溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇“Splunk是什么”文章的知識點大部分人都不太理解,所以小編給大家總結了以下內容,內容詳細,步驟清晰,具有一定的借鑒價值,希望大家閱讀完這篇文章能有所收獲,下面我們一起來看看這篇“Splunk是什么”文章吧。
Splunk是日志/流式數據領域中做的最好的商業軟件實現,它的核心能力只有一個:
像Google那樣搜索企業內部所有產生的日志
這個的威力非常大,現在的企業不缺數據,缺的是有效挖掘數據的能力。而顯然大部分企業沒有Google的能力去做搜索,于是Splunk提供這樣的能力。與之相競爭的開源實現有Logstash。
Splunk ≈ Logstash Logstash = Redis(傳輸) + ElasticSearch(搜索) + Kibana(展現) ElasticSearch = Lucene + Search
Splunk官網上有,我就不替他們做廣告了,總之,很貴,一萬美元能買1G的流量每天。言歸正傳,我還是分析一下這個玩意兒的一些功能特性吧。
首先,Splunk有一個很炫酷的界面
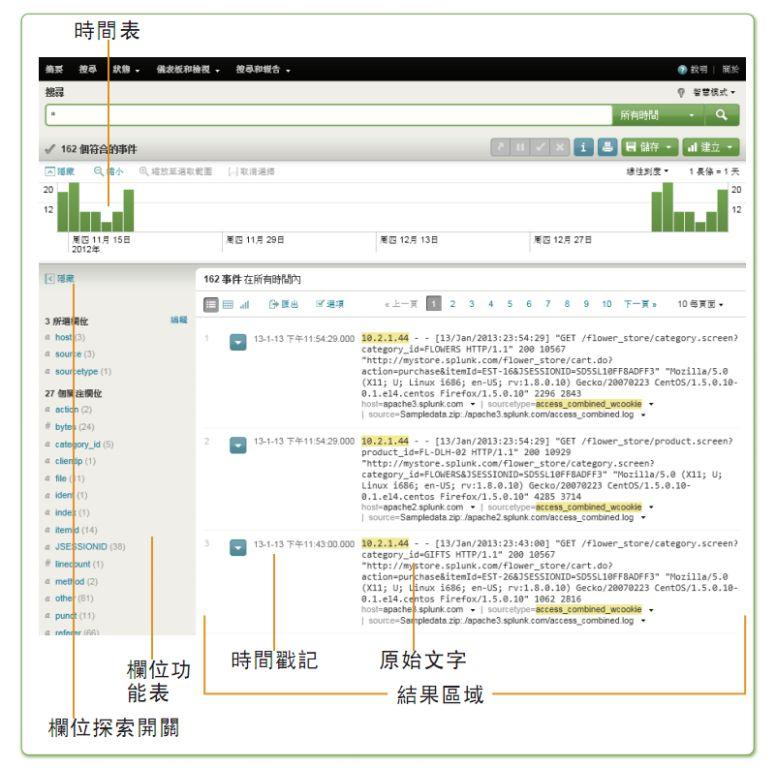
可以看到,Splunk的主要使用方式就是那個搜索框,在里面輸入一種叫做SPL的搜索語言,就能獲取到你想要的各種信息了。Splunk能在后臺對數據進行過濾、聚合、統計,最后得到各種報表、圖像
SPL是一種向SQL致(chao)敬(xi)的語言,語法非常的類似,不同的是,SPL搜索的不是關系數據庫,而是輸入到Splunk系統中所有的日志數據,以下是幾個具體的案例:
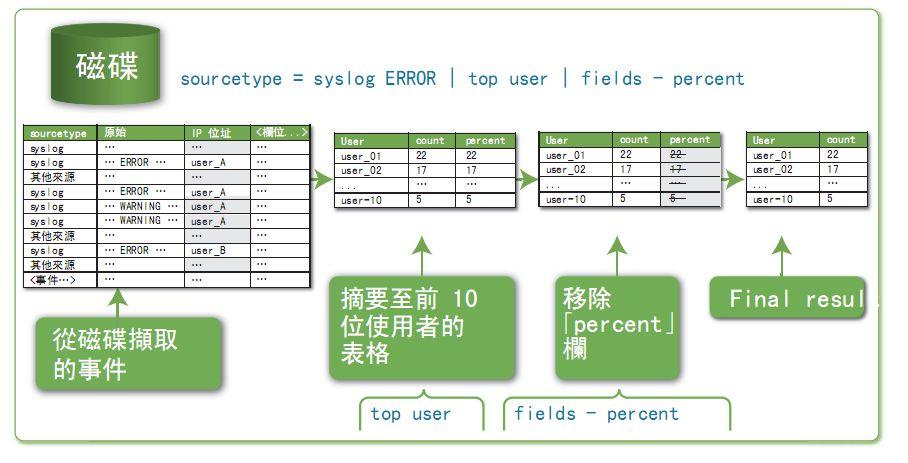
可以看到,對于一行SPL搜索語句
sourcetype = syslog ERROR | top user | fields - precent
Splunk是這么干的,
首先從硬盤上搜索字段sourcetype(來源類型)為syslog的日志,同時,在日志中含有ERROR這個關鍵字的。
通過管道符,把上面的搜索結果根據user字段做聚合,取出其中出現次數最多的前10個
再通過管道符,去掉百分比字段,最后得出結果
最后看到,這個搜索干了什么事情呢?它一下子就把日志中出錯最多的前十個用戶給統計出來了,這樣后續程序員就能跟蹤這些錯誤為什么產生,然后著手去解決。

| where distance/time > 100
使用where,對日志中兩個字段進行相除后比較。

Splunk主要做了3件事
解析原始日志格式,分解成有意義的字段,有的 log 收集方案在第一階段就解析日志只發送關心的字段,以節省帶寬。
根據時間戳,request ID,session ID,user ID 等關聯日志條目,以盡量清晰當時各個子系統的狀態;
根據分析的目的做過濾、聚合、統計等等,最后整一份漂亮的報表出來。
WEB的UI很出色,插件式的,把這個做成了一個平臺,允許很多第三方的公司在上面發布應用。
搜索語法強大,例如查找HTTP 503錯誤近期的出現頻率,例如某一個地區用戶訪問最多的商品列表,例如頁面訪問量排名。基本上,你能想到的可以由SQL完成的搜索,SPL都能夠做出來。
自動猜測一些日志的字段,同時可以在Web上手動調整怎么解析源頭日志。
以上所有操作,都能由掌握SPL語言的非程序員來完成,也就是說Splunk可以由產品經理或者運營團隊來操控。而且還能把數據可視化做出來。
流式搜索,實時過濾日志然后報警,這個對運維團隊很有用。
以上幾點,就決定了Splunk的市場非常的大,這家公司的概念是流式數據領域的數據倉庫,2012在納斯達克上市,不過這兩年被人做空,股票大跌。因為很多云計算廠商都能提供這種服務,例如阿里云1MB/S都是免費的。
###Splunk vs Logstash###
Logstash是個開源的日志搜索工具,也是一體化的開箱即用的產品。基本上,能實現Splunk六成的功力。Web沒有那么強,也沒有SPL這樣簡單的語言,ElasticSearch需要通過Json來查詢,Kibana的搜索語句能力有限。目前可以說Logstash這個項目還在成熟期。需要后續很多的工作才能做好。
###Splunk vs Kafka ###
這么比較其實不是很公平。
Kafka只解決了日志的統一搜集、傳輸、序列化存儲問題。Splunk做的更多些,還做了數據索引的深加工。
同時,Kafka需要在源頭使用schema來定義數據格式,嚴格,有利于后期的消費程序使用。
Splunk卻對源頭數據要求沒有那么高,對現有系統改動小,因為是個企業軟件,需要追求兼容性。
從高可用方面來看,Splunk目前還沒有一天搜集幾個T的數據的案例,Kafka在這方面的能力絕對沒有問題。
Kafka是個比較好的車身框架,但還缺一個強大的發動機和不少內飾;Splunk是一輛功能完善的車子,就是價格很貴,而且沒有在150碼以上開過的案例。
所以,對于Kafka,可能的總體解決方案有:
Kafka + YARN + Hadoop = Samza(Linkin) Kafka + Strom + MySQL Kafka + ElasticSearch + Kibana
以上就是關于“Splunk是什么”這篇文章的內容,相信大家都有了一定的了解,希望小編分享的內容對大家有幫助,若想了解更多相關的知識內容,請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





