溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Hadoop生態的組件HBase怎么搭建”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Hadoop生態的組件HBase怎么搭建”吧!
分布式表格系統對外提供表格模型,每個表格由很多行組成,通過主鍵唯一標識,每一行包含很多列。整個表格在系統中全局有序。而Google的BigTable是分布式表格系統的始祖,它采用雙層結構。底層用GFS作為持久層存儲層。而BigTable的對外的接口不怎么豐富。所以谷歌有開發出Megastore和Spanner.既提供來接口,又能處理事務.
表格中的每一行都有主鍵(Row Key)作為唯一標識。每一行又包含很多列(Column)。某一行的某一列構成一個單元(Cell),每個單元包含多個版本的數據。整體來看的話,BigTable是一個分布式多維度映射表。
(row:string,column:string,timestamp:int64)->string
多個列的話又可以構成一個列族(Column Family),所以列名就由列族(Column Family)+列名(qualifier).列族是訪問控制的單元,所以列族的話是預先定義好的,而列的話后面可以添加,數量任意.
存儲結構如圖(邏輯視圖):

存儲結構如圖(物理視圖):

行主鍵是任意的字符串,但是大小不能超過64KB。按主鍵排序,而主鍵是字典序.所以網址接近剛好可以排列在一塊.
HBase開源山寨版BigTable. 基于Hadoop的分布式文件系統HDFS之上。然后HDFS和HBase是有什么區別呢?
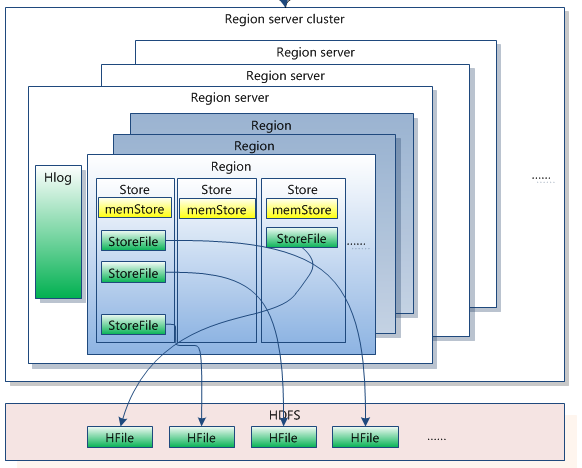
HDFS 是分布式文件系統,適合保存大文件。官方宣稱它并非普通用途文件系統,不提供文件的個別記錄的快速查詢。 另一方面,HBase基于HDFS且提供大表的記錄快速查找(和更新)。這有時可能引起概念混亂。 HBase 內部將數據放到索引好的 "存儲文件(StoreFiles)" ,以便高速查詢。存儲文件位于 HDFS中。 PS:說白了,HBASE就是一個索引集合.
HBase與關系數據庫的存儲結構對比(HBase是NOSQL--not only sql的一種):在HBase中定位到value值,需要幾個坐標:rowkey,列族,列,版本號。。在這里我對比的例子不太恰當。。Hbase還是存儲一些半結構化的數據要好一點。
| id | name | password | type |
| 1 | zhangsan | xxxxx | sb |
| 2 | lisi | 324324 | sb2 |
| 3 | zhaowu | 423423 | db |
hbase:
| rowkey(主鍵) | info(列族) | others(列族) |
| name | password | type | age | |
| rk0000999 | zhangsan,version1 zhangsan3,version2 | xxxxxxxx | sb | 10 |

前提: 已經部署分布式文件系統,例如HDFS.
3.1 機器準備,以及節點的分配
在這里有三臺機器,其中一臺為HMaster,同時的有三個HRegionServer.所以有一臺機器時兩種角色.還需要部署HDFS和Zookeeper.我的HDFS也是三個節點,也是有一臺機器同時有NameNode和DataNode,SecondaryNameNode,其他兩臺機器只有datanode.
| IP | Hostname | JVM Pro?cess |
| 192.168.237.201 | Spark-0x64-001 | HMaster,HRegionServer,QuorumPeerMain,DataNode NameNode,SecondaryNameNode |
| 192.168.237.202 | Spark-0x64-002 | HRegionServer,QurumPeerMain,DataNode |
| 192.168.237.203 | Spark-0x64-003 | HRegionServer,QurumPeerMain,DataNode |
3.2 安裝非HA模式的HDFS
由于之前之前已經安裝過HDFS的分布式集群,但是是非HA機制. 這里就不重復啦.
3.3 安裝集群的Zookeeper
不重復啦。之前的博客已經寫啦.http://my.oschina.net/codeWatching/blog/367309
3.4 配置HBase的文件
a. 修改文件hbase-evn.sh.添加兩個地方.
export JAVA_HOME=/spark/app/jdk1.7.0_21/
export HBASE_MANAGES_ZK=false
b. 修改文件hbase-site.xml
<configuration> <property> <name>hbase.rootdir</name> <value>hdfs://Spark-0x64-001:9000/hbase</value> </property> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <property> <name>hbase.master</name> <value>Spark-0x64-001:6000</value> </property> <property> <name>hbase.zookeeper.quorum</name> <value>Spark-0x64-001,Spark-0x64-002,Spark-0x64-003</value> </property> </configuration>
c.將hadoop中的core-site.xml和hdfs-site.xml拷貝到hbase的conf目錄下
d.編輯regionservers文件
Spark-0x64-001 Spark-0x64-002 Spark-0x64-003
3.5 將配置好的Hbase拷貝到其他機器上。Scp -r 命令.
3.6 配置時間時間服務器。見鏈接:........
3.7 啟動HBase
a.在三臺機器上啟動zookeeper b.啟動HDFS.已啟動 c.啟動Hbase(主節點Master)--->sh bin/start-hbase.sh. d.可選,啟動多個HMaster---->hbase-daemon.sh start master
3.8 驗證Web頁面
http://192.168.237.201:60010
HBase的技術架構圖:一覽無余
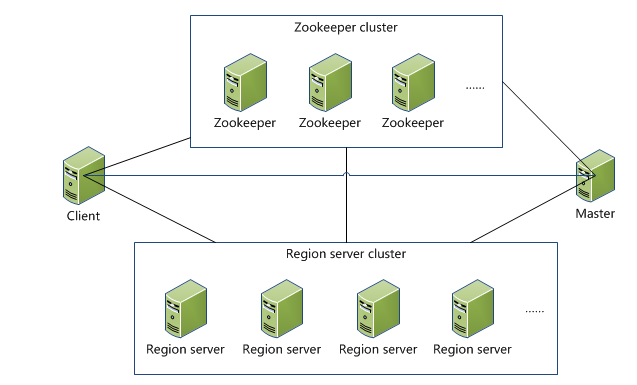
Client 1 包含訪問hbase的接口,client維護著一些cache來加快對hbase的訪問,比如regione的位置信息。 Zookeeper 1 保證任何時候,集群中只有一個master 2 存貯所有Region的尋址入口。 3 實時監控Region Server的狀態,將Region server的上線和下線信息實時通知給Master 4 存儲Hbase的schema,包括有哪些table,每個table有哪些column family Master 1 為Region server分配region 2 負責region server的負載均衡 3 發現失效的region server并重新分配其上的region 4 GFS上的垃圾文件回收 5 處理schema更新請求 Region Server 1 Region server維護Master分配給它的region,處理對這些region的IO請求 2 Region server負責切分在運行過程中變得過大的region 可以看到,client訪問hbase上數據的過程并不需要master參與(尋址訪問zookeeper和region server,數據讀寫訪問regione server),master僅僅維護者table和region的元數據信息,負載很低。
HBase的尋找數據的流程

系統如何找到某個row key (或者某個 row key range)所在的region hbase使用三層類似B+樹的結構來保存region位置。 第一層是保存zookeeper(谷歌chubby)里面的文件,它持有root region的位置。 第二層root region是.META.表的第一個region其中保存了.META.z表其它region的位置。通過root region,我們就可以訪問.META.表的數據。 .META.是第三層,它是一個特殊的表,保存了hbase中所有數據表的region 位置信息。 PS:root region永遠不會被split,保證了最需要三次跳轉,就能定位到任意region 。 2.META.表每行保存一個region的位置信息,row key 采用表名+表的最后一樣編碼而成。 3 為了加快訪問,.META.表的全部region都保存在內存中。 假設,.META.表的一行在內存中大約占用1KB。并且每個region限制為128MB。 那么上面的三層結構可以保存的region數目為: (128MB/1KB) * (128MB/1KB) = = 2(34)個region 4 client會將查詢過的位置信息保存緩存起來,緩存不會主動失效,因此如果client上的緩存全部失效,則需要進行6次網絡來回,才能定位到正確的region(其中三次用來發現緩存失效,另外三次用來獲取位置信息)。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





