溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
由于最近在項目中需要用到Spark的累加器,同時需要自己去自定義實現Spark的累加器,從而滿足生產上的需求。對此,對Spark的累加器實現機制進行了追蹤學習。
本系列文章,將從以下幾個方面入手,對Spark累加器進行剖析:
Spark累加器的基本概念
累加器的重點類構成
累加器的源碼解析
累加器的執行過程
累加器使用中的坑
自定義累加器的實現
Spark提供的Accumulator,主要用于多個節點對一個變量進行共享性的操作。Accumulator只提供了累加的功能,只能累加,不能減少累加器只能在Driver端構建,并只能從Driver端讀取結果,在Task端只能進行累加。
至于這里為什么只能在Task累加呢?下面的內容將會進行詳細的介紹,先簡單介紹下:
在Task節點,準確的就是說在executor上;
每個Task都會有一個累加器的變量,被序列化傳輸到executor端運行之后再返回過來都是獨立運行的;
如果在Task端去獲取值的話,只能獲取到當前Task的,Task與Task之間不會有影響累加器不會改變Spark lazy計算的特點,只會在Job觸發的時候進行相關的累加操作
現有累加器類型: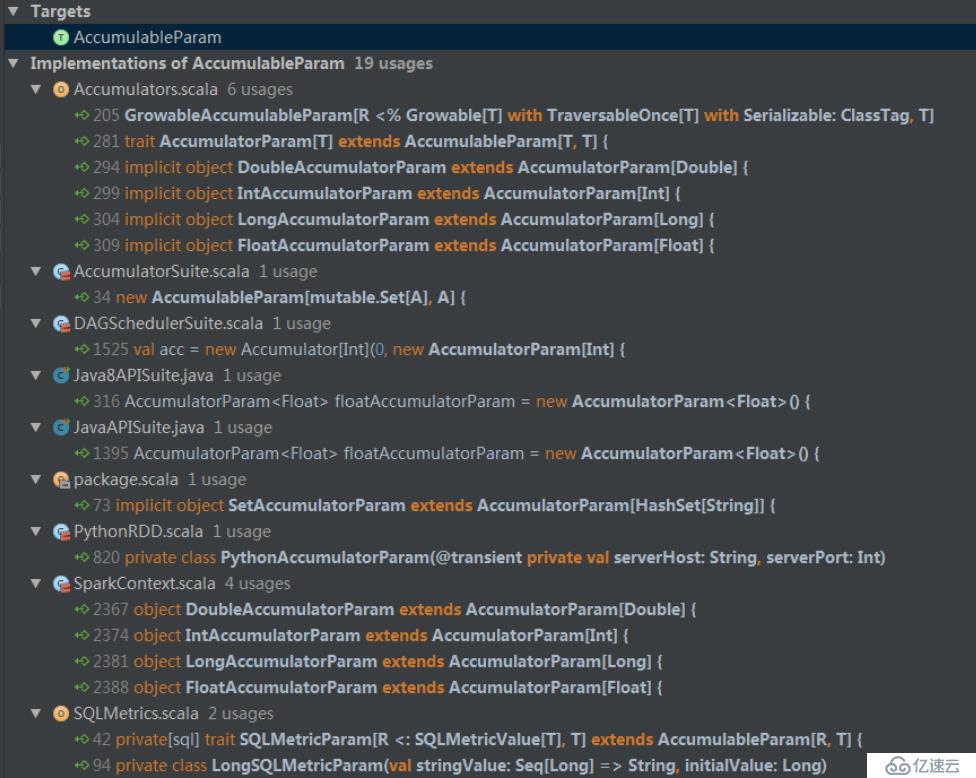
class Accumulator extends Accumulable
源碼(源碼中已經對這個類的作用做了十分詳細的解釋):
/**
* A simpler value of [[Accumulable]] where the result type being accumulated is the same
* as the types of elements being merged, i.e. variables that are only "added" to through an
* associative operation and can therefore be efficiently supported in parallel. They can be used
* to implement counters (as in MapReduce) or sums. Spark natively supports accumulators of numeric
* value types, and programmers can add support for new types.
*
* An accumulator is created from an initial value `v` by calling [[SparkContext#accumulator]].
* Tasks running on the cluster can then add to it using the [[Accumulable#+=]] operator.
* However, they cannot read its value. Only the driver program can read the accumulator's value,
* using its value method.
*
* @param initialValue initial value of accumulator
* @param param helper object defining how to add elements of type `T`
* @tparam T result type
*/
class Accumulator[T] private[spark] (
@transient private[spark] val initialValue: T,
param: AccumulatorParam[T],
name: Option[String],
internal: Boolean)
extends Accumulable[T, T](initialValue, param, name, internal) {
def this(initialValue: T, param: AccumulatorParam[T], name: Option[String]) = {
this(initialValue, param, name, false)
}
def this(initialValue: T, param: AccumulatorParam[T]) = {
this(initialValue, param, None, false)
}
}
主要實現了累加器的初始化及封裝了相關的累加器操作方法
同時在類對象構建的時候向Accumulators注冊累加器
累加器的add操作的返回值類型和傳入進去的值類型可以不一樣
所以一定要定義好兩步操作(即add方法):累加操作/合并操作object Accumulators
該方法在Driver端管理著累加器,也包含了累加器的聚合操作trait AccumulatorParam[T] extends AccumulableParam[T, T]
源碼:
/**
* A simpler version of [[org.apache.spark.AccumulableParam]] where the only data type you can add
* in is the same type as the accumulated value. An implicit AccumulatorParam object needs to be
* available when you create Accumulators of a specific type.
*
* @tparam T type of value to accumulate
*/
trait AccumulatorParam[T] extends AccumulableParam[T, T] {
def addAccumulator(t1: T, t2: T): T = {
addInPlace(t1, t2)
}
}
AccumulatorParam的addAccumulator操作的泛型封裝
具體的實現還是需要在具體實現類里面實現addInPlace方法
自定義實現累加器的關鍵object AccumulatorParam
源碼:
object AccumulatorParam {
// The following implicit objects were in SparkContext before 1.2 and users had to
// `import SparkContext._` to enable them. Now we move them here to make the compiler find
// them automatically. However, as there are duplicate codes in SparkContext for backward
// compatibility, please update them accordingly if you modify the following implicit objects.
implicit object DoubleAccumulatorParam extends AccumulatorParam[Double] {
def addInPlace(t1: Double, t2: Double): Double = t1 + t2
def zero(initialValue: Double): Double = 0.0
}
implicit object IntAccumulatorParam extends AccumulatorParam[Int] {
def addInPlace(t1: Int, t2: Int): Int = t1 + t2
def zero(initialValue: Int): Int = 0
}
implicit object LongAccumulatorParam extends AccumulatorParam[Long] {
def addInPlace(t1: Long, t2: Long): Long = t1 + t2
def zero(initialValue: Long): Long = 0L
}
implicit object FloatAccumulatorParam extends AccumulatorParam[Float] {
def addInPlace(t1: Float, t2: Float): Float = t1 + t2
def zero(initialValue: Float): Float = 0f
}
// TODO: Add AccumulatorParams for other types, e.g. lists and strings
}
從源碼中大量的implicit關鍵詞,可以發現該類主要進行隱式類型轉換的操作TaskContextImpl
在Executor端管理著我們的累加器,累加器是通過該類進行返回的Driver端
??accumulator方法
以下列這段代碼中的accumulator方法為入口點,進入到相應的源碼中去
val acc = new Accumulator(initialValue, param, Some(name))源碼:
class Accumulator[T] private[spark] (
@transient private[spark] val initialValue: T,
param: AccumulatorParam[T],
name: Option[String],
internal: Boolean)
extends Accumulable[T, T](initialValue, param, name, internal) {
def this(initialValue: T, param: AccumulatorParam[T], name: Option[String]) = {
this(initialValue, param, name, false)
}
def this(initialValue: T, param: AccumulatorParam[T]) = {
this(initialValue, param, None, false)
}
}??繼承的Accumulable[T, T]
源碼:
class Accumulable[R, T] private[spark] (
initialValue: R,
param: AccumulableParam[R, T],
val name: Option[String],
internal: Boolean)
extends Serializable {
…
// 這里的_value并不支持序列化
// 注:有@transient的都不會被序列化
@volatile @transient private var value_ : R = initialValue // Current value on master
…
// 注冊了當前的累加器
Accumulators.register(this)
…,
}??Accumulators.register()
源碼:
// 傳入參數,注冊累加器
def register(a: Accumulable[_, _]): Unit = synchronized {
// 構造成WeakReference
originals(a.id) = new WeakReference[Accumulable[_, _]](a)
}至此,Driver端的初始化已經完成
Executor端
Executor端的反序列化是一個得到我們的對象的過程
初始化是在反序列化的時候就完成的,同時反序列化的時候還完成了Accumulator向TaskContextImpl的注冊??TaskRunner中的run方法
// 在計算的過程中,會將RDD和function經過序列化之后傳給Executor端
private[spark] class Executor(
executorId: String,
executorHostname: String,
env: SparkEnv,
userClassPath: Seq[URL] = Nil,
isLocal: Boolean = false)
extends Logging {
...
class TaskRunner(
execBackend: ExecutorBackend,
val taskId: Long,
val attemptNumber: Int,
taskName: String,
serializedTask: ByteBuffer)
extends Runnable {
…
override def run(): Unit = {
…
val (value, accumUpdates) = try {
// 調用TaskRunner中的task.run方法,觸發task的運行
val res = task.run(
taskAttemptId = taskId,
attemptNumber = attemptNumber,
metricsSystem = env.metricsSystem)
threwException = false
res
} finally {
…
}
…
}??Task中的collectAccumulators()方法
private[spark] abstract class Task[T](
final def run(
taskAttemptId: Long,
attemptNumber: Int,
metricsSystem: MetricsSystem)
: (T, AccumulatorUpdates) = {
…
try {
// 返回累加器,并運行task
// 調用TaskContextImpl的collectAccumulators,返回值的類型為一個Map
(runTask(context), context.collectAccumulators())
} finally {
…
}
…
}
)??ResultTask中的runTask方法
override def runTask(context: TaskContext): U = {
// Deserialize the RDD and the func using the broadcast variables.
val deserializeStartTime = System.currentTimeMillis()
val ser = SparkEnv.get.closureSerializer.newInstance()
// 反序列化是在調用ResultTask的runTask方法的時候做的
// 會反序列化出來RDD和自己定義的function
val (rdd, func) = ser.deserialize[(RDD[T], (TaskContext, Iterator[T]) => U)](
ByteBuffer.wrap(taskBinary.value), Thread.currentThread.getContextClassLoader)
_executorDeserializeTime = System.currentTimeMillis() - deserializeStartTime
metrics = Some(context.taskMetrics)
func(context, rdd.iterator(partition, context))
}??Accumulable中的readObject方法
// 在反序列化的過程中會調用Accumulable.readObject方法
// Called by Java when deserializing an object
private def readObject(in: ObjectInputStream): Unit = Utils.tryOrIOException {
in.defaultReadObject()
// value的初始值為zero;該值是會被序列化的
value_ = zero
deserialized = true
// Automatically register the accumulator when it is deserialized with the task closure.
//
// Note internal accumulators sent with task are deserialized before the TaskContext is created
// and are registered in the TaskContext constructor. Other internal accumulators, such SQL
// metrics, still need to register here.
val taskContext = TaskContext.get()
if (taskContext != null) {
// 當前反序列化所得到的對象會被注冊到TaskContext中
// 這樣TaskContext就可以獲取到累加器
// 任務運行結束之后,就可以通過context.collectAccumulators()返回給executor
taskContext.registerAccumulator(this)
}
}??Executor.scala
// 在executor端拿到accumuUpdates值之后,會去構造一個DirectTaskResult
val directResult = new DirectTaskResult(valueBytes, accumUpdates, task.metrics.orNull)
val serializedDirectResult = ser.serialize(directResult)
val resultSize = serializedDirectResult.limit
…
// 最終由ExecutorBackend的statusUpdate方法發送至Driver端
// ExecutorBackend為一個Trait,有多種實現
execBackend.statusUpdate(taskId, TaskState.FINISHED, serializedResult)??CoarseGrainedExecutorBackend中的statusUpdate方法
// 通過ExecutorBackend的一個實現類:CoarseGrainedExecutorBackend 中的statusUpdate方法
// 將數據發送至Driver端
override def statusUpdate(taskId: Long, state: TaskState, data: ByteBuffer) {
val msg = StatusUpdate(executorId, taskId, state, data)
driver match {
case Some(driverRef) => driverRef.send(msg)
case None => logWarning(s"Drop $msg because has not yet connected to driver")
}
}??CoarseGrainedSchedulerBackend中的receive方法
// Driver端在接收到消息之后,會調用CoarseGrainedSchedulerBackend中的receive方法
override def receive: PartialFunction[Any, Unit] = {
case StatusUpdate(executorId, taskId, state, data) =>
// 會在DAGScheduler的handleTaskCompletion方法中將結果返回
scheduler.statusUpdate(taskId, state, data.value)
…
}??TaskSchedulerImpl的statusUpdate方法
def statusUpdate(tid: Long, state: TaskState, serializedData: ByteBuffer) {
…
if (state == TaskState.FINISHED) {
taskSet.removeRunningTask(tid)
// 將成功的Task入隊
taskResultGetter.enqueueSuccessfulTask(taskSet, tid, serializedData)
} else if (Set(TaskState.FAILED, TaskState.KILLED, TaskState.LOST).contains(state)) {
taskSet.removeRunningTask(tid)
taskResultGetter.enqueueFailedTask(taskSet, tid, state, serializedData)
}
…
}??TaskResultGetter的enqueueSuccessfulTask方法
def enqueueSuccessfulTask(taskSetManager: TaskSetManager, tid: Long, serializedData: ByteBuffer) {
…
result.metrics.setResultSize(size)
scheduler.handleSuccessfulTask(taskSetManager, tid, result)
…??TaskSchedulerImpl的handleSuccessfulTask方法
def handleSuccessfulTask(
taskSetManager: TaskSetManager,
tid: Long,
taskResult: DirectTaskResult[_]): Unit = synchronized {
taskSetManager.handleSuccessfulTask(tid, taskResult)
}??DAGScheduler的taskEnded方法
def taskEnded(
task: Task[_],
reason: TaskEndReason,
result: Any,
accumUpdates: Map[Long, Any],
taskInfo: TaskInfo,
taskMetrics: TaskMetrics): Unit = {
eventProcessLoop.post(
// 給自身的消息循環體發了個CompletionEvent
// 這個CompletionEvent會被handleTaskCompletion方法所接收到
CompletionEvent(task, reason, result, accumUpdates, taskInfo, taskMetrics))
}??DAGScheduler的handleTaskCompletion方法
// 與上述CoarseGrainedSchedulerBackend中的receive方法章節對應
// 在handleTaskCompletion方法中,接收CompletionEvent
// 不論是ResultTask還是ShuffleMapTask都會去調用updateAccumulators方法,更新累加器的值
private[scheduler] def handleTaskCompletion(event: CompletionEvent) {
…
event.reason match {
case Success =>
listenerBus.post(SparkListenerTaskEnd(stageId, stage.latestInfo.attemptId, taskType,
event.reason, event.taskInfo, event.taskMetrics))
stage.pendingPartitions -= task.partitionId
task match {
case rt: ResultTask[_, _] =>
// Cast to ResultStage here because it's part of the ResultTask
// TODO Refactor this out to a function that accepts a ResultStage
val resultStage = stage.asInstanceOf[ResultStage]
resultStage.activeJob match {
case Some(job) =>
if (!job.finished(rt.outputId)) {
updateAccumulators(event)
case smt: ShuffleMapTask =>
val shuffleStage = stage.asInstanceOf[ShuffleMapStage]
updateAccumulators(event)
}
…
}??DAGScheduler的updateAccumulators方法
private def updateAccumulators(event: CompletionEvent): Unit = {
val task = event.task
val stage = stageIdToStage(task.stageId)
if (event.accumUpdates != null) {
try {
// 調用了累加器的add方法
Accumulators.add(event.accumUpdates)??Accumulators的add方法
def add(values: Map[Long, Any]): Unit = synchronized {
// 遍歷傳進來的值
for ((id, value) <- values) {
if (originals.contains(id)) {
// Since we are now storing weak references, we must check whether the underlying data
// is valid.
// 根據id從注冊的Map中取出對應的累加器
originals(id).get match {
// 將值給累加起來,最終將結果加到value里面
// ++=是被重載了
case Some(accum) => accum.asInstanceOf[Accumulable[Any, Any]] ++= value
case None =>
throw new IllegalAccessError("Attempted to access garbage collected Accumulator.")
}
} else {
logWarning(s"Ignoring accumulator update for unknown accumulator id $id")
}
}
}??Accumulators的++=方法
def ++= (term: R) { value_ = param.addInPlace(value_, term)}??Accumulators的value方法
def value: R = {
if (!deserialized) {
value_
} else {
throw new UnsupportedOperationException("Can't read accumulator value in task")
}
}此時我們的應用程序就可以通過 .value 的方式去獲取計數器的值了
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





