溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
[TOC]
? 在Hadoop1.x中,MapReduce中本身負責資源的調度以及業務邏輯運算,耦合度較大,而且當時只支持MapReduce一個框架。
? 在Hadoop2.x中,增加了yarn,專門負責資源的調度,MapReduce只負責業務邏輯運算,而且yarn之上可以運算其他的分布式計算框架,如spark等。
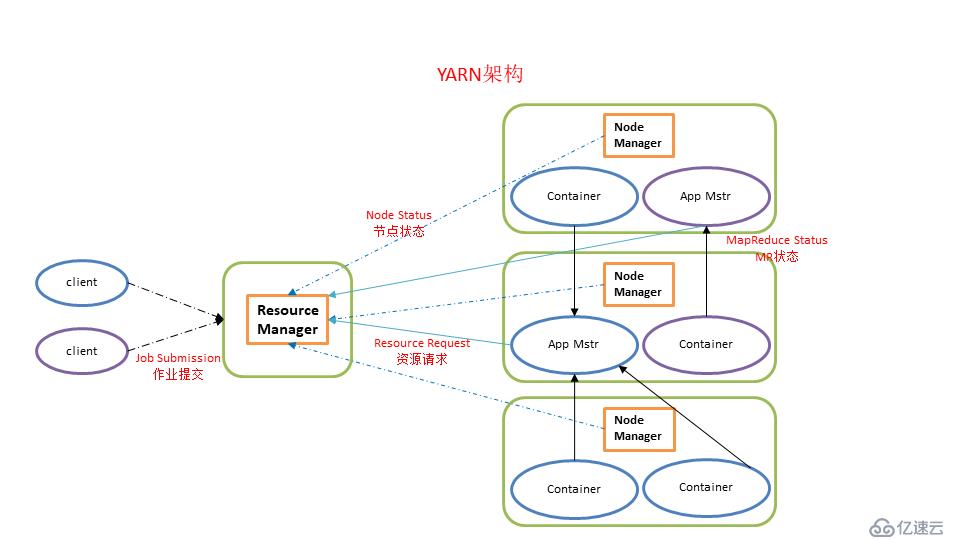
? 圖2.1 yarn基本結構
主要分為 RM(ResourceManager),NM(NodeManager)、AM(ApplicationMaster)。
資源:
在 YARN 的語境下,資源特指計算資源,包括 CPU 和內存。計算機的每個進程都會占用一定的 CPU 和內存,任務需要先向 RM 申請到資源后才能獲準在 NM 上啟動自己的進程。隊列:
YARN 將整個集群的資源劃分為隊列,每個用戶的任務必須提交到指定隊列。同時限制每個隊列的大小,防止某個用戶的任務占用整個集群,影響了其他用戶的使用。vcore、Mem:
邏輯 CPU 和邏輯內存,每個 NM 會向 RM 匯報自己有多少 vcore 和內存可用,具體數值由集群管理員配置。比如一臺48核,128G內存的機器,可以配置40vcore,120G內存,意為可以對外提供這么多資源。具體數值可能根據實際情況有所調整。每個 NM 的邏輯資源加起來,就是整個集群的總資源量。MinResources & MaxResources:
為了使每個隊列都能得到一定的資源,同時又不浪費集群的空閑資源,隊列的資源設置都是“彈性”的。每個隊列都有 min 和 max 兩個資源值,min 表示只要需求能達到,集群一定會提供這么多資源;如果資源需求超過了 min 值而同時集群仍有空閑資源,則仍然可以滿足;但又限制了資源不能無限申請以免影響其他任務,資源的分配不會超過 max 值。這里是指整個隊列獲得的資源總數container:
任務申請到資源后在 NM 上啟動的進程統稱 Container。比如在 MapReduce 中可以是 Mapper 或 Reducer,在 Spark 中可以是 Driver 或 Executor。RM(ResourceManager),NM(NodeManager)、AM(ApplicationMaster):
ResourceManager(rm):
處理客戶端請求、啟動/監控ApplicationMaster、監控NodeManager、資源分配與調度
NodeManager(nm):
單個節點上的資源管理、處理來自ResourceManager的命令、處理來自ApplicationMaster的命令
ApplicationMaster:
數據切分、為應用程序申請資源,并分配給內部任務、任務監控與容錯。其實就是MapReduce任務的driver端程序運行的地方。用于任務的調度。前面的RM和NM都是用于資源調度1)用戶使用客戶端向 RM 提交一個任務job,同時指定提交到哪個隊列和需要多少資源。用戶可以通過每個計算引擎的對應參數設置,如果沒有特別指定,則使用默認設置。
2)RM 在收到任務提交的請求后,先根據資源和隊列是否滿足要求選擇一個 NM,通知它啟動一個特殊的 container,稱為 ApplicationMaster(AM),后續流程由它發起。每個任務只有一個AM。
3)AM 向 RM 注冊后根據自己任務的需要,向 RM 申請 container,包括數量、所需資源量、所在位置等因素。
4)如果隊列有足夠資源,RM 會將 container 分配給有足夠剩余資源的 NM,由 AM 通知 NM 啟動 container。
5)container 啟動后執行具體的任務,處理分給自己的數據。NM 除了負責啟動 container,還負責監控它的資源使用狀況以及是否失敗退出等工作,如果 container 實際使用的內存超過申請時指定的內存,會將其殺死,保證其他 container 能正常運行。
6)各個 container 向 AM 匯報自己的進度,都完成后,AM 向 RM 注銷任務并退出,RM 通知 NM 殺死對應的 container,任務結束。
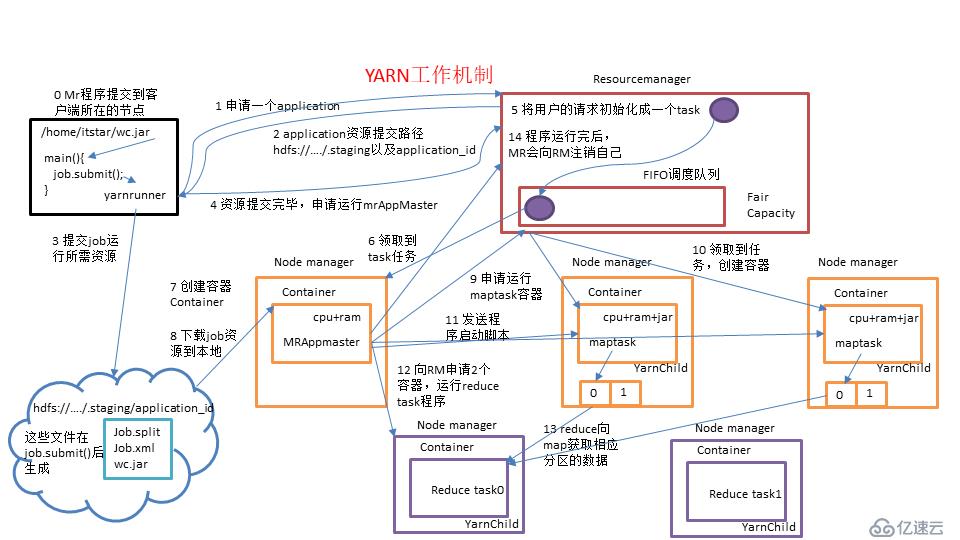
? 圖3.1 yarn工作機制
(0)Mr程序提交到客戶端所在的節點。
(1)Yarnrunner向Resourcemanager申請一個Application
(2)RM將該應用程序的資源路徑返回給yarnrunner。
(3)該程序將運行所需資源提交到HDFS上,放到hdfs指定目錄下,如上圖所示,資源主要有3部分,一是所有切片信息的規劃文件,二是job的一個運行配置文件(包含job的一些運行參數等),三是MapReduce程序的jar包了
(4)程序資源提交完畢后,申請運行mrAppMaster。
(5)RM將用戶的請求初始化成一個task。
(6)其中一個NodeManager領取到task任務。
(7)該NodeManager創建容器Container,并產生MRAppmaster。
(8)Container從HDFS上拷貝資源到本地。
(9)MRAppmaster向RM 申請運行maptask資源。
(10)RM將運行maptask任務分配給另外兩個NodeManager,另兩個NodeManager分別領取任務并創建容器
(11)MR向兩個接收到任務的NodeManager發送程序啟動腳本,這兩個NodeManager分別啟動maptask,maptask對數據分區排序。
(12)MrAppMaster等待所有maptask運行完畢后,向RM申請容器,運行reduce task。
(13)reduce task向maptask獲取相應分區的數據。
(14)程序運行完畢后,appMaster會向RM申請注銷自己。
yarn會為任務分配資源,這個過程中涉及到資源的調度,目前yarn支持的資源調度器有三種:FIFO、capacity scheduler、fair scheduler。目前默認的是 capacity scheduler
//yarn-default.xml
<property>
<description>The class to use as the resource scheduler.</description>
<name>yarn.resourcemanager.scheduler.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>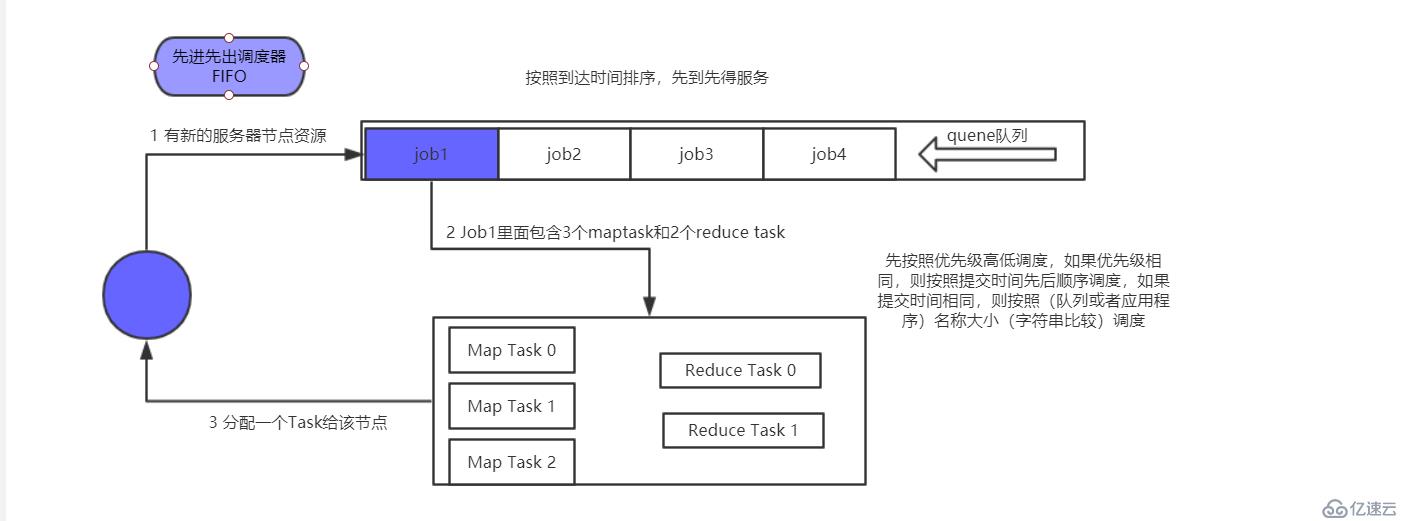
? 圖4.1 FIFO調度器
優點:調度算法簡單,JobTracker(job提交任務后發送得地方)工作負擔輕。
缺點:忽略了不同作業的需求差異。例如如果類似對海量數據進行統計分析的作業長期占據計算資源,那么在其后提交的交互型作業有可能遲遲得不到處理,從而影響到用戶的體驗。
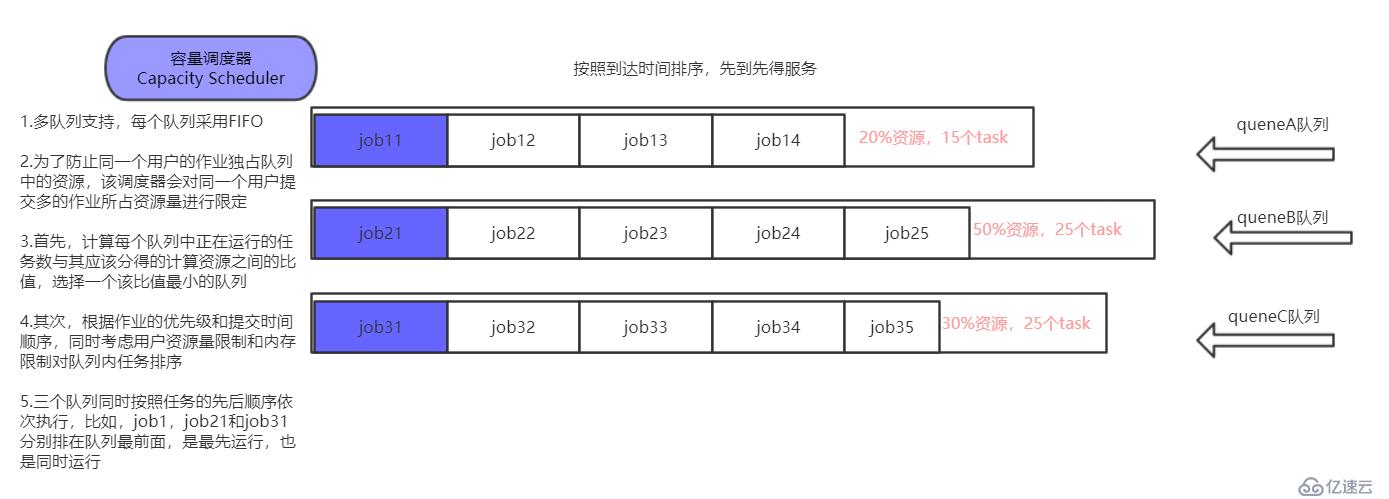
? 圖 4.2 capacity scheduler調度器
1.多隊列支持,每個隊列采用FIFO
2.為了防止同一個用戶的作業獨占隊列中的資源,該調度器會對同一個用戶提交多的作業所占資源量進行限定
3.首先,計算每個隊列中正在運行的任務數與其應該分得的計算資源(隊列中已有任務總共應該分的資源的總和)之間的比值,選擇一個該比值最小的隊列
4.其次,根據作業的優先級和提交時間順序,同時考慮用戶資源量限制和內存限制對隊列內任務排序
5.三個隊列同時按照任務的先后順序依次執行,比如,job1,job21和job31分別排在隊列最前面,是最先運行,也是同時運行
該調度默認情況下不支持優先級,但是可以在配置文件中開啟此選項,如果支持優先級,調度算法就是帶有優先級的FIFO。
不支持優先級搶占,一旦一個作業開始執行,在執行完之前它的資源不會被高優先級作業所搶占。
對隊列中同一用戶提交的作業能夠獲得的資源百分比進行了限制以使同屬于一用戶的作業不能出現獨占資源的情況。即同一用戶在不同隊列所能使用的資源的百分比
?
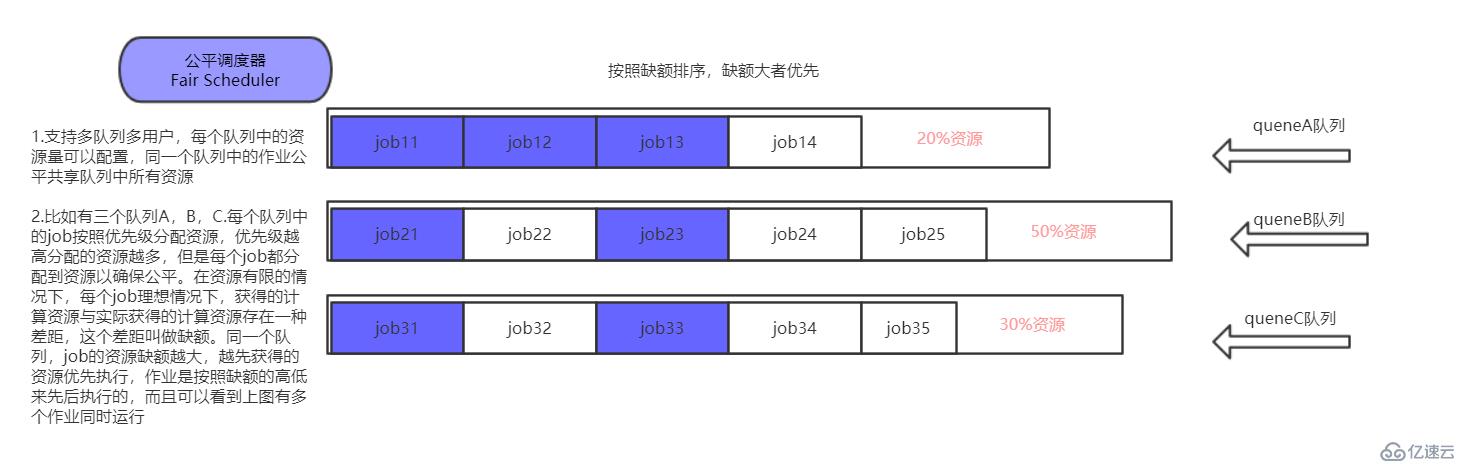
? 圖 4.3 fair scheduler調度器
1.支持多隊列多用戶,每個隊列中的資源量可以配置,同一個隊列中的作業公平共享隊列中所有資源
2.比如有三個隊列A,B,C.每個隊列中的job按照優先級分配資源,優先級越高分配的資源越多,但是每個job都分配到資源以確保公平。在資源有限的情況下,每個job理想情況下,獲得的計算資源與實際獲得的計算資源存在一種差距,這個差距叫做缺額。同一個隊列,job的資源缺額越大,越先獲得的資源優先執行,作業是按照缺額的高低來先后執行的,而且可以看到上圖有多個作業同時運行
推測執行(Speculative Execution)是指在集群環境下運行MapReduce,可能是程序Bug,負載不均或者其他的一些問題,導致在一個JOB下的多個TASK速度不一致,比如有的任務已經完成,但是有些任務可能只跑了10%,根據木桶原理,這些任務將成為整個JOB的短板,如果集群啟動了推測執行,這時為了最大限度的提高短板,Hadoop會為該task啟動備份任務,讓speculative task與原始task同時處理一份數據,哪個先運行完,則將誰的結果作為最終結果,并且在運行完成后Kill掉另外一個任務。
發現拖后腿的任務,比如某個任務運行速度遠慢于任務平均速度。為拖后腿任務啟動一個備份任務,同時運行。誰先運行完,則采用誰的結果。并且運行完之后,會將未執行完成的任務直接kill掉。
1)每個task只能有一個備份任務;
2)當前job已完成的task必須不小于5%;
3)不能啟用推測執行的情況:任務間存在嚴重負載傾斜;特殊任務,比如任務向數據庫中寫入數據;
4)開啟推測執行參數設置,mapred-site.xml中默認是打開的
開啟map任務的推測執行
<property>
<name>mapreduce.map.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some map tasks may be executed in parallel.</description>
</property>
開啟reduce任務的推測執行
<property>
<name>mapreduce.reduce.speculative</name>
<value>true</value>
<description>If true, then multiple instances of some reduce tasks
may be executed in parallel.</description>
</property>
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





