪問的延遲會顯著的增加。 另外一個發現是,即使不訪問整個緩沖區而是每隔64字節去訪問它,這個現象依然存在。但是,我們所訪問的 131K 個偏移值到8192個可能的組的映射關系 并沒有立刻清晰起來,因為我們不知道緩沖區里各個頁在物理內存中的地址。
解決這個問題一個不太靠譜的做法是,給定一個任意的“受害者”在內存中的地址,通過暴力手段從 131K 個偏移值中找到12個與這個地址共享組的地址。要完成這點, 我們可以從 131K 個偏移量中選取幾個作為子集,在迭代了所有的偏移量后再測量下訪問的延遲有沒有變化。如果延遲增加了,意味著含有12個地址的子集與 受害者地址共享相同的組。如果延遲沒有變化,那子集里的12個地址中的任何一個都不在組里,這樣受害者地址就還在緩存里。把這個過程重復8192遍,每次用 一個不同的受害者地址,我們就可以識別每個組并且建立自己的數據結構。
受此啟發而立刻寫出來的程序會運行非常長的時間。幸運的是, Intel MMU 的頁幀大小(章節1.1)非常有幫助,因為虛擬地址是頁對齊的,每個虛擬地址的 低12位和每個物理地址的低12位是一致的。據 Hund 等人所稱,12個比特中的6個被用來唯一決定組索引。因此,淘汰緩沖區中的一個偏移會和其它 8K 個偏移 共享12到6位,而不是所有 131K 個。此外,只要找到一個組就能立刻知道其它的63個在相同頁幀里的組的位置。再加上 JavaScript 分配大的數據緩存區的時是 和頁幀的邊界對齊的,所以可以用算法1中的貪心算法。
算法1 Profiling a cache set Let S be the set of unmapped pages, and address x be an arbitrary page-aligned address in memory
1. Repeat k times: (a) Iteratively access all members of S (b) Measure t1 , the time it takes to access x (c) Select a random page s from S and remove it (d) Iteratively access all members of S\s (e) Measure t2 , the time it takes to access x (f) If removing page s caused the memory access to speed up considerably (i.e., t1 ? t2 > thres), then this page is part of the same set as x. Place it back into S. (g) If removing page s did not cause memory access to speed up considerably, then this address is not part of the same set as x. 2. If |S| = 12, return S. Otherwise report failure.
通過多次運行 算法1,我們可以逐漸的建立一個移除集并覆蓋大部分的緩存,除了那些被 JavaScript 運行時本身所使用的。我們注意到, 與[23]中的算法建立的淘汰緩沖區不同,我們的移除集是非典型的 - 因為 JavaScript 沒有指針的概念,所以如果我們發現了一個移除集 我們并沒有辦法知道它對應著 CPU 高速緩存的哪個組。此外,在相同的機器上每次運行這個算法都會得到不同的映射。這也許是因為用了傳統的 4K 頁大小 而不是 2MB 的頁大小的原因,這個問題即使不用 JavaScript 用機器語言也存在。
####2.1.2 驗證 我們用 JavaScript 實現了 算法1 并且在安裝了 Ivy Bridge, Sandy Bridge,Haswell 系列 CPU 的機器上進行驗證,機器上裝有 Safari 和 Firefox 對應運行在 Mac OS Yosemite 和 Ubuntu 14.04 LTS 操作系統上。系統并沒有被配置使用大的頁而是用默認的 4K 頁大小。列表1 顯示了實現 算法1.d 和 算法1.e 的代碼,展示了 JavaScript 下怎么遍歷鏈表和測量時間。算法如果要運行在 Chrome 和 Internet Explorer 下,需要額外的幾個步驟,在 章節5.1 中。
列表1
// Invalidate the cache set
var currentEntry = startAddress;
do {
currentEntry = probeView.getUint32(currentEntry);
} while (currentEntry != startAddress);
// Measure access time
var startTime = window.performance.now();
currentEntry = primeView.getUint32(variableToAccess);
var endTime = window.performance.now();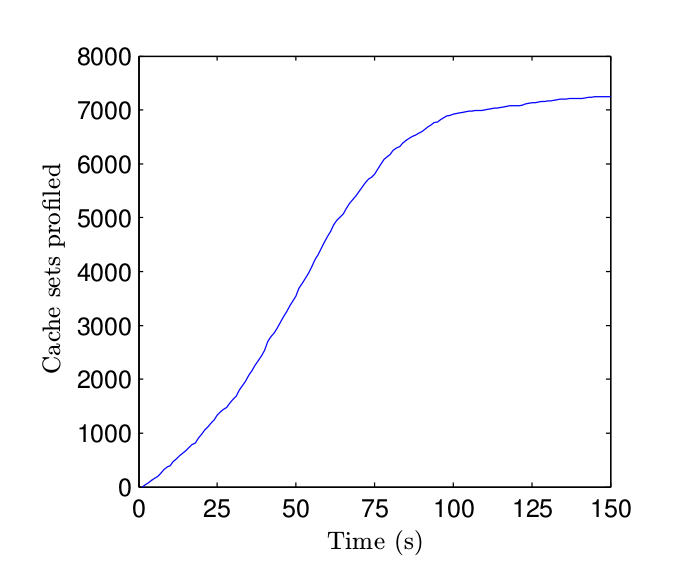 圖2 性能分析算法的累積表現
圖2 性能分析算法的累積表現
圖2顯示了性能分析的結果,運行在 Intel i7-3720QM CPU 上, 裝有 Firefox 35.0.1 和 Mac OS 10.10.2 。我們很高興地發現在30秒內就 映射了超過25%的組,1分鐘內就達到了50%。這個算法想要并行運行是非常簡單的,因為大部分的執行時間花在了數據結構的維護上,只有一小部分花在讓緩存失效和 測量上。整個算法用不到500行 JavaScript 代碼就可以完成。
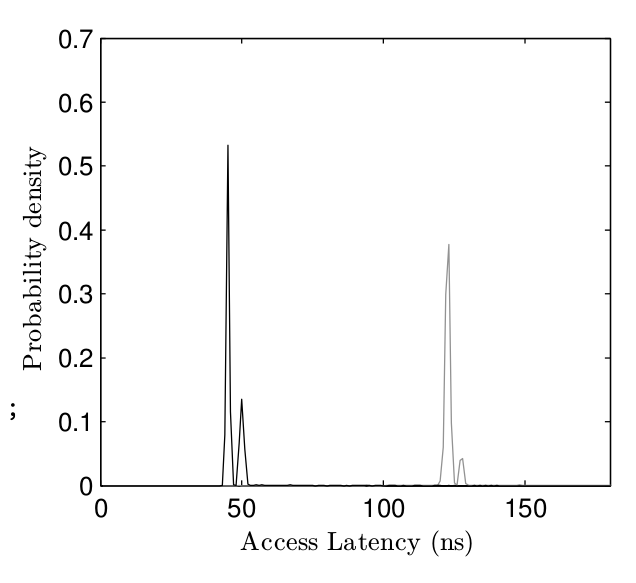 圖3 Haswell 上兩種方法訪問延遲的概率分布
圖3 Haswell 上兩種方法訪問延遲的概率分布
為了驗證我們的算法能夠辨別不同的組,我們設計了一個實驗來比較一個變量被 flush 前后的訪問延遲。圖3 顯示了兩種方式訪問變量的概率分布函數。 灰色的代表用我們的方式從緩存中 flush 出去的變量的訪問時間;而黑色是駐留在緩存里的變量的訪問時間。時間的測量用到 JavaScript 的高精度計時器, 所以還包括了 JavaScript 運行時的延遲。兩者的不同是顯而易見的。圖4 顯示的是在較早版本的 Sandy Bridge CPU 上捕捉到的結果,該型號每個組有16個條目。
通過選取一些列的組,并且不斷的測量它們的訪問延遲,攻擊者可以獲得緩存實時活動非常詳細的圖。我們把這種視覺呈現稱作 “內存譜圖”,因為它看起來很像聲音的譜圖。
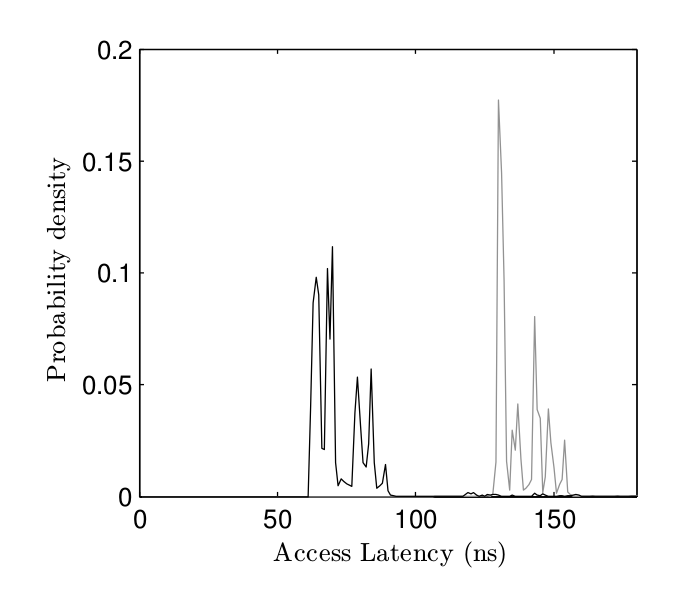 圖4 Sandy Bridge 上兩種方法訪問延遲的概率分布
圖4 Sandy Bridge 上兩種方法訪問延遲的概率分布 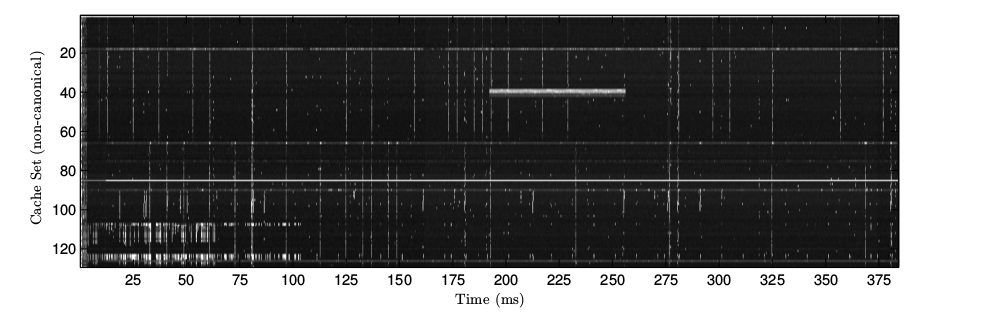 圖5 內存譜圖示例 圖5顯示的是每隔400ms抓取一次的內存譜圖。其中X軸對應時間,Y軸對應不同的組。例子中的時間分辨率是250微秒,檢測了一共128個組。每個點的密度 代表了這個組在這個時間的訪問延遲。黑色代表延遲較低,意味從上次測量到現在沒有其它進程訪問過這個組。白色意味著攻擊者的數據在上次測量之后被淘汰了。
圖5 內存譜圖示例 圖5顯示的是每隔400ms抓取一次的內存譜圖。其中X軸對應時間,Y軸對應不同的組。例子中的時間分辨率是250微秒,檢測了一共128個組。每個點的密度 代表了這個組在這個時間的訪問延遲。黑色代表延遲較低,意味從上次測量到現在沒有其它進程訪問過這個組。白色意味著攻擊者的數據在上次測量之后被淘汰了。
細看這個內存譜圖可以得到幾個顯而易見的事實。首先,雖然沒用機器語言指令而是用了 JavaScript 的計時器,測量的抖動很小,活躍和不活躍的組 很容易被區分。圖中有幾條明顯的垂直的線,意味著同一時間間隔里有多個相鄰的組被訪問。因為連續的組對應的物理內存的地址也是連續的,所以我們 相信這個信號代表著一個超過 64 字節的匯編指令。還有一些聚在一起的組被同時訪問。我們推斷這代表著變量的訪問。最后,橫著的白線預示著一個變量 被不斷地訪問。這個變量可能是屬于測量代碼的或屬于當前的 JavaScript 運行時。從一個沒有任何特權的網頁能得到這么多信息真是太了不起了。
###2.2 在緩存里識別意思的區域 移除集讓攻擊者能夠監控任意一個組的活動。因為我們得到的移除集是非典型的,因此攻擊者必須想辦法把分析過的組和受害者的數據或是代碼的地址 關聯起來。這個學習/分類的問題已經由 Zhang 和 Yarom 分別在 文章[25] 和 文章[23] 里提出了,他們采用了不同的諸如 SVM 的機器學習的算法試圖從 緩存延遲的測量數據里找到規律。
為了有效地展開學習過程,攻擊者需要誘導受害者做一些操作,然后檢查哪些組被這個操作訪問到,詳見 算法2。
Let Si be the data structure matched to eviction set i 1. For each set i: (a) Iteratively access all members of Si to prime the cache set (b) Measure the time it takes to iteratively access all members of Si (c) Perform an interesting operation (d) Measure once more the time it takes to iteratively access all members of Si (e) If performing the interesting operation caused the access time to slow down considerably, then the operation was associated with cache set i.
因為 JavaScript 受到一系列的權限限制,實現步驟(c)是很有挑戰的。與之形成對比的是 Apecechea 等人能夠用一個空的 sysenter 調用來觸發一次細小的內核操作。為了實現這個步驟,我們必須調查 JavaScript 的運行時來發現有哪些函數會觸發有意思的行為,例如文件訪問,網絡訪問,內存分配等等。 我們還對那些運行時間相對較短,不會產生遺留的函數感興趣。因為遺留可能導致垃圾回收,進而影響步驟(d)的測量。Ho 等人在 文章[10] 中已經找到了這樣的 幾個函數。另外一種方式是誘導用戶代替攻擊者執行一個特定的操作(比如在鍵盤上按一個鍵)。這個例子里的學習過程可能是結構化的(攻擊者知道受害者 將要執行的時機),也可能是非結構化的(攻擊者只能假設系統一段時間內的響應緩慢是由受害者的操作導致的)。這兩種方法都被使用,詳見 章節4。
因為我們的程序會一直檢測到由 JavaScript 運行時產生的活動,比如高性能的計時器的代碼,瀏覽器其它那些與當前執行調用無關的模塊的代碼,實際上我們 通過調用兩個相似的函數并** 對比** 它們兩次活動性能分析的結果,以此來尋找相關的組。
##3 基于高速緩存區的隱藏信道之 JavaScript 實現
###3.1 動機 正如 文章[23] 所示,LLC 訪問模式可被用來建立一個高帶寬的隱藏信道,有效的用來在同一臺宿主上的兩個虛擬機之間滲透敏感的信息。在我們的攻擊模型里, 攻擊者雖然不在同一臺宿主上的虛擬機里,而是在一個網頁中,隱藏信道的動機不一樣,但是也很有意思。
經由動機,我們假設某個安全部門在追蹤犯罪大師 Bob 的蹤跡。該部門通過釣魚項目在 Bob 的個人電腦上裝了一個被稱作 APT( Advanced Persistent Threat ) 的 軟件。APT 被設計用來記錄 Bob 的犯罪記錄并發送到部門的秘密服務器上。然而 Bob 非常的警覺,他使用了啟用了強制信息流跟蹤 (Information Flow Tracking ) [24] 的操作系統。操作系統的這一功能阻止了 APT 在訪問了可能含有用戶隱私數據的文件后再連上網絡。
在這種情況下,只要 Bob 能被誘導訪問一個由安全部門控制的網頁,這個部門就可以立刻采用基于 JavaScript 的高速緩存區攻擊。APT 可以利用基于高速緩存區 的邊信道和惡意網站通信,這樣就不用通過網絡傳輸用戶的隱私數據,進而不會觸發操作系統的信息流跟蹤功能。
這個研究案例受到了來自某個安全部門的 “RF retro-reflector” 設計的啟發,在這個設計里一臺諸如麥克風的收集器,并不會把接收到的信號直接發送出去, 而是把接受的信號調制到由一個外部 ”收集設備“ 發送給它的 “照射信號” 上去。
####3.1.1 設計 隱藏信道的設計有兩個需求:第一,保持發送端的簡單,我們尤其不想讓它執行 章節2.1 中的移除集算法。第二,因為接收端的移除集是非典型的, 它應該足夠簡單,這樣接收端就可以搜索到發送端的信號調制到了哪一個組。
為了滿足這些需求,我們的發射器/ APT 在自己的內存中分配了 4K 大小的數組,并且不斷地把收集到的數據轉換成對與這個數組的內存訪問的模式。這個 4K 大小 的數組覆蓋了緩存的 64 個組,這樣 APT 在每個時間周期里就能傳送 64比特 的數據。為了能保證內存訪問能夠被接收端定位,相同的訪問模式被重復 運用到數組的幾個拷貝上。 因此,高速緩沖區的大部分都會被執行到,與之形成對比的是 文章[23] 中的方法使用了典型的移除集,因此只會激活兩條緩存線。
接收端的代碼會對操作系統的內存做一個性能分析,然后搜索含有被 APT 調制后的數據所在的頁框。真正的數據會被從內存訪問的模式里解調出來然后傳回服務器, 整個過程都不會違背操作系統對信息流跟蹤的保護。
####3.1.2 評估 我們的攻擊模型假設發送端使用(相對較快的)機器語言編寫,而接收端是用 JavaScript 編寫。所以,我們假設整個系統性能的限制因素是惡意網站的 采樣速度。
為了評估隱藏信道的帶寬,我們寫了一個小程序用預先設定好的模式來遍歷系統的內存(即含有單詞"Usenix"的比特圖)。 接下來,我們用 JavaScript 高速緩存攻擊來嘗試尋找這一訪問模式,并測量 JavaScript 代碼所能達到的最大的頻率。
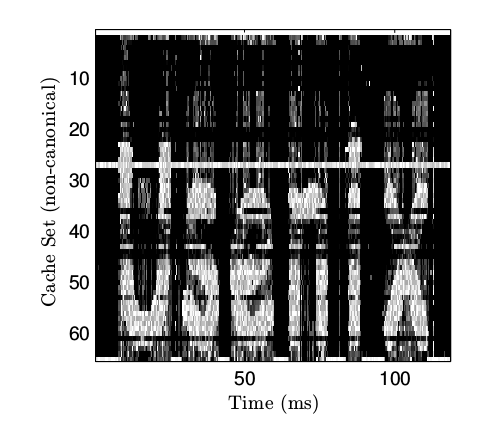 圖6 主機到主機的隱藏信道
圖6 主機到主機的隱藏信道
圖6 顯示的內存譜圖捕捉到了這一隱藏信道的執行。隱藏信道的理論帶寬通過測量大約是 320kbps,這和 文章[23] 中用機器語言實現的跨虛擬機的隱藏信道 1.2Mbps 的帶寬比較吻合。
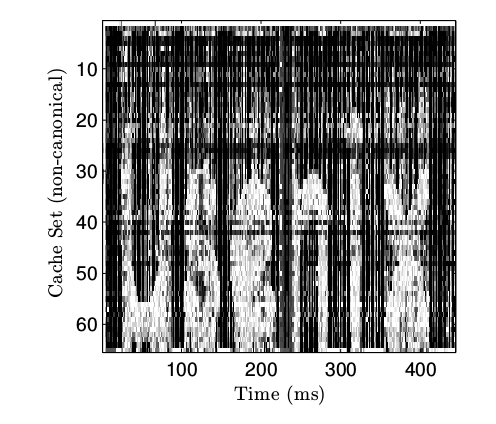 圖7 主機到虛擬機的隱藏信道 圖7 中的內存譜圖比較相似,但并不是由運行在相同主機上的接收端代碼得到的,而是在一臺虛擬機上得到的(Firefox 34 瀏覽器,Ubuntu 14.01 系統, VMWare Fusion 7.1.0 )。盡管在這個場景下的高峰頻率只能到大約 8kbps,但是一個虛擬機中的網頁竟然能夠探測到底層的硬件,這著實讓人驚訝。
圖7 主機到虛擬機的隱藏信道 圖7 中的內存譜圖比較相似,但并不是由運行在相同主機上的接收端代碼得到的,而是在一臺虛擬機上得到的(Firefox 34 瀏覽器,Ubuntu 14.01 系統, VMWare Fusion 7.1.0 )。盡管在這個場景下的高峰頻率只能到大約 8kbps,但是一個虛擬機中的網頁竟然能夠探測到底層的硬件,這著實讓人驚訝。
##4 利用高速緩存區攻擊跟蹤用戶行為
絕大多數關于高速緩存區攻擊的研究都假設攻擊者和受害者位于云計算供應商數據中心里的同一臺機器上。這樣的機器一般不會配置成接收交互式的輸入, 所以該領域的大部分研究都聚焦于如何獲得加密鑰匙或其它保密的狀態信息,譬如隨機數生成器的狀態[26]。 本文將研究怎么利用高速緩存區攻擊來跟蹤用戶的行為 ,這和我們的攻擊模型更相關。我們注意到 文章[20] 已經嘗試了利用 CPU 的一級緩存對系統負載進行細粒度的度量,以此跟蹤按鍵事件的方法。
本案例將演示一個惡意網站怎么用高速緩存區攻擊去跟蹤用戶的活動。在接下來展示的的攻擊里,我們會假設用戶在一個背景標簽頁或窗口里打開 了一個惡意網站的頁面,并且在另一個標簽頁或是另外一個完全沒有互聯網連接的應用里執行了一些敏感的操作。
我們選擇了把焦點集中在鼠標操作和網絡活動上,因為操作系統負責處理它們的代碼沒有辦法被忽略不計。所以,我們期待這些操作會在高速緩存區留下比較大的腳印。 而且正如下文所述,它們也很容易被 JavaScript 處處受限的安全模型所觸發。
###4.1 設計 兩種攻擊的結構比較類似。首先,進行性能分析,攻擊者用 JavaScript 探測每一個組。接著,在訓練階段,待檢測的活動(網絡活動或鼠標操作)被觸發, 伴隨著對高速緩存區的高精度的采樣。在訓練階段一方面通過測量腳本直接觸發網絡活動(執行一個網絡請求),另一方面是不停地在網頁上搖晃鼠標。
通過比較在訓練階段緩存區在閑時和忙時的活動,攻擊者可以知道用戶操作會對應激活哪部分的組,并且訓練出一個關于組的分類器。最后, 在分類階段,攻擊者不停地監視這些有意思的組從而掌握用戶的活動。
我們用一個基本的非結構化的訓練過程,即假設訓練過程中系統進行的最集中的操作就是被測量的。為了利用這點,我們計算了隨著時間的 每次測量的 Hamming 權重(等于在某個周期內活躍組的個數),之后應用 k-meas 算法對測量數據做聚類。 然后計算每個簇中每個組的平均訪問延遲,從而算出每個簇的中心。遇到未知的測量矢量,我們會計算這個矢量和各個中心的歐幾里得距離, 并把它歸到最近的那一類。
在分類階段,我們用命令行工具 wget 生成網絡流量,并且將鼠標移動到窗口以外。為了獲得網絡活動的真實數據,我們同時用 tcp-dump 來測量系統的流量,然后把 tcp-dump 記錄的時間戳和分類器所檢測到時間戳聯系起來。為了獲得鼠標操作的真實數據,我們寫了一個頁面記錄所有 鼠標事件及其時間戳。需要強調的是,記錄鼠標活動的頁面并不在運行著測量代碼的瀏覽器(Firefox),而是運行在另一個瀏覽器里(Chrome)。
###4.2 驗證 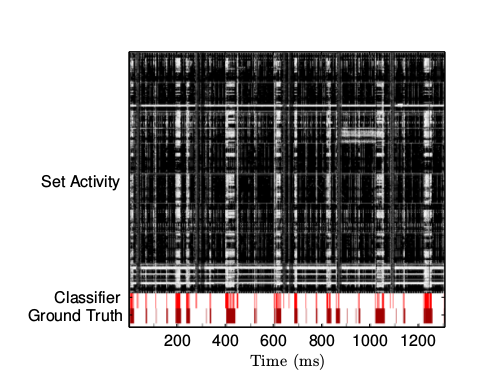 圖8 檢測到的網絡活動
圖8 檢測到的網絡活動 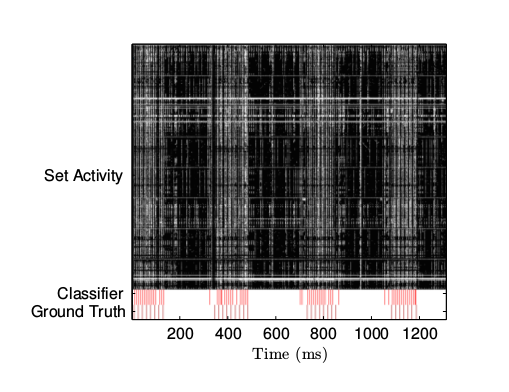 圖9 檢測到的鼠標活動
圖9 檢測到的鼠標活動
活動測量的結果見 圖8 和 圖9 。兩個圖片的頂端都顯示了高速緩存區一個子集的實時活動。圖片的底端是分類器的輸出結果和外部收集的真實數據。 正如圖片展示的那樣,我們異常簡單的分類器在識別鼠標操作和網絡活動方面非常有效。毫無疑問,使用更加 高級的訓練和分類技巧可以進一步提高攻擊的效果。需要強調的是,鼠標操作的檢測器并不會檢測網絡活動,反之亦然。
分類器的測量頻率只有 500Hz。結果就是,它沒有辦法統計單個的包,而只能說明在一個階段里活躍還是不活躍。另一方面,檢測鼠標活動的代碼要比 記錄真實數據的代碼采集到的事件多。這是因為 Chrome 瀏覽器對鼠標事件的頻率做了限制,大約是 60Hz。
Chen 等人在一篇著名的文章[5]中證明了對網絡活動的監測可以作為深度挖掘用戶行為的奠基石 。雖然 Chen 等人假設攻擊者可以在網絡層 監控受害者所有流入和流出的數據,但是這里所展示的技術本質上可以讓惡意網站監控用戶同時進行的網絡操作。攻擊可以被更多的指標增強, 例如內存分配(見文[13]),DOM 布局事件,磁盤寫操作等。
##5 結論
本文顯示了邊信道攻擊的范圍要比預期的大很多。本文提出的攻擊可針對互聯網上的大部分機器而不局限于某些特定的攻擊場景。如此眾多的系統突然間易受 邊信道攻擊意味著防止邊信道攻擊的算法和系統應當被廣泛使用,而不能只是在某些特定情況下。
###5.1 易被攻擊系統的普遍性 我們的攻擊需要一臺個人計算機,并配有 Intel CPU,使用了 Sandy Bridge, Ivy Bridge, Haswell 或者 Broadwell 的微架構。據 IDC 的數據顯示,2011年 以后售出的個人計算機80%都滿足這一條件。更進一步,假設用戶使用的瀏覽器支持 HTML5 高精度計時器和類型數組的規范。表1 列舉了各個瀏覽器廠商支持這些 API 的最早的版本和易被攻擊的版本占全球互聯網流量的比重,統計數據來自 StatCounter GlobalStatas 2015年一月份的報告。如表所示,目前市場上 80% 的瀏覽器 都無法抵御此類攻擊。
| Browser brand | High Resolution Time Support | Typed Arrays Support | Worldwide prevalence |
|---|---|---|---|
| Internet Explorer | 10 | 11 | 11.77% |
| Safari | 8 | 6 | 1.86% |
| Chrome | 20 | 7 | 50% |
| Firefox | 15 | 4 | 17.67% |
| Opera | 15 | 12.1 | 1.2% |
| Total | - | - | 83.03% |
攻擊能否取得效果取決于能不能用 JavaScript 高精度時間API 進行精準的測量。雖然 W3C 對這個API規范定義了高精度時間的單位是 “毫秒,并精確到千分之一”, 但是它并沒有給出該值的最高分辨率,實際上瀏覽器不同、操作系統不同這個值也會有所區別。舉個例子,我們在測試過程中發現 MacOS 上的 Safari 瀏覽器可以精確 到納秒,而 Windows 上的 IE 瀏覽器只能精確到 0.8 微秒。 另一方面, Chrome 瀏覽器在所有我們測試的操作系統上給出的分辨率都是 1 微秒。
所以 圖3 中,單次緩存命中和緩存未命中的差別大概是 50 納秒,性能分析和測量的腳本在時間分辨率力度更細的操作系統上要稍加改動。 在性能分析階段,我們沒有統計單次未命中的時間,而是重復讀取內存來放大時間的差別。 在測量階段,我們雖然沒有辦法放大每次緩存未命中的時間,但是我們可以利用來自相同頁框的代碼通常會讓相鄰的組失效這一點。只要同一個頁框的64個組里有20個 產生了緩存未命中,我們的攻擊就可以在哪怕是毫秒級的分辨率上進行。
我們提出的這種攻擊還可以很容易的運用到手機、平板等移動設備上。值得一提的是,安卓瀏覽器從 4.4 版本開始支持 高精度時間API 和 類型數組,但在 本文撰寫的時候 iOS Safari (8.1) 還不支持 高精度時間API。
###5.2 反制措施 本文描述的攻擊之所以可行,是因為它聚集了從微架構這一層到最終的 JavaScript 運行時設計和實現的的一些決定: 怎么把物理內存的地址映射到組, 嵌套的高速緩存區架構,JavaScript 高速的內存訪問和高精度計時器;最后是 JavaScript 的權限模型。這里的每一點上都可以采取一些緩解措施, 但是都會對系統的正常使用產生影響。
在微架構這層,修改物理內存到緩存線的映射方式可以非常有效地阻止我們的攻擊,即不再用地址底12比特中的6個直接選擇一個組。類似的,換用非嵌套的 緩存微架構而不是用嵌套的,會讓我們的代碼幾乎不肯能精確地一級緩存中淘汰某項,使得測量更加困難。然而,這兩個設計決定當初被選擇正是為了讓 CPU 的設計 和高速緩存的使用更高效,改變它們會讓其它很多的應用性能受到影響。再說了,修改 CPU 微架構可不是一件小事,因為升級已經部署的硬件是肯定不行的。
在JavaScript這層,似乎降低高精度計時器的分辨率就可以讓攻擊更難發動。但是,高精度計時器的建立是為了解決 JavaScript 開發者的實際需要的, 這些應用范圍可從音樂和游戲再到增強現實和遠程醫療。
一個可能的權宜之計是限制應用只有在獲得了用戶許可后才能訪問計時器(例如,通過顯示一個確認窗口)或者通過第三方的認可(例如下載自可信的 “app store”)。
一種有意思的方式是使用啟發式的性能分析來檢測和阻止此類攻擊。如 Wang 等人利用大量算法和按位指令的存在可以預示這密碼學應用元素 [21] 的存在, 可以注意到我們的攻擊里各種測量步驟訪問內存也會有一定的模式。因為現代的 JavaScript 的運行時,作為性能分析引導優化的機制的一部分,已經能夠 詳細的檢查代碼的運行時性能。所以 JavaScript 運行時應該能夠在執行時發現有性能分析行為的代碼并且相應的修改返回結果 (例如,在高精度計時器里加上抖動,或者動態的調整數組在內存中的位置等)。
###5.3 結論 在這篇論文里,我們展示了如何有效地通過可疑網頁發起針對微架構的邊信道攻擊,這種方式已被認為是非常有效的。 與高速緩存區攻擊一般被用于密碼分析應用不同,本文介紹了它怎么被用來有效地跟蹤用戶行為。 邊信道攻擊的范圍已被拓展,這意味著設計新的安全系統時一定要考慮到對邊信道攻擊的反制措施。
##致謝
我們很感謝激 Henry Wong 對于 Ivy Bridge 緩存淘汰策略的研究和 Burton Rosenberg 對于頁和頁框的講解。
上述內容就是可行的 JavaScript 高速緩存區攻擊,你們學到知識或技能了嗎?如果還想學到更多技能或者豐富自己的知識儲備,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





