溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“怎么編寫不同MapReudce程序”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“怎么編寫不同MapReudce程序”吧!
序列化就是把 內存中的對象的狀態信息,轉換成 字節序列以便于存儲(持久化)和網絡傳輸。而反序列化就是將收到 字節序列或者是硬盤的持久化數據,轉換成內存中的對象。
其實在Java規范中,已經有了一套序列化的機制,某個面向對象的類實現Serializable接口就能實現序列化與反序列化,但是記得一定要加上序列化版本ID serialVersionUID .可是為什么Hadoop要自主研發序列化機制呢?它對比原生態的有什么特點和區別呢?
JDK在序列化的時候,算法會考慮這些事情:
所以我們只要implements Serializable接口,JDK會自動處理一切,Java的序列化機制相當復雜,能處理各種對象關系。 缺點:Java的序列化機制計算量開銷大,且序列化的結果體積太大,有時能達到對象大小的數倍.引用機制也會導致大文件不能分割. 這些缺點對于Hadoop是非常致命的,因為在Hadoop集群之間需要通訊或者是RPC調用的話,需要序列化,而且要求序列化要快,且體積要小,占用帶寬要小。所以Hadoop就自個玩了一套. |
Hadoop的序列化的特點是: 1 . 緊湊:由于帶寬是集群中信息傳遞的最寶貴的資源所以我們必須想法設法縮小傳遞信息的大小,hadoop的序列化就 為了更好地坐到這一點而設計的。 2 . 對象可重用:JDK的反序列化會不斷地創建對象,這肯定會造成一定的系統開銷,但是在hadoop的反序列化中,能重復的利用一個對象的readField方法來重新產生不同的對象。 3 . 可擴展性:Hadoop的序列化有多中選擇 a.可以利用實現hadoop框架中的Writable接口。(原生的) b.使用開源的序列化框架protocol Buffers,Avro等框架。 PS(網絡來源):hadoop2.X之后是實現一個叫YARN,所有應用(如mapreduce,或者其他spark實時或者離線的計算框架都可以運行在YARN上),YARN還負責對資源的調度等等。YARN的序列化就是用Google開發的序列化框架protocol Buffers,目前支持支持三種語言C++,java,Python.所以RPC這一層我們就可以利用其他語言來做文章,滿足其他語言開發者的需求。 接下來的話就是如何使用序列化機制,Writable介紹如下. |
Hadoop原生的序列化,hadoop原生的序列化類需要實現一個叫Writeable的接口,類似于Serializable接口。
還有hadoop也為我們提供了幾個序列化類,他們都直接或者間接地實現了Writable接口。如:IntWritable,LongWritable,Text,org.apache.hadoop.io.WritableComparable<T>等等。
實現Writable接口必須實現兩個方法:
public void write(DataOutput out) throws IOException ; public void readFields(DataInput in) throws IOException ;
實現WritableComparable接口必須實現三個方法,翻閱該接口的的源碼,都已經給出demo了.篇幅原因,自己去看吧
案例1:數據如下圖,統計電話號碼相同的的上傳下載流量和總流量.電話號碼,上傳流量,下載流量,總流量.(1,lastest-2,lastest-3)
1363157985066 13726230503 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200 1363157995052 13826544101 5C-0E-8B-C7-F1-E0:CMCC 120.197.40.4 4 0 264 0 200 1363157991076 13926435656 20-10-7A-28-CC-0A:CMCC 120.196.100.99 2 4 132 1512 200 1363154400022 13926251106 5C-0E-8B-8B-B1-50:CMCC 120.197.40.4 4 0 240 0 200 1363157993044 18211575961 94-71-AC-CD-E6-18:CMCC-EASY 120.196.100.99 iface.qiyi.com 視頻網站 15 12 1527 2106 200 1363157995074 84138413 5C-0E-8B-8C-E8-20:7DaysInn 120.197.40.4 122.72.52.12 20 16 4116 1432 200 1363157993055 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200 1363157995033 15920133257 5C-0E-8B-C7-BA-20:CMCC 120.197.40.4 sug.so.# 信息安全 20 20 3156 2936 200 1363157983019 13719199419 68-A1-B7-03-07-B1:CMCC-EASY 120.196.100.82 4 0 240 0 200 1363157984041 13660577991 5C-0E-8B-92-5C-20:CMCC-EASY 120.197.40.4 s19.# 站點統計 24 9 6960 690 200 1363157973098 15013685858 5C-0E-8B-C7-F7-90:CMCC 120.197.40.4 rank.ie.sogou.com 搜索引擎 28 27 3659 3538 200 1363157986029 15989002119 E8-99-C4-4E-93-E0:CMCC-EASY 120.196.100.99 www.umeng.com 站點統計 3 3 1938 180 200 1363157992093 13560439658 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 15 9 918 4938 200 1363157986041 13480253104 5C-0E-8B-C7-FC-80:CMCC-EASY 120.197.40.4 3 3 180 180 200 1363157984040 13602846565 5C-0E-8B-8B-B6-00:CMCC 120.197.40.4 2052.flash3-http.qq.com 綜合門戶 15 12 1938 2910 200 1363157995093 13922314466 00-FD-07-A2-EC-BA:CMCC 120.196.100.82 img.qfc.cn 12 12 3008 3720 200 1363157982040 13502468823 5C-0A-5B-6A-0B-D4:CMCC-EASY 120.196.100.99 y0.ifengimg.com 綜合門戶 57 102 7335 110349 200 1363157986072 18320173382 84-25-DB-4F-10-1A:CMCC-EASY 120.196.100.99 input.shouji.sogou.com 搜索引擎 21 18 9531 2412 200 1363157990043 13925057413 00-1F-64-E1-E6-9A:CMCC 120.196.100.55 t3.baidu.com 搜索引擎 69 63 11058 48243 200 1363157988072 13760778710 00-FD-07-A4-7B-08:CMCC 120.196.100.82 2 2 120 120 200 1363157985066 13726238888 00-FD-07-A4-72-B8:CMCC 120.196.100.82 i02.c.aliimg.com 24 27 2481 24681 200 1363157993055 13560436666 C4-17-FE-BA-DE-D9:CMCC 120.196.100.99 18 15 1116 954 200
package com.codewatching.fluxcount.bean;
import java.io.DataInput;
import java.io.DataOutput;
import java.io.IOException;
import org.apache.hadoop.io.Writable;
public class FlowBean implements Writable {
private String phoneNum;
private long upFlow;
private long downFlow;
private long sumFlow;
public FlowBean(){}
public FlowBean(String phoneNum, long upFlow, long downFlow) {
super();
this.phoneNum = phoneNum;
this.upFlow = upFlow;
this.downFlow = downFlow;
this.sumFlow = upFlow+downFlow;
}
public String getPhoneNum() {
return phoneNum;
}
public void setPhoneNum(String phoneNum) {
this.phoneNum = phoneNum;
}
public long getUpFlow() {
return upFlow;
}
public void setUpFlow(long upFlow) {
this.upFlow = upFlow;
}
public long getDownFlow() {
return downFlow;
}
public void setDownFlow(long downFlow) {
this.downFlow = downFlow;
}
public long getSumFlow() {
return sumFlow;
}
public void setSumFlow(long sumFlow) {
this.sumFlow = sumFlow;
}
@Override
public void write(DataOutput out) throws IOException {
out.writeUTF(phoneNum);
out.writeLong(downFlow);
out.writeLong(upFlow);
out.writeLong(sumFlow);
}
@Override
public void readFields(DataInput in) throws IOException {
phoneNum = in.readUTF();
downFlow = in.readLong();
upFlow = in.readLong();
sumFlow = in.readLong();
}
@Override
public String toString() {
return upFlow+"\t"+downFlow+"\t"+sumFlow;
}
}2. 編寫Mapper,Reducer,Runner. package com.codewatching.fluxcount.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import com.codewatching.fluxcount.bean.FlowBean;
public class FlowSumMapper extends Mapper<LongWritable, Text, Text, FlowBean>{
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
String line = value.toString();
String[] fileds = line.split("\t");
int length = fileds.length;
String phoneNum = fileds[1];
long upFlow = Long.parseLong(fileds[length-3]);
long downFlow = Long.parseLong(fileds[length-2]);
FlowBean flowBean = new FlowBean(phoneNum, upFlow, downFlow);
//以flowBean為value供reducer處理
context.write(new Text(phoneNum), flowBean);
}
}package com.codewatching.fluxcount.hadoop;
import java.io.IOException;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import com.codewatching.fluxcount.bean.FlowBean;
public class FlowSumReducer extends Reducer<Text, FlowBean, Text, FlowBean>{
@Override
protected void reduce(Text key, Iterable<FlowBean> values,Context context)
throws IOException, InterruptedException {
long _downFlow = 0;
long _upFlow = 0;
for (FlowBean flowBean : values) {
_downFlow += flowBean.getDownFlow();
_upFlow += flowBean.getUpFlow();
}
FlowBean bean = new FlowBean(key.toString(), _upFlow, _downFlow);
context.write(key, bean);
}
}package com.codewatching.fluxcount.hadoop;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
import com.codewatching.fluxcount.bean.FlowBean;
public class FlowSumRunner extends Configured implements Tool{
@Override
public int run(String[] args) throws Exception {
Configuration configuration = new Configuration();
Job job = Job.getInstance(configuration);
configuration.set("mapreduce.job.jar", "fluxcount.jar");
job.setJarByClass(FlowSumRunner.class);
job.setMapperClass(FlowSumMapper.class);
job.setReducerClass(FlowSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(FlowBean.class);
FileInputFormat.setInputPaths(job, new Path(args[0]));
FileSystem fileSystem = FileSystem.get(configuration);
Path path = new Path(args[1]);
if(fileSystem.exists(path)){
fileSystem.delete(path, true);
}
FileOutputFormat.setOutputPath(job, path);
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args) throws Exception {
ToolRunner.run(new Configuration(), new FlowSumRunner(), args);
}
} |
hadoop的map/reduce中支持對key進行分區,從而讓map出來的數據均勻分布在reduce上.Map的結果,會通過partition分發到Reducer上,Reducer做完Reduce操作后,通過OutputFormat,進行輸出結果.Mapper的結果,可能送到Combiner(下面回講到)做合并, Mapper最終處理的鍵值對<key, value>,是需要送到Reducer去合并的,合并的時候,有相同key的鍵/值對會送到同一個Reducer。哪個key到哪個Reducer的分配過程,是由Partitioner規定的.說的真麻煩。如果我們去查閱Partitioner類的源碼,就知道它是個抽象類,里面有個抽象方法:
/** * Get the partition number for a given key (hence record) given the total * number of partitions i.e. number of reduce-tasks for the job. * * <p>Typically a hash function on a all or a subset of the key.</p> * * @param key the key to be partioned. * @param value the entry value. * @param numPartitions the total number of partitions. * @return the partition number for the <code>key</code>. */ public abstract int getPartition(KEY key, VALUE value, int numPartitions);
而在類的注釋也是非常的全面,不得抱怨一句。洋文如果好一點的話,學起來會輕松多了.唉,老大難.
Partitioner controls the partitioning of the keys of the intermediate map-outputs.....省略..
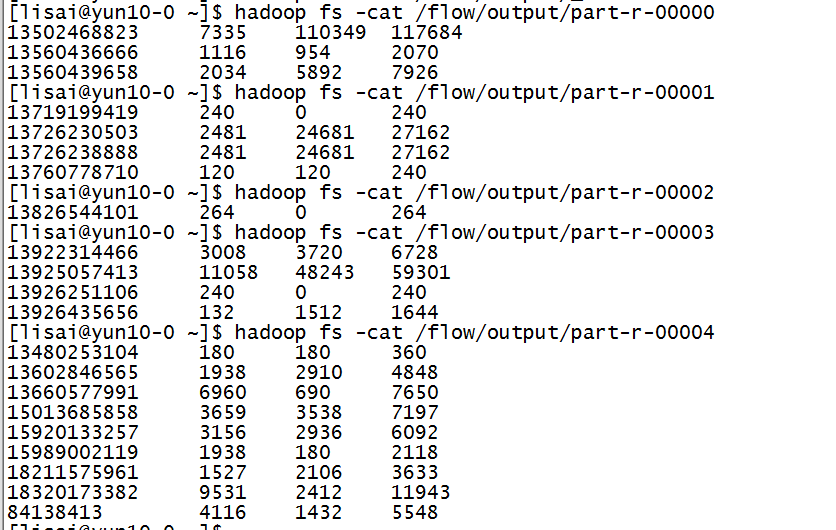
案例2:在案例1的基礎上,然后將號碼進行分區,假設135是北京,139是江西...將各地區的統計出來,并且各地區單獨存放文件.效果圖如下:

package com.codewatching.fluxcount.hadoop;
import java.util.HashMap;
import java.util.Map;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Partitioner;
import com.codewatching.fluxcount.bean.FlowBean;
public class AreaPartitioner extends Partitioner<Text, FlowBean>{
private static Map<String,Integer> areaMap;
static{
areaMap = new HashMap<String, Integer>();
areaMap.put("135", 0); //模擬分區,存在內存中。
areaMap.put("137", 1);
areaMap.put("138", 2);
areaMap.put("139", 3);
}
@Override
public int getPartition(Text key, FlowBean value, int numPartitions) {
int area = 4; //默認都是為4
String prefix = key.toString().substring(0,3);
//判斷是否在某個分區中
Integer index = areaMap.get(prefix);
if(index!=null){
area = index; //如果存在,取相應的數字0,1,2,3
}
return area;
}
}2.在Runner中添加兩行代碼.
3.在Hadoop中的運行結果.
|
其實上Hadoop已經提供了一個默認的實現類叫著HashPartitioner.看看它如何key分區的.
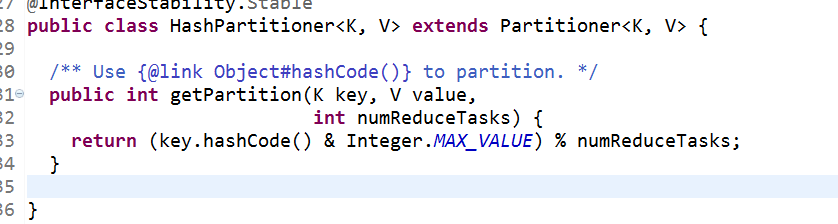
將key均勻分布在ReduceTasks上,舉例如果Key為Text的話,Text的hashcode方法跟String的基本一致,都是采用的Horner公式計算,得到一個int,string太大的話這個int值可能會溢出變成負數,所以與上Integer.MAX_VALUE(即0111111111111111),然后再對reduce個數取余,這樣就可以讓key均勻分布在reduce上。
PS:這個簡單算法得到的結果可能不均勻,因為key畢竟不會那么線性連續.
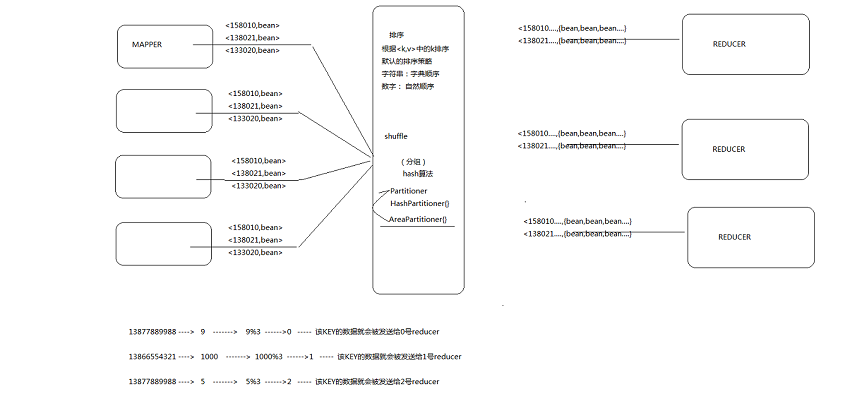
輸入處理類:InputFormat的作用負責MR的輸入部分
1、驗證作業的輸入是否規范。
2、把輸入文件切分成InputSplit。
3、提供RecordReader的實現類,把InputSplit讀到Mapper中進行處理.

最佳分片的大小應該與塊大小相同:因為它是確保可以存儲在單個節點上的最大輸入塊的大小。如果分片跨越2個數據塊,那么對于任何一個HDFS節點,基本上都不可能同時存儲著2個數據塊,因此分片中的部分數據需要通過網絡傳輸到Map任務節點,與使用本地數據運行整個Map任務相比,這種方法顯然效率更低。
PS:還可以編寫自定義的輸入處理類,繼承InputFormat,重寫相應的方法,當然,首先要知道方法的作用.--建議讀源代碼.
輸出處理類:OutputFormat,在Ruduce處理之后.

編程時,輸出輸入處理類在哪使用指定:

感謝各位的閱讀,以上就是“怎么編寫不同MapReudce程序”的內容了,經過本文的學習后,相信大家對怎么編寫不同MapReudce程序這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。