溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關怎么用Arthas來診斷 HBase異常進程的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
HBase 集群的某一個 RegionServer 的 CPU 使用率突然飆升到百分之百,單獨重啟該 RegionServer 之后,CPU 的負載依舊會逐漸攀上頂峰。多次重啟集群之后,CPU 滿載的現象依然會復現,且會持續居高不下,慢慢地該 RegionServer 就會宕掉,慢慢地 HBase 集群就完犢子了。
CDH 監控頁面來看,除 CPU 之外的幾乎所有核心指標都是正常的,磁盤和網絡 IO 都很低,內存更是充足,壓縮隊列,刷新隊列也是正常的。
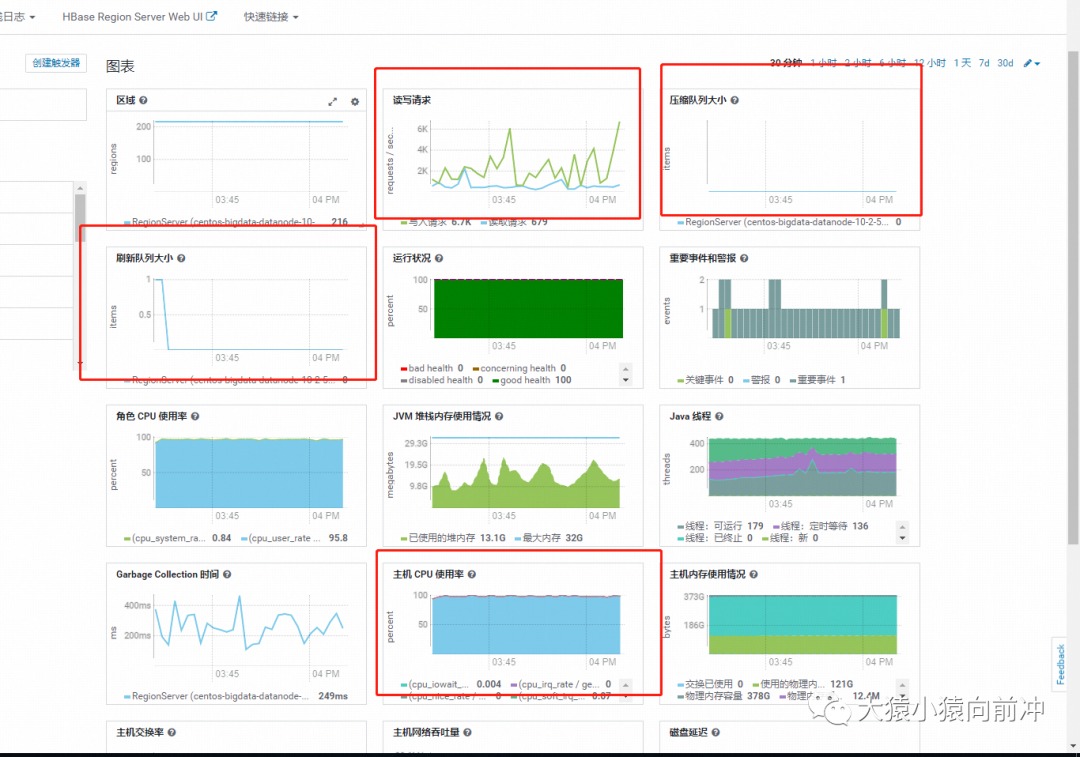
普羅米修斯的監控也是類似這樣的,就不貼圖了。
監控指標里的數字,只能直觀地告訴我們現象,不能告訴我們異常的起因。因此我們的第二反應是看日志。
與此同時,日志中還有很多類似這樣的干擾輸出。

后來發現這樣的輸出只是一些無關緊要的信息,對分析問題沒有任何幫助,甚至會干擾我們對問題的定位。
但是,日志中大量 scan responseTooSlow 的警告信息,似乎在告訴我們,HBase 的 Server 內部正在發生著大量耗時的 scan 操作,這也許就是 CPU 負載高的元兇。可是,由于各種因素的作用,我們當時的關注點并沒有在這個上面,因為這樣的信息,我們在歷史的時間段里也頻繁撞見。
監控和日志都不能讓我們百分百確定 CPU 負載高是由哪些操作引起的,我們用 top 命令也只能看到 HBase 這個進程消耗了很多 CPU,就像下圖看到的這樣。
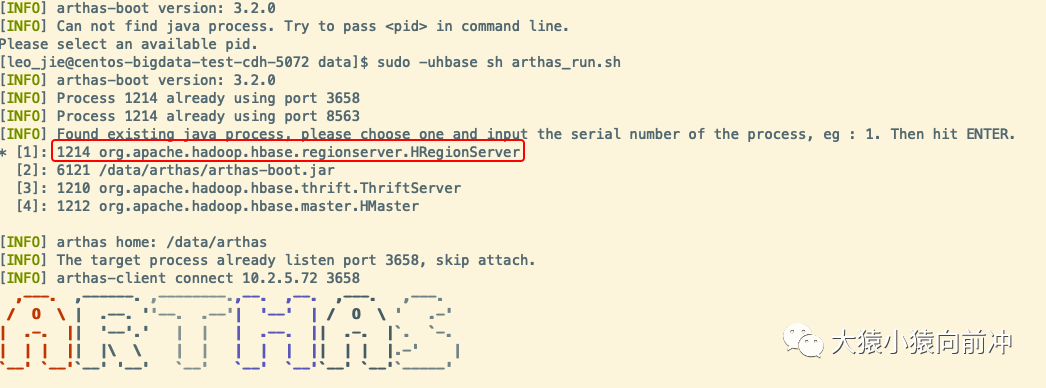
命令 top 定位到的異常的 HBase 進程 ID 是 1214,該進程就是 HRegionServer 的進程。輸入序號 1,回車,就進入了監聽該進程的命令行界面。

輸入 thread 命令回車,查看該進程下所有線程的執行情況。
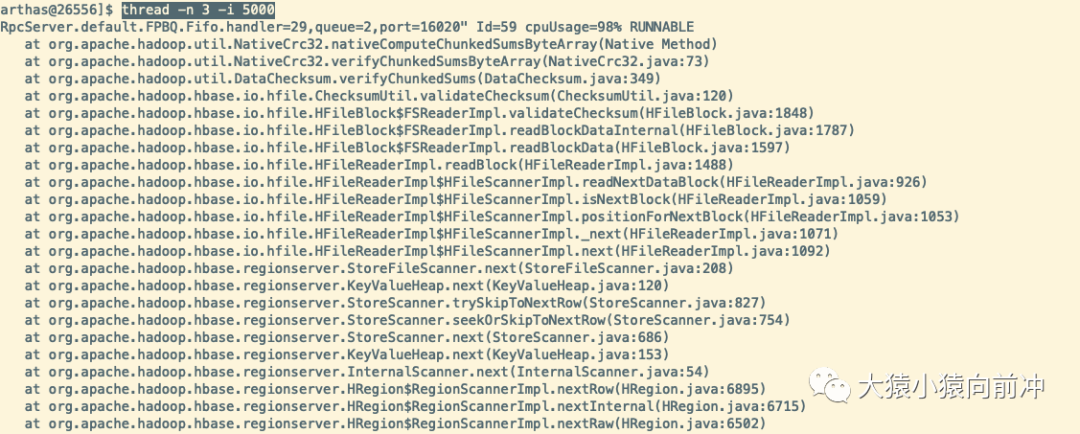
單位時間為 5 秒內,資源占用前三名的線程。
生成火焰圖的最簡單命令。
profiler start
隔一段時間,大概三十秒。
profiler stop

關于火焰圖的入門級知識:
查看 jvm 進程 cpu 火焰圖工具。
火焰圖里很清楚地定位到 CPU 時間占用最高的線程是綠框最長的那些線程,也就是 scan 操作。
通過以上的進程分析,我們最終可以確定,scan 操作的發生,導致 CPU 負載很高。我們查詢 HBase 的 API 基于 happybase 封裝而成。
其實常規的 scan 操作是能正常返回結果的,發生異常查詢的表也不是很大,所以我們排除了熱點的可能。抽象出來業務方的查詢邏輯是:
from happybase.connection import Connectionimport time
start = time.time()
con = Connection(host='ip', port=9090, timeout=3000)
table = con.table("table_name")
try:
res = list(table.scan(filter="PrefixFilter('273810955|')", row_start='\x0f\x10&R\xca\xdf\x96\xcb\xe2\xad7$\xad9khE\x19\xfd\xaa\x87\xa5\xdd\xf7\x85\x1c\x81ku ^\x92k', limit=3))
except Exception as e:
pass
end = time.time()print 'timeout: %d' % (end - start)PrefixFilter 和 row_start 的組合是為了實現分頁查詢的需求,row_start 的一堆亂碼字符,是加密的一個 user_id,里面有特殊字符。日志中看到,所有的耗時查詢,都有此類亂碼字符的傳參。于是,我們猜想,查詢出現的異常與這些亂碼字符有關。
但是,后續測試復現的時候又發現。
# 會超時
res = list(table.scan(filter="PrefixFilter('273810955|')", row_start='27', limit=3))
# 不會超時
res = list(table.scan(filter="PrefixFilter('273810955|')", row_start='27381095', limit=3))也就是,即使不是亂碼字符傳參,filter 和 row_start 組合異常,也會導致 CPU 異常的高,row_start 指定的過小,小于前綴,數據掃描的范圍估計就會變大,類似觸發了全表掃描,CPUload 勢必會變大。
我們操作 HBase 的公共代碼是由 happybase 封裝而成,其中還用到了 happybase 的線程池,在我們更深入的測試中又發現了一個現象,當我們使用連接池或在循環中重復創建連接時,然后用 arthas 監控線程情況,發現 scan 的線程會很嚴重,測試代碼如下:
from happybase.connection import Connectionimport time
con = Connection(host='ip', port=9090, timeout=2000)
table = con.table("table")for i in range(100):
try:
start = time.time()
res = list(table.scan(filter="PrefixFilter('273810955|')", row_start='\x0f\x10&R\xca\xdf\x96\xcb\xe2\xad7$\xad9khE\x19\xfd\xaa\x87\xa5\xdd\xf7\x85\x1c\x81ku ^\x92k', limit=3))
except Exception as e:
pass
end = time.time()print 'timeout: %d' % (end - start)程序開始運行時,可以打開 arthas 進入到 HRegionServer 進程的監控,運行 thread 命令,查看此時的線程使用情況:
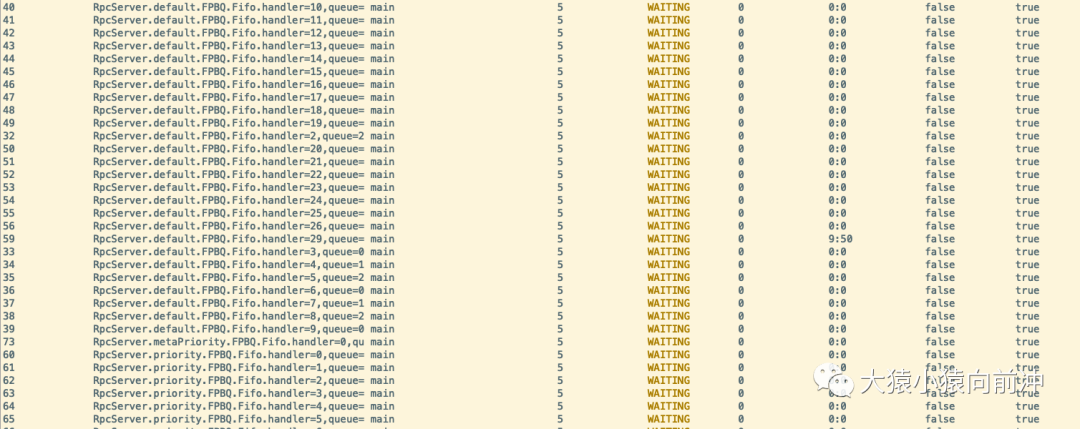
小部分在運行,大部分在等待。此時,CPU 的負載情況:
代碼如下:
from happybase.connection import Connectionimport timefor i in range(100):
try:
start = time.time()
con = Connection(host='ip', port=9090, timeout=2000)
table = con.table("table")
res = list(table.scan(filter="PrefixFilter('273810955|')", row_start='\x0f\x10&R\xca\xdf\x96\xcb\xe2\xad7$\xad9khE\x19\xfd\xaa\x87\xa5\xdd\xf7\x85\x1c\x81ku ^\x92k', limit=3))
except Exception as e:
pass
end = time.time()print 'timeout: %d' % (end - start)下圖中可以看到開始 RUNNING 的線程越來越多,CPU 的消耗也越來越大。

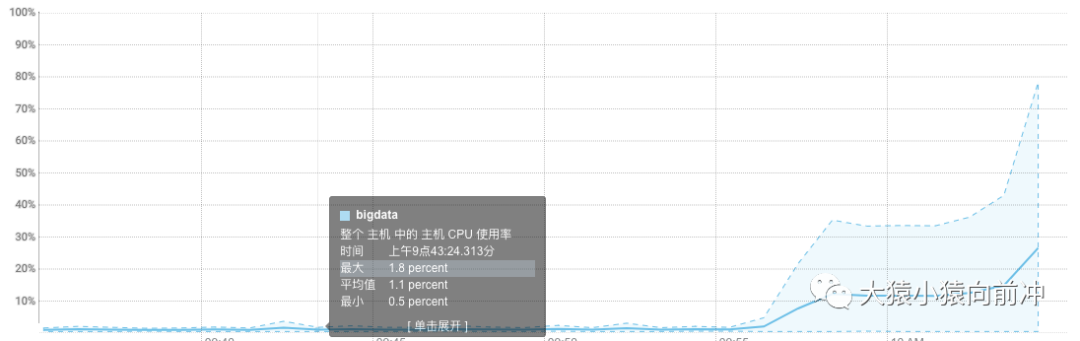
CPU 被之前的實驗拉高,重啟下集群使 CPU 的狀態恢復到之前平穩的狀態。然后繼續我們的測試,測試代碼:
沒有超時時間
from happybase import ConnectionPool
import timepool = ConnectionPool(size=1, host='ip', port=9090)for i in range(100):
start = time.time()
try:
with pool.connection(2000) as con:
table = con.table("table")
res = list(table.scan(filter="PrefixFilter('273810955|')", row_start='\x0f\x10&R\xca\xdf\x96\xcb\xe2\xad7$\xad9khE\x19\xfd\xaa\x87\xa5\xdd\xf7\x85\x1c\x81ku ^\x92k', limit=3))
except Exception as e:
pass
end = time.time()print 'timeout: %d' % (end - start)如果不指定超時時間,會只有一個線程持續運行,因為我的連接池設置為 1。
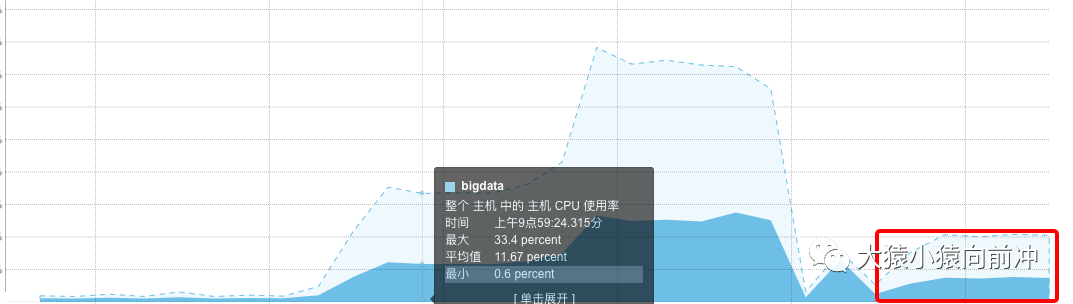
指定超時時間
from happybase import ConnectionPool
import timepool = ConnectionPool(size=1, host='ip', port=9090, timeout=2000)for i in range(100):
start = time.time()
try:
with pool.connection(2000) as con:
table = con.table("table")
res = list(table.scan(filter="PrefixFilter('273810955|')", row_start='\x0f\x10&R\xca\xdf\x96\xcb\xe2\xad7$\xad9khE\x19\xfd\xaa\x87\xa5\xdd\xf7\x85\x1c\x81ku ^\x92k', limit=3))
except Exception as e:
pass
end = time.time()print 'timeout: %d' % (end - start)此次測試中,我指定了連接池中的超時時間,期望的是,連接超時,及時斷開,繼續下一次耗時查詢。此時,服務端處理 scan 請求的線程情況:
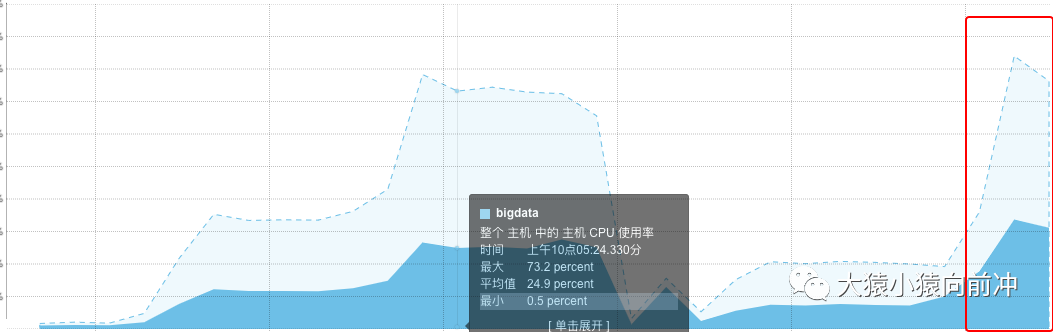
參考大神的博客,以及自己對這個參數的理解,每一個客戶端發起的 RPC 請求(讀或寫),發送給服務端的時候,服務端就會有一個線程池,專門負責處理這些客戶端的請求,這個線程池可以保證同一時間點有 30 個線程可運行,剩余請求要么阻塞,要么被塞進隊列中等待被處理,scan 請求撐滿了服務端的線程池,大量的耗時操作,把 CPU 資源消耗殆盡,其余常規的讀寫請求也勢必大受影響,慢慢集群就完犢子了。
首先,這個 hbase.regionserver.handler.count 的參數不能被調小,如果太小,集群并發高時,讀寫延時必高,因為大部分請求都在排隊。理想情況是,讀和寫占用不同的線程池,在處理讀請求時,scan 和 get 分別占用不同的線程池,實現線程池資源隔離。如果是我的話,第一反應可能也會簡單、粗略地搞仨線程池,寫線程池,get 線程池、scan 線程池。scan 線程池分配很小的核心線程,讓其占用很小的資源,限制其無限擴張。但是真實的情況是這樣嗎?暫時,我還沒仔細研究源碼,HBase 提供了如下參數,可以滿足讀寫資源分離的需求。
hbase.regionserver.handler.count
描述 在RegionServer上旋轉的RPC偵聽器實例數。主機將相同的屬性用于主機處理程序的計數。過多的處理程序可能適得其反。使它成為CPU計數的倍數。如果大多數情況下是只讀的,則處理程序計數接近cpu計數的效果很好。從兩倍的CPU計數開始,然后從那里進行調整。 默認30
hbase.ipc.server.callqueue.handler.factor
描述 確定呼叫隊列數量的因素。值為0表示在所有處理程序之間共享一個隊列。值為1表示每個處理程序都有自己的隊列。 默認0.1
hbase.ipc.server.callqueue.read.ratio
描述 將呼叫隊列劃分為讀寫隊列。指定的間隔(應在0.0到1.0之間)將乘以呼叫隊列的數量。值為0表示不拆分呼叫隊列,這意味著讀取和寫入請求都將被推送到同一組隊列中。小于0.5的值表示讀隊列少于寫隊列。值為0.5表示將有相同數量的讀取和寫入隊列。大于0.5的值表示將有比寫隊列更多的讀隊列。值1.0表示除一個隊列外的所有隊列均用于調度讀取請求。示例:給定呼叫隊列的總數為10,讀比率為0表示:10個隊列將包含兩個讀/寫請求。read.ratio為0.3表示:3個隊列將僅包含讀取請求,而7個隊列將僅包含寫入請求。read.ratio為0.5表示:5個隊列僅包含讀取請求,而5個隊列僅包含寫入請求。read.ratio為0.8表示:8個隊列將僅包含讀取請求,而2個隊列將僅包含寫入請求。read.ratio為1表示:9個隊列將僅包含讀取請求,而1個隊列將僅包含寫入請求。 默認0
hbase.ipc.server.callqueue.scan.ratio
描述 給定讀取呼叫隊列的數量(根據呼叫隊列總數乘以callqueue.read.ratio計算得出),scan.ratio屬性會將讀取呼叫隊列分為小讀取隊列和長讀取隊列。小于0.5的值表示長讀隊列少于短讀隊列。值為0.5表示將有相同數量的短讀和長讀隊列。大于0.5的值表示長讀取隊列比短讀取隊列多。值為0或1表示使用相同的隊列進行獲取和掃描。示例:假設讀取呼叫隊列的總數為8,則scan.ratio為0或1表示:8個隊列將同時包含長讀取請求和短讀取請求。scan.ratio為0.3表示:2個隊列將僅包含長讀請求,而6個隊列將僅包含短讀請求。scan.ratio為0.5表示:4個隊列將僅包含長讀請求,而4個隊列將僅包含短讀請求。scan.ratio為0.8表示:6個隊列將僅包含長讀請求,而2個隊列將僅包含短讀請求。 默認0
這幾個參數的作用官網解釋的還挺詳細,按照其中的意思,配置一定比例,就可以達到讀寫隊列,get 和 scan 隊列分離的目的,但是,調配參數后,繼續如上測試,發現,并不難控制 RUNNING 的線程的數量,發現沒毛用。
這里有一個疑問,隊列和我所理解的線程池直接到底是什么關系?是否是一個東西?這個之后需要觀其源碼,窺其本質。
感謝各位的閱讀!關于“怎么用Arthas來診斷 HBase異常進程”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





