溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關Hadoop文件寫入的示例分析,小編覺得挺實用的,因此分享給大家做個參考,希望大家閱讀完這篇文章后可以有所收獲。
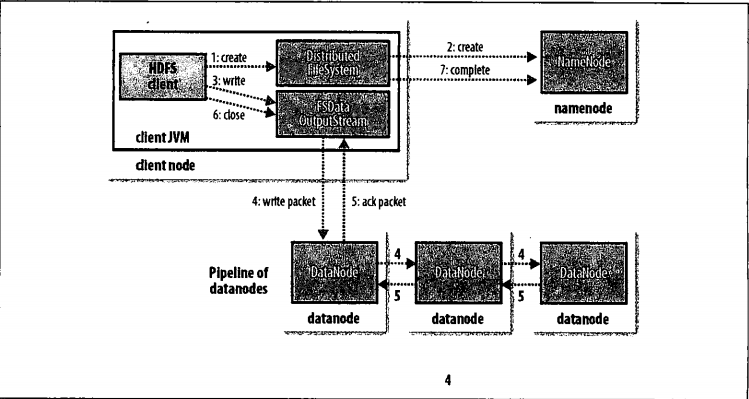
客戶端通過對DistibutedFileSystem對象調用create()函數來創建文件(步驟1).DistributedFileSystem對namenode創建一個RPC調用,在文件系統的命名空間中創建一個新文件,此時該文件中還沒有相應的數據塊(步驟2)。namenode執行各種不同的檢查以確保個文件不存在,并且客戶端有創建該文件的權限。如果這些檢查均通過,namenode就會創建新文件記錄一條記錄;否則,文件創建失敗并向客戶端拋出一個IOException異常。DistributedFileSystem向客戶端返回一個FSDataOutputStream對象,由此客戶端可以開始寫入數據。就像讀取事件一樣,FSDataOutputStream封裝一個DFSOutputStream對象,該對象負責處理datanode和namenode之間的通信。
在客戶端寫入數據時(步驟3),DFSOutputStream將它分成一個個的數據包,并寫入內部隊列,稱為“數據隊列”(data queue).DataStream處理數據列表,它的責任是根據datanode列表來要求namenode分配適合的新塊來存儲數據備份。這一組datanode構成一個管線----我們假設復本數為3,所以管線中有3個節點.DataStreamer將數據包流式傳輸到管線中第一個datanode,該datanode存儲數據包并將它發送到管線中的第2個datanode。同樣地,第2個datanode存儲該數據包并且發送給管線中的第3個(也就是最后一個)datanode(步驟4).DFSOutputStream也維護著一個內部數據包隊列來等待datanode的收到確認回執,稱為”確認隊列“(ack queue).當收到管道中所有datanode確認信息后,該數據包才會從確認隊列刪除(步驟5)。
如果在數據寫入期間,datanode發生故障,則執行以下操作,這對于寫入數據的客戶端是透明的,首先關閉管線,確認把隊列中的任何數據包都添加回數據隊列的最前端,以確認故障節點下游的datanode不會漏掉任何一個數據包。為存儲在另一正常datanode的當前數據塊指定一個新的標識,并將該標識傳送給namenode,以便datanode在恢復后可以刪除存儲的部分數據塊。從管線中刪除故障數據節點并且把余下的數據塊寫入管線中的兩個正常的datanode。namenode注意到塊復本量不足時,會在另一個節點創建一個新的復本。后續的數據塊繼續正常接受處理。
在一個塊被寫入期間可能會有多個datanode同時發生故障,但非常少見,只要寫入了dfs.replication.min的復本數(默認為1),寫操作就會成功,并且這個塊可以在集群中異步復制,直到達到其目標復本數(dfs.replication的默認值為3)。客戶端完成數據的寫入后,會對數據流調用close()方法(步驟6),該操作將剩余的所有數據包寫入datanode管線中,并在聯系namenode且發送文件寫入完成信號之前,等待確認(步驟7),namenode已經知道文件由哪些塊組成(通過DataStreamer詢問數據庫的分配),所以它在返回成功前只需要等待數據塊進行最小量的復制。
關于“Hadoop文件寫入的示例分析”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,使各位可以學到更多知識,如果覺得文章不錯,請把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





