溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Python爬蟲某東商品評論信息采集流程分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Python爬蟲某東商品評論信息采集流程分析”吧!
一、接口查找
隨意點擊某一商品,跳轉詳情頁,點擊商品評價

繼續下翻,查看評論展示頁數,這里只顯示100頁
要查找真正的評論接口,直接刷新頁面,找起來相當麻煩。
打開調試,清空請求內容,直接點擊查看第二頁的接口信息,如下圖
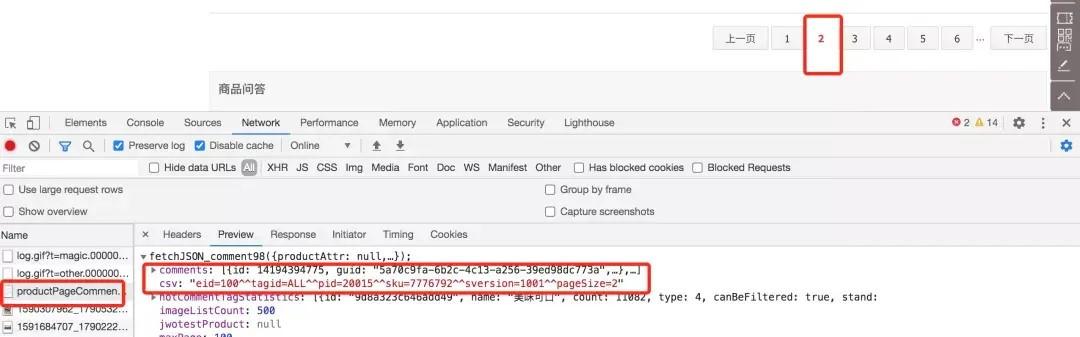
查看response信息,根據字段comments很容易判斷這就是要找的評論接口,里面還包含了熱門評論信息。
二、參數查找
先截圖記錄下點擊第二頁的請求參數
接著繼續點擊第三頁內容,左側搜索框中直接搜索productP,過濾無用的接口信息,查看請求參數,并和前一頁的請求參數做比較。
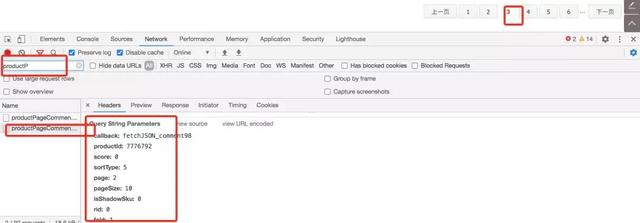
分析到這里可以得到如下結論
productId代表當前商品的ID,更換商品ID,便可以采集不同商品的評論
page代表訪問的頁數,這里計算頁數從0開始,參數請求的頁數等于實際點擊的頁數減1
三、代碼測試
代碼如下,請求時需要在headers中加入ua和referer,這里翻頁只設置2
執行結果如下:

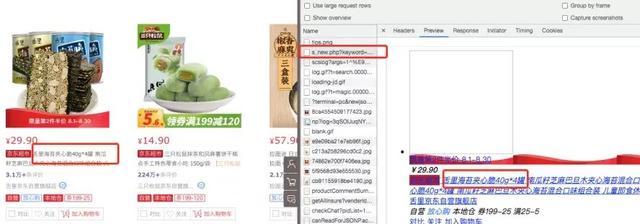
代碼里只提取了商品ID,評論內容,評論時間,如下圖紅框標注的數據
如果要提取其他字段信息,可在代碼中自行添加。
一、接口查找
搜索以食品為例,輸入食品,點擊搜索

繼續下翻,查看商品返回頁數,這里也是最大返回100頁信息
二、參數查找
同樣的,根據下滑,翻頁查看參數的變化

頁面上商品展示信息較多,有可能出現會臨時加載一次請求的可能,繼續下翻,恰好可以看到新增了一次請求,請求參數如下,看著參數增多了。(注意:新增的參數可以忽略)
接著點擊第三頁

如果無法發現規律,可繼續點擊翻頁查看變化規則。
接口參數的構造邏輯有以下幾點:
每一頁有兩次請求,page初始值為1
s的值每次請求增加25,初始值為1
其他參數值不變,部分新增參數可以忽略
三、html頁面解析
直接定位到頁面商品位置,可以看到所有商品信息都在ul標簽下的li標簽里面
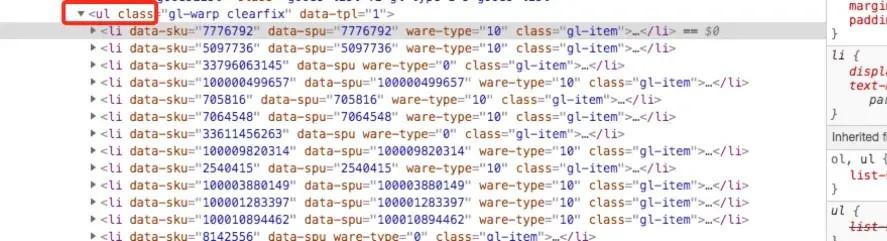
點擊li標簽,可以看到div/div下的a標簽里面,包含商品title信息,商品鏈接信息,鏈接當中又包含我們需要提取的product_id信息,右鍵copy、copy xpath直接提取位置信息。
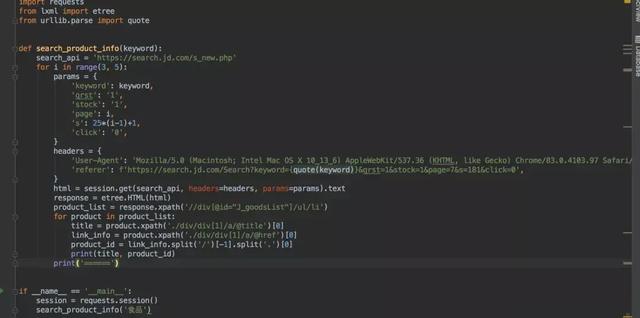
四、代碼測試
代碼如下,注意headers中,referer參數需要進行url編碼。
感謝各位的閱讀,以上就是“Python爬蟲某東商品評論信息采集流程分析”的內容了,經過本文的學習后,相信大家對Python爬蟲某東商品評論信息采集流程分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





