溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“萬級K8s集群穩定性及性能優化的方法是什么”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
在萬級K8s集群規模下的我們如何高效保障etcd集群的穩定性?
etcd集群的穩定性風險又來自哪里?
我們通過基于業務場景、歷史遺留問題、現網運營經驗等進行穩定性風險模型分析,風險主要來自舊TKE etcd架構設計不合理、etcd穩定性、etcd性能部分場景無法滿足業務、測試用例覆蓋不足、變更管理不嚴謹、監控是否全面覆蓋、隱患點是否能自動巡檢發現、極端災難故障數據安全是否能保障。
前面所描述的etcd平臺已經從架構設計上、變更管理上、監控及巡檢、數據遷移、備份幾個方面程度解決了我們管理的各類容器服務的etcd可擴展性、可運維性、可觀測性以及數據安全性,因此本文將重點描述我們在萬級K8s場景下面臨的etcd內核穩定性及性能挑戰,比如:
數據不一致
內存泄露
死鎖
進程Crash
大包請求導致etcd OOM及丟包
較大數據量場景下啟動慢
鑒權及查詢key數量、查詢指定數量記錄接口性能較差
本文將簡易描述我們是如何發現、分析、復現、解決以上問題及挑戰,以及從以上過程中我們獲得了哪些經驗及教訓,并將之應用到我們的各類容器服務存儲穩定性保障中。
同時,我們將解決方案全部貢獻、回饋給etcd開源社區, 截止目前我們貢獻的30+ pr已全部合并到社區。騰訊云TKE etcd團隊是etcd社區2020年上半年最活躍的貢獻團隊之一, 為etcd的發展貢獻我們的一點力量, 在這過程中特別感謝社區AWS、Google、Ali等maintainer的支持與幫助。
從GitLab誤刪主庫丟失部分數據到GitHub數據不一致導致中斷24小時,再到號稱"不沉航母"的AWS S3故障數小時等,無一例外都是存儲服務。穩定性對于一個存儲服務、乃至一個公司的口碑而言至關重要,它決定著一個產品生與死。穩定性優化案例我們將從數據不一致的嚴重性、兩個etcd數據不一致的bug、lease內存泄露、mvcc 死鎖、wal crash方面闡述,我們是如何發現、分析、復現、解決以上case,并分享我們從每個case中的獲得的收獲和反思,從中汲取經驗,防患于未然。
談到數據不一致導致的大故障,就不得不詳細提下GitHub在18年一次因網絡設備的例行維護工作導致的美國東海岸網絡中心與東海岸主要數據中心之間的連接斷開。雖然網絡的連通性在43秒內得以恢復,但是短暫的中斷引發了一系列事件,最終導致GitHub 24小時11分鐘的服務降級,部分功能不可用。
GitHub使用了大量的MySQL集群存儲GitHub的meta data,如issue、pr、page等等,同時做了東西海岸跨城級別的容災。故障核心原因是網絡異常時GitHub的MySQL仲裁服務Orchestrator進行了故障轉移,將寫入數據定向到美國西海岸的MySQL集群(故障前primary在東海岸),然而美國東海岸的MySQL包含一小段寫入,尚未復制到美國西海岸集群,同時故障轉移后由于兩個數據中心的集群現在都包含另一個數據中心中不存在的寫入,因此又無法安全地將主數據庫故障轉移回美國東海岸。
最終, 為了保證保證用戶數據不丟失,GitHub不得不以24小時的服務降級為代價來修復數據一致性。
數據不一致的故障嚴重性不言而喻,然而etcd是基于raft協議實現的分布式高可靠存儲系統,我們也并未做跨城容災,按理數據不一致這種看起來高大上bug我們是很難遇到的。然而夢想是美好的,現實是殘酷的,我們不僅遇到了不可思議的數據不一致bug, 還一踩就是兩個,一個是重啟etcd有較低的概率觸發,一個是升級etcd版本時如果開啟了鑒權,在K8s場景下較大概率觸發。在詳細討論這兩個bug前,我們先看看在K8s場景下etcd數據不一致會導致哪些問題呢?
數據不一致最恐怖之處在于client寫入是成功的,但可能在部分節點讀取到空或者是舊數據,client無法感知到寫入在部分節點是失敗的和可能讀到舊數據
讀到空可能會導致業務Node消失、Pod消失、Node上Service路由規則消失,一般場景下,只會影響用戶變更的服務
讀到老數據會導致業務變更不生效,如服務擴縮容、Service rs替換、變更鏡像異常等待,一般場景下,只會影響用戶變更的服務
在etcd平臺遷移場景下,client無法感知到寫入失敗,若校驗數據一致性也無異常時(校驗時連接到了正常節點),會導致遷移后整個集群全面故障(apiserver連接到了異常節點),用戶的Node、部署的服務、lb等會被全部刪除,嚴重影響用戶業務
首先第一個不一致bug是重啟etcd過程中遇到的,人工嘗試復現多次皆失敗,分析、定位、復現、解決這個bug之路幾經波折,過程很有趣并充滿挑戰,最終通過我對關鍵點增加debug日志,編寫chaos monkey模擬各種異常場景、邊界條件,實現復現成功。最后的真兇竟然是一個授權接口在重啟后重放導致鑒權版本號不一致,然后放大導致多版本數據庫不一致, 部分節點無法寫入新數據, 影響所有v3版本的3年之久bug。
隨后我們提交若干個相關pr到社區, 并全部合并了, 最新的etcd v3.4.9[1],v3.3.22[2]已修復此問題, 同時google的jingyih也已經提K8s issue和pr[3]將K8s 1.19的etcd client及server版本升級到最新的v3.4.9。此bug詳細可參考超凡同學寫的文章三年之久的 etcd3 數據不一致 bug 分析。
第二個不一致bug是在升級etcd過程中遇到的,因etcd缺少關鍵的錯誤日志,故障現場有效信息不多,定位較困難,只能通過分析代碼和復現解決。然而人工嘗試復現多次皆失敗,于是我們通過chaos monkey模擬client行為場景,將測試環境所有K8s集群的etcd分配請求調度到我們復現集群,以及對比3.2與3.3版本差異,在可疑點如lease和txn模塊增加大量的關鍵日志,并對etcd apply request失敗場景打印錯誤日志。
通過以上措施,我們比較快就復現成功了, 最終通過代碼和日志發現是3.2版本與3.3版本在revoke lease權限上出現了差異,3.2無權限,3.3需要寫權限。當lease過期的時候,如果leader是3.2,那么請求在3.3節點就會因無權限導致失敗,進而導致key數量不一致,mvcc版本號不一致,導致txn事務部分場景執行失敗等。最新的3.2分支也已合并我們提交的修復方案,同時我們增加了etcd核心過程失敗的錯誤日志以提高數據不一致問題定位效率,完善了升級文檔,詳細說明了lease會在此場景下引起數據不一致性,避免大家再次采坑。
從這兩個數據不一致bug中我們獲得了以下收獲和最佳實踐:
算法理論數據一致性,不代表整體服務實現能保證數據一致性,目前業界對于這種基于日志復制狀態機實現的分布式存儲系統,沒有一個核心的機制能保證raft、wal、mvcc、snapshot等模塊協作不出問題,raft只能保證日志狀態機的一致性,不能保證應用層去執行這些日志對應的command都會成功
etcd版本升級存在一定的風險,需要仔細review代碼評估是否存在不兼容的特性,如若存在是否影響鑒權版本號及mvcc版本號,若影響則升級過程中可能會導致數據不一致性,同時一定要灰度變更現網集群
對所有etcd集群增加了一致性巡檢告警,如revision差異監控、key數量差異監控等
定時對etcd集群數據進行備份,再小概率的故障,根據墨菲定律都可能會發生,即便etcd本身雖具備完備的自動化測試(單元測試、集成測試、e2e測試、故障注入測試等),但測試用例仍有不少場景無法覆蓋,我們需要為最壞的場景做準備(如3個節點wal、snap、db文件同時損壞),降低極端情況下的損失, 做到可用備份數據快速恢復
etcd v3.4.4后的集群灰度開啟data corruption檢測功能,當集群出現不一致時,拒絕集群寫入、讀取,及時止損,控制不一致的數據范圍
繼續完善我們的chaos monkey和使用etcd本身的故障注入測試框架functional,以協助我們驗證、壓測新版本穩定性(長時間持續跑),復現隱藏極深的bug, 降低線上采坑的概率
眾所周知etcd是golang寫的,而golang自帶垃圾回收機制也會內存泄露嗎?首先我們得搞清楚golang垃圾回收的原理,它是通過后臺運行一個守護線程,監控各個對象的狀態,識別并且丟棄不再使用的對象來釋放和重用資源,若你遲遲未釋放對象,golang垃圾回收不是萬能的,不泄露才怪。比如以下場景會導致內存泄露:
goroutine泄露
deferring function calls(如for循環里面未使用匿名函數及時調用defer釋放資源,而是整個for循環結束才調用)
獲取string/slice中的一段導致長string/slice未釋放(會共享相同的底層內存塊)
應用內存數據結構管理不周導致內存泄露(如為及時清理過期、無效的數據)
接下來看看我們遇到的這個etcd內存泄露屬于哪種情況呢?事情起源于3月末的一個周末起床后收到現網3.4集群大量內存超過安全閾值告警,立刻排查了下發現以下現象:
QPS及流量監控顯示都較低,因此排除高負載及慢查詢因素
一個集群3個節點只有兩個follower節點出現異常,leader 4g,follower節點高達23G
goroutine、fd等資源未出現泄漏
go runtime memstats指標顯示各個節點申請的內存是一致的,但是follower節點go_memstats_heap_release_bytes遠低于leader節點,說明某數據結構可能長期未釋放
生產集群默認關閉了pprof,開啟pprof,等待復現, 并在社區上搜索釋放有類似案例, 結果發現有多個用戶1月份就報了,沒引起社區重視,使用場景和現象跟我們一樣
通過社區的heap堆棧快速定位到了是由于etcd通過一個heap堆來管理lease的狀態,當lease過期時需要從堆中刪除,但是follower節點卻無此操作,因此導致follower內存泄露, 影響所有3.4版本。
問題分析清楚后,我提交的修復方案是follower節點不需要維護lease heap,當leader發生選舉時確保新的follower節點能重建lease heap,老的leader節點則清空lease heap.
此內存泄露bug屬于內存數據結構管理不周導致的,問題修復后,etcd社區立即發布了新的版本(v3.4.6+)以及K8s都立即進行了etcd版本更新。
從這個內存泄露bug中我們獲得了以下收獲和最佳實踐:
持續關注社區issue和pr, 別人今天的問題很可能我們明天就會遇到
etcd本身測試無法覆蓋此類需要一定時間運行的才能觸發的資源泄露bug,我們內部需要加強此類場景的測試與壓測
持續完善、豐富etcd平臺的各類監控告警,機器留足足夠的內存buffer以扛各種意外的因素。
死鎖是指兩個或兩個以上的goroutine的執行過程中,由于競爭資源相互等待(一般是鎖)或由于彼此通信(chan引起)而造成的一種程序卡死現象,無法對外提供服務。deadlock問題因為往往是在并發狀態下資源競爭導致的, 一般比較難定位和復現, 死鎖的性質決定著我們必須保留好分析現場,否則分析、復現及其困難。
**那么我們是如何發現解決這個deadlock bug呢?**問題起源于內部團隊在壓測etcd集群時,發現一個節點突然故障了,而且一直無法恢復,無法正常獲取key數等信息。收到反饋后,我通過分析卡住的etcd進程和查看監控,得到以下結論:
不經過raft及mvcc模塊的rpc請求如member list可以正常返回結果,而經過的rpc請求全部context timeout
etcd health健康監測返回503,503的報錯邏輯也是經過了raft及mvcc
通過tcpdump和netstat排除raft網絡模塊異常,可疑目標縮小到mvcc
分析日志發現卡住的時候因數據落后leader較多,接收了一個數據快照,然后執行更新快照的時候卡住了,沒有輸出快照加載完畢的日志,同時確認日志未丟失
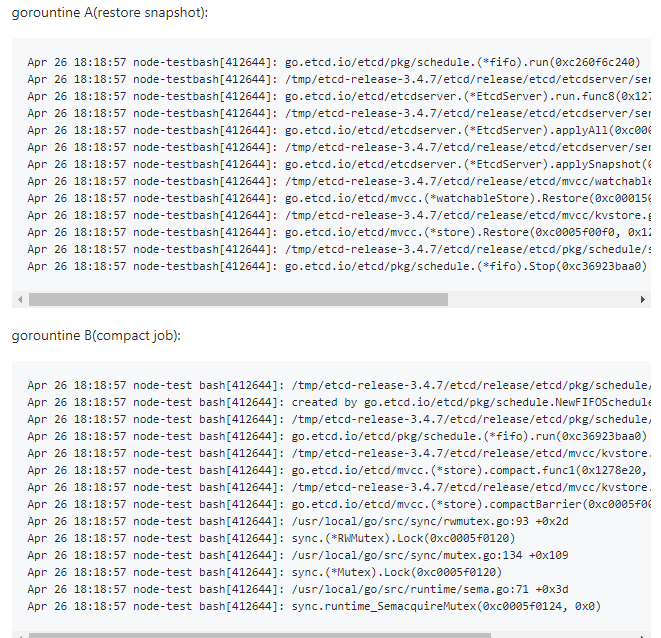
排查快照加載的代碼,鎖定幾個可疑的鎖和相關goroutine,準備獲取卡住的goroutine堆棧
通過kill或pprof獲取goroutine堆棧,根據goroutine卡住的時間和相關可疑點的代碼邏輯,成功找到兩個相互競爭資源的goroutine,其中一個正是執行快照加載,重建db的主goroutine,它獲取了一把mvcc鎖等待所有異步任務結束,而另外一個goroutine則是執行歷史key壓縮任務,當它收到stop的信號后,立刻退出,調用一個compactBarrier邏輯,而這個邏輯又恰恰需要獲取mvcc鎖,因此出現死鎖,堆棧如下。
這個bug也隱藏了很久,影響所有etcd3版本,在集群中寫入量較大,某落后的較多的節點執行了快照重建,同時此時又恰恰在做歷史版本壓縮,那就會觸發。我提交的修復PR目前也已經合并到3.3和3.4分支中,新的版本已經發布(v3.3.21+/v3.4.8+)。
從這個死鎖bug中我們獲得了以下收獲和最佳實踐:
多并發場景的組合的etcd自動化測試用例覆蓋不到,也較難構建,因此也容易出bug, 是否還有其他類似場景存在同樣的問題?需要參與社區一起繼續提高etcd測試覆蓋率(etcd之前官方博客介紹一大半代碼已經是測試代碼),才能避免此類問題。
監控雖然能及時發現異常節點宕機,但是死鎖這種場景之前我們不會自動重啟etcd,因此需要完善我們的健康探測機制(比如curl /health來判斷服務是否正常),出現死鎖時能夠保留堆棧、自動重啟恢復服務。
對于讀請求較高的場景,需評估3節點集群在一節點宕機后,剩余兩節點提供的QPS容量是否能夠支持業務,若不夠則考慮5節點集群。
panic是指出現嚴重運行時和業務邏輯錯誤,導致整個進程退出。panic對于我們而言并不陌生,我們在現網遇到過幾次,最早遭遇的不穩定性因素就是集群運行過程中panic了。
雖說我們3節點的etcd集群是可以容忍一個節點故障,但是crash瞬間對用戶依然有影響,甚至出現集群撥測連接失敗。
我們遇到的第一個crash bug,是發現集群鏈接數較多的時候有一定的概率出現crash, 然后根據堆棧查看社區已有人報grpc crash(issue)[4], 原因是etcd依賴的組件grpc-go出現了grpc crash(pr)[5],而最近我們遇到的crash bug[6]是v3.4.8/v3.3.21新版本發布引起的,這個版本跟我們有很大關系,**我們貢獻了3個PR到這個版本,占了一大半以上, 那么這個crash bug是如何產生以及復現呢?**會不會是我們自己的鍋呢?
首先crash報錯是walpb: crc mismatch, 而我們并未提交代碼修改wal相關邏輯,排除自己的鍋。
其次通過review新版本pr, 目標鎖定到google一位大佬在修復一個wal在寫入成功后,而snapshot寫入失敗導致的crash bug的時候引入的.
但是具體是怎么引入的?pr中包含多個測試用例驗證新加邏輯,本地創建空集群和使用存量集群(數據比較小)也無法復現.
錯誤日志信息太少,導致無法確定是哪個函數報的錯,因此首先還是加日志,對各個可疑點增加錯誤日志后,在我們測試集群隨便找了個老節點替換版本,然后很容易就復現了,并確定是新加的驗證快照文件合法性的鍋,那么它為什么會出現crc mismatch呢? 首先我們來簡單了解下wal文件。
etcd任何經過raft的模塊的請求在寫入etcd mvcc db前都會通過wal文件持久化,若進程在apply command過程中出現被殺等異常,重啟時可通過wal文件重放將數據補齊,避免數據丟失。wal文件包含各種請求命令如成員變化信息、涉及key的各個操作等,為了保證數據完整性、未損壞,wal每條記錄都會計算其的crc32,寫入wal文件。重啟后解析wal文件過程中,會校驗記錄的完整性,如果數據出現損壞或crc32計算算法出現變化則會出現crc32 mismatch.
硬盤及文件系統并未出現異常,排除了數據損壞,經過深入排查crc32算法的計算,發現是新增邏輯未處理crc32類型的數據記錄,它會影響crc32算法的值,導致出現差異,而且只有在當etcd集群創建產生后的第一個wal文件被回收才會觸發,因此對存量運行一段時間的集群,100%復現。
解決方案就是通過增加crc32算法的處理邏輯以及增加單元測試覆蓋wal文件被回收的場景,社區已合并并發布了新的3.4和3.3版本(v3.4.9/v3.3.22).
雖然這個bug是社區用戶反饋的,但從這個crash bug中我們獲得了以下收獲和最佳實踐:
單元測試用例非常有價值,然而編寫完備的單元測試用例并不容易,需要考慮各類場景。
etcd社區對存量集群升級、各版本之間兼容性測試用例幾乎是0,需要大家一起來為其舔磚加瓦,讓測試用例覆蓋更多場景。
新版本上線內部流程標準化、自動化, 如測試環境壓測、混沌測試、不同版本性能對比、優先在非核心場景使用(如event)、灰度上線等流程必不可少。
etcd面對一些大數據量的查詢(expensive read)和寫入操作時(expensive write),如全key遍歷(full keyspace fetch)、大量event查詢, list all Pod, configmap寫入等會消耗大量的cpu、內存、帶寬資源,極其容易導致過載,乃至雪崩。
然而,etcd目前只有一個極其簡單的限速保護,當etcd的commited index大于applied index的閾值大于5000時,會拒絕一切請求,返回Too Many Request,其缺陷很明顯,無法精確的對expensive read/write進行限速,無法有效防止集群過載不可用。
為了解決以上挑戰,避免集群過載目前我們通過以下方案來保障集群穩定性:
基于K8s apiserver上層限速能力,如apiserver默認寫100/s,讀200/s
基于K8s resource quota控制不合理的Pod/configmap/crd數
基于K8s controller-manager的-terminated-Pod-gc-threshold參數控制無效Pod數量(此參數默認值高達12500,有很大優化空間)
基于K8s的apiserver各類資源可獨立的存儲的特性, 將event/configmap以及其他核心數據分別使用不同的etcd集群,在提高存儲性能的同時,減少核心主etcd故障因素
基于event admission webhook對讀寫event的apiserver請求進行速率控制
基于不同業務情況,靈活調整event-ttl時間,盡量減少event數
基于etcd開發QoS特性,目前也已經向社區提交了初步設計方案,支持基于多種對象類型設置QoS規則(如按grpcMethod、grpcMethod+請求key前綴路徑、traffic、cpu-intensive、latency)
通過多維度的集群告警(etcd集群lb及節點本身出入流量告警、內存告警、精細化到每個K8s集群的資源容量異常增長告警、集群資源讀寫QPS異常增長告警)來提前防范、規避可能出現的集群穩定性問題
**多維度的集群告警在我們的etcd穩定性保障中發揮了重要作用,多次幫助我們發現用戶和我們自身集群組件問題。**用戶問題如內部某K8s平臺之前出現bug, 寫入大量的集群CRD資源和client讀寫CRD QPS明顯偏高。我們自身組件問題如某舊日志組件,當集群規模增大后,因日志組件不合理的頻繁調用list Pod,導致etcd集群流量高達3Gbps, 同時apiserver本身也出現5XX錯誤。
雖然通過以上措施,我們能極大的減少因expensive read導致的穩定性問題,然而從線上實踐效果看,目前我們仍然比較依賴集群告警幫助我們定位一些異常client調用行為,無法自動化的對異常client的進行精準智能限速,。etcd層因無法區分是哪個client調用,如果在etcd側限速會誤殺正常client的請求, 因此依賴apiserver精細化的限速功能實現。社區目前已在1.18中引入了一個API Priority and Fairness[7],目前是alpha版本,期待此特性早日穩定。
etcd讀寫性能決定著我們能支撐多大規模的集群、多少client并發調用,啟動耗時決定著我們當重啟一個節點或因落后leader太多,收到leader的快照重建時,它重新提供服務需要多久?性能優化案例剖析我們將從啟動耗時減少一半、密碼鑒權性能提升12倍、查詢key數量性能提升3倍等來簡單介紹下如何對etcd進行性能優化。
當db size達到4g時,key數量百萬級別時,發現重啟一個集群耗時竟然高達5分鐘, key數量查詢也是超時,調整超時時間后,發現高達21秒,內存暴漲6G。同時查詢只返回有限的記錄數的場景(如業務使用etcd grpc-proxy來減少watch數,etcd grpc proxy在默認創建watch的時候,會發起對watch路徑的一次limit讀查詢),依然耗時很高且有巨大的內存開銷。于是周末空閑的時候我對這幾個問題進行了深入調查分析,啟動耗時到底花在了哪里?是否有優化空間?查詢key數量為何如何耗時,內存開銷如此之大?
帶著這些問題對源碼進行了深入分析和定位,首先來看查詢key數和查詢只返回指定記錄數的耗時和內存開銷極大的問題,分析結論如下:
查詢key數量時etcd之前實現是遍歷整個內存btree,把key對應的revision存放在slice數組里面
問題就在于key數量較多時,slice擴容涉及到數據拷貝,以及slice也需要大量的內存開銷
因此優化方案是新增一個CountRevision來統計key的數量即可,不需要使用slice,此方案優化后性能從21s降低到了7s,同時無任何內存開銷
對于查詢指定記錄數據耗時和內存開銷非常大的問題,通過分析發現是limit記錄數并未下推到索引層,通過將查詢limit參數下推到索引層,大數據場景下limit查詢性能提升百倍,同時無額外的內存開銷。
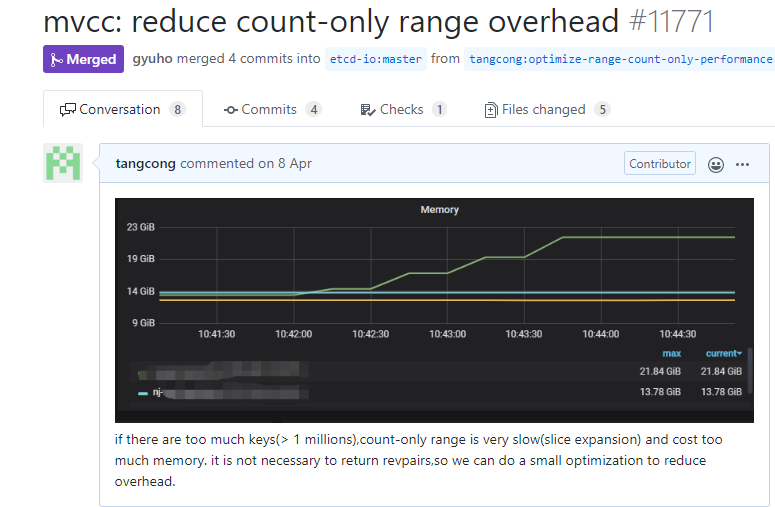

再看啟動耗時問題過高的問題,通過對啟動耗時各階段增加日志,得到以下結論:
啟動的時候機器上的cpu資源etcd進程未能充分利用
9%耗時在打開后端db時,如將整個db文件mmap到內存
91%耗時在重建內存索引btree上。當etcd收到一個請求Get Key時,請求被層層傳遞到了mvcc層后,它首先需要從內存索引btree中查找key對應的版本號,隨后從boltdb里面根據版本號查出對應的value, 然后返回給client. 重建內存索引btree數的時候,恰恰是相反的流程,遍歷boltdb,從版本號0到最大版本號不斷遍歷,從value里面解析出對應的key、revision等信息,重建btree,因為這個是個串行操作,所以操作及其耗時
嘗試將串行構建btree優化成高并發構建,盡量把所有核計算力利用起來,編譯新版本測試后發現效果甚微,于是編譯新版本打印重建內存索引各階段的詳細耗時分析,結果發現瓶頸在內存btree的插入上,而這個插入擁有一個全局鎖,因此幾乎無優化空間
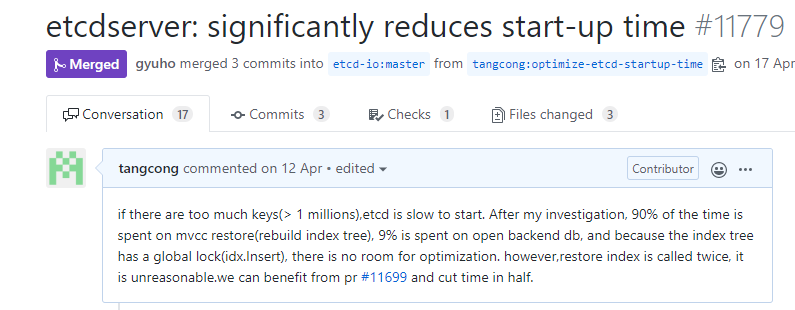
繼續分析91%耗時發現重建內存索引竟然被調用了兩次,第一處是為了獲取一個mvcc的關鍵的consistent index變量,它是用來保證etcd命令不會被重復執行的關鍵數據結構,而我們前面提到的一個數據不一致bug恰好也是跟consistent index有密切關系。
consistent index實現不合理,封裝在mvcc層,因此我前面提了一個pr將此特性重構,做為了一個獨立的包,提供各類方法給etcdserver、mvcc、auth、lease等模塊調用。
特性重構后的consistent index在啟動的時候就不再需要通過重建內存索引數等邏輯來獲取了,優化成調用cindex包的方法快速獲取到consistent index,就將整個耗時從5min從縮短到2分30秒左右。因此優化同時依賴的consistent index特性重構,改動較大暫未backport到3.4/3.3分支,在未來3.5版本中、數據量較大時可以享受到啟動耗時的顯著提升。
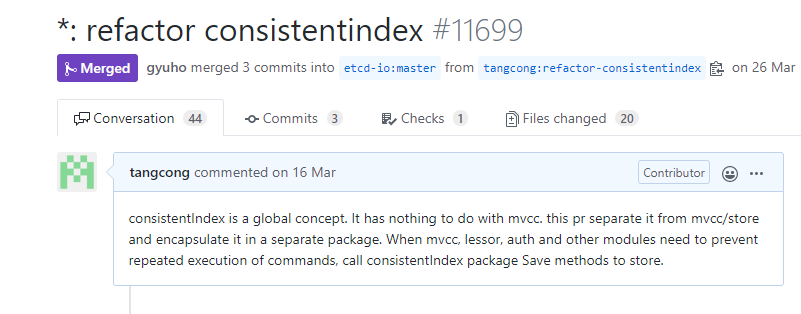
某內部業務服務一直跑的好好的,某天client略微增多后,突然現網etcd集群出現大量超時,各種折騰,切換云盤類型、切換部署環境、調整參數都不發揮作用,收到求助后,索要metrics和日志后,經過一番排查后,得到以下結論:
現象的確很詭異,db延時相關指標顯示沒任何異常,日志無任何有效信息
業務反饋大量讀請求超時,甚至可以通過etcdctl客戶端工具簡單復現,可是metric對應的讀請求相關指標數竟然是0
引導用戶開啟trace日志和metrics開啟extensive模式,開啟后發現無任何trace日志,然而開啟extensive后,我發現耗時竟然全部花在了Authenticate接口,業務反饋是通過密碼鑒權,而不是基于證書的鑒權
嘗試讓業務同學短暫關閉鑒權測試業務是否恢復,業務同學找了一個節點關閉鑒權后,此節點立刻恢復了正常,于是選擇臨時通過關閉鑒權來恢復現網業務
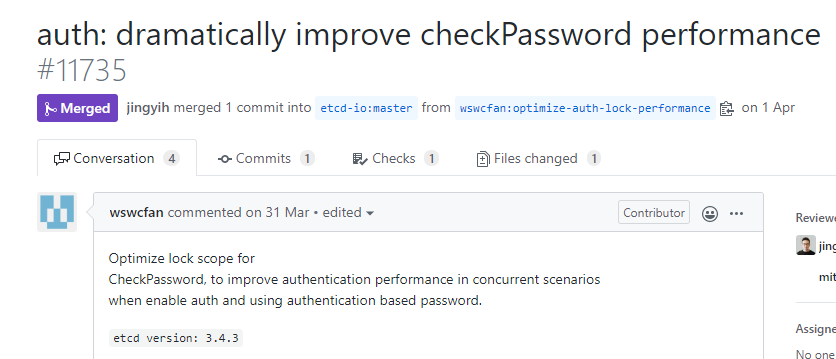
那鑒權為什么耗時這么慢?我們對可疑之處增加了日志,打印了鑒權各個步驟的耗時,結果發現是在等待鎖的過程中出現了超時,而這個鎖為什么耗時這么久呢?排查發現是因為加鎖過程中會調用bcrpt加密函數計算密碼hash值,每次耗費60ms左右,數百并發下等待此鎖的最高耗時高達5s+。
于是我們編寫新版本將鎖的范圍減少,降低持鎖阻塞時間,用戶使用新版本后,開啟鑒權后,業務不再超時,恢復正常。
隨后我們將修復方案提交給了社區,并編寫了壓測工具,測試提升后的性能高達近12倍(8核32G機器,從18/s提升到202/s),但是依然是比較慢,主要是鑒權過程中涉及密碼校驗計算, 社區上也有用戶反饋密碼鑒權慢問題, 目前最新的v3.4.9版本已經包含此優化, 同時可以通過調整bcrpt-cost參數來進一步提升性能。
“萬級K8s集群穩定性及性能優化的方法是什么”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





