溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
hbase的sql解決方案是怎樣的,很多新手對此不是很清楚,為了幫助大家解決這個難題,下面小編將為大家詳細講解,有這方面需求的人可以來學習下,希望你能有所收獲。
最近的需求是希望能用mysql、sqlserver這樣的sql來進行hbase的數據查詢,這樣不但查詢比起hbase自帶的查詢語言更符合使用習慣,也能夠整合mybatis、hibernate的框架,寫起來不用考慮這么多。我上網一搜:“hbase sql查詢”,phoenix有最多的教程貼。被這么多人使用,肯定有它的獨到之處,并且劣勢不會那么難以接受,那么我先用phoenix試試效果,看看感受如何。
首先phoenix的安裝并不困難,簡單來說下載對應hbase版本的phoenix,解壓之后把對應包放入每個hbase RegionServer的lib下面,重啟hbase就可以了。我的hadoop是cdh 6.3.0版本,在安裝的時候沒有遇到什么困難。之后進入phoenix的安裝位置的bin目錄,執行sqlline.py,就能在shell中進入phoenix的使用界面了。
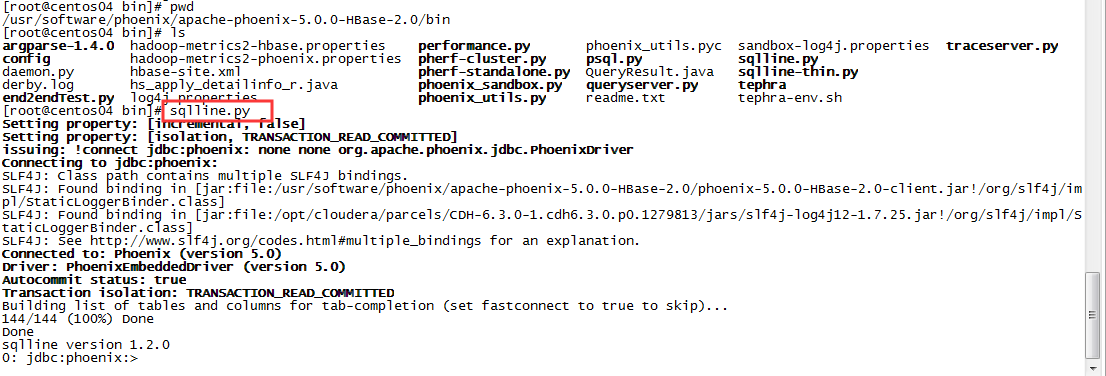
安裝成功,先試試phoenix的一些基礎操作,比如!tables,create table等等。都沒有問題,使用習慣也和mysql差不多。比較大的不同之處在于插入和更新都用的是upsert,這和hbase也是比較類似的。
在linux上使用也沒有問題,那么接下來就是使用javaApi進行連接。連接方式也并不困難,和其它組件差不多,配置連接信息然后就能連接了。具體怎么配網上教程很多,我就不做搬運工了。隨便找個鏈接【十二】Phoenix Java API操作 同質化內容那么多,總要說點自己的東西。值得一提的是phoenix是用jdbc連接的,配置看上去就和mysql的連接一樣,顯然這是十分友好的。在按照上面教程操作過后,我感覺十分欣喜,不愧是眾多教程所推薦的中間件,使用起來太舒爽了(除了手動加兩個phoenix的包,也不知道能不能在pom文件里面配置自動加載這樣不值一提的小問題),就連我這樣的小白都能輕松使用。不過教程上面的表都是直接建立在默認命名空間的,假如我想建立在指定命名空間,那應該怎么辦呢?
按照之前的習慣,我直接將表名改為 命名空間.表名,但是報了錯,表示沒有找到namespace.table這張表。是因為我用的.出錯了嗎?我將.改為:,但還是報錯,報錯信息只是將namespace.table改為namespace:table,說明錯誤類型都是一樣的,錯誤不在這里。
上網搜索“phoenix 指定命名空間”,大量的帖子告訴了我一件事:phoenix想要使用命名空間映射,需要額外的配置。這里要說一下,很多教程寫的不完全一樣,有的多一些有的少一些,按照經驗來說,多配置一些更不容易出問題。給出一個配置比較全的帖子:HBase - Phoenix的安裝使用教程3(SCHEMA的啟用、操作、關閉) 。在我看各種關于如何開啟phoenix命名空間映射帖子的時候,有些帖子提到這個功能不但無法正常使用,反而還把原本正常的功能弄出問題了。關于如何關閉在上面這個帖子里面也有,我在使用過程中沒有遇到,給大家看看以防萬一。
我當時看的帖子是cdh版的,帖子現在找不到了,配置內容是在web頁面完成的,配置內容更多一些,我把完成后的結果給大家看看,步驟基本都差不多,方法不同而已。
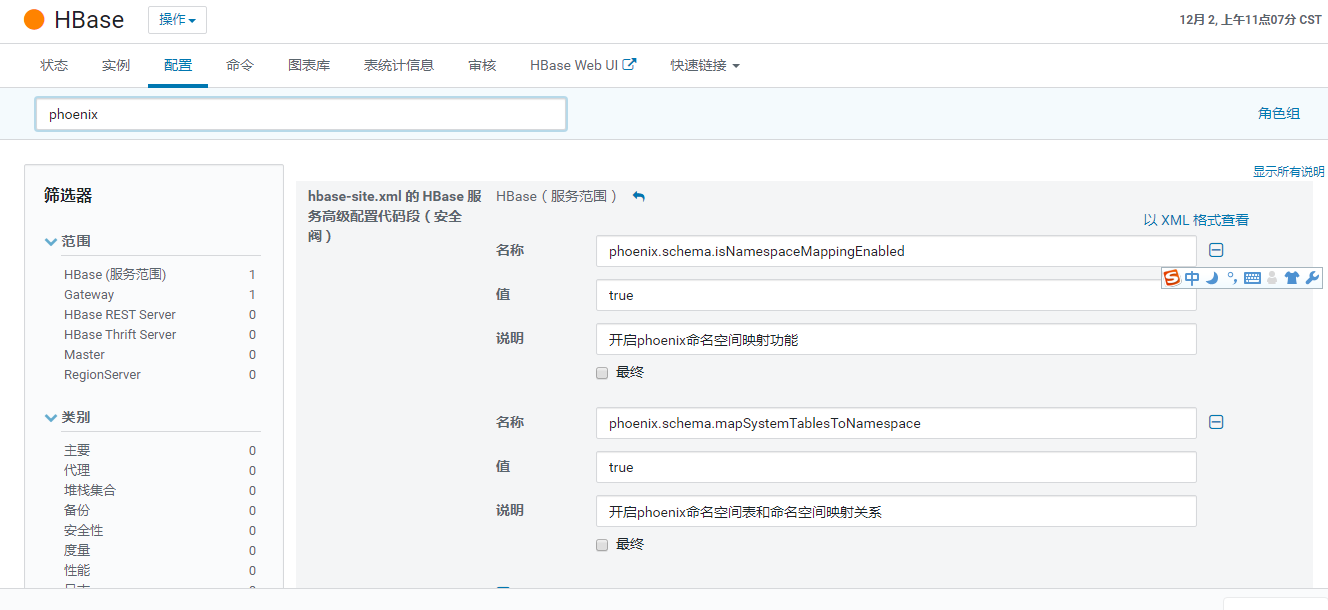

分別在客戶端和服務端配置信息,并將這兩個配置寫入phoenix的bin目錄的hbase.site.xml文件內。

之后重啟hbase,在shell中進入phoenix,就能夠使用create schema 來創建命名空間了。
再試試用java api來連接,先將之前下載的hbase.site.xml換成現在的,然后再次連接,報錯配置信息錯誤,和我之前新加的phoenix配置有關。感覺像是我哪里配置沒配好,找半天也找不到。本著先能用的方式在創建phoenix連接的時候手動加入配置:
Properties pros = new Properties();
pros.setProperty("phoenix.schema.isNamespaceMappingEnabled", "true");
pros.setProperty("phoenix.schema.mapSystemTablesToNamespace", Boolean.toString(true));之后再創建的連接就沒有問題了。能夠直接查詢多個命名空間下面的表,相當于跨庫查詢。要注意的一點是:當你使用shell進入phoenix創建命名空間下面的表時,需要先use schema,然后才能創建表。但是在你使用java api進行創建的時候就不需要這么麻煩,直接 create table schema.table即可,不需要像shell中一樣那么麻煩。假如像shell中一樣先use schema 再create table反而會報錯。關于這一點我倒是沒看到有教程提到,明明這才是比較有價值的東西。
舉個栗子:
public static void selectTable() throws SQLException{
String sql = "select * from ENTERPRISE_INFORMATION.TEST_PHOENIX_API a left join ENTERPRISE_INFORMATION.TEST_PHOENIX_API2 b on a.mykey = b.mykey ";
rs = stat.executeQuery(sql);
JSONArray array = resultSetToJosnArray(rs);
System.out.println(array.toJSONString());
}
public static void testCreateTable() throws SQLException {
String sql="create table ENTERPRISE_INFORMATION.test_phoenix_api2(mykey integer not null primary key ,mycolumn varchar )";
stat.executeUpdate(sql);
conn.commit();
}
public static void upsert() throws SQLException {
String sql1="upsert into ENTERPRISE_INFORMATION.test_phoenix_api2 values(1,'test4')";
String sql2="upsert into ENTERPRISE_INFORMATION.test_phoenix_api2 values(2,'test5')";
String sql3="upsert into ENTERPRISE_INFORMATION.test_phoenix_api2 values(3,'test6')";
stat.executeUpdate(sql1);
stat.executeUpdate(sql2);
stat.executeUpdate(sql3);
conn.commit();
}
public static void delete() throws SQLException {
String sql1="delete from ENTERPRISE_INFORMATION.test_phoenix_api where mykey = 1";
stat.executeUpdate(sql1);
conn.commit();
}
public static void deleteTable() throws SQLException {
String sql = "drop table ENTERPRISE_INFORMATION.test_phoenix_api";
stat.executeUpdate(sql);
conn.commit(); 創建連接之后,執行的表名直接使用schema.table即可,不加雙引號的情況下,無論大小寫都會被轉換成大寫。在執行select的時候,要使用rs = stat.executeQuery(sql);在增刪改的時候,使用stat.executeUpdate(sql)。假如在增刪改的時候使用executeQuery,可能會報錯。另外還要注意一點,phoenix在識別string類型數據的時候要使用單引號而不是雙引號,雙引號會報錯無法識別,這一點無論是在shell還是java api執行的時候都是一樣的,比如我上面的sql:
"upsert into ENTERPRISE_INFORMATION.test_phoenix_api2 values(1,'test4')";
test4是用單引號包起來的,這一點一定要注意。
我之前使用的是squirrel-3.7.1來進行phoenix的圖形化界面操作。配置比較簡單,需要把phoenix的驅動加入,之后寫下phoenix的jdbc連接就可以了。使用還算,并且能夠連接多種數據庫。但是在我進行phoenix命名空間映射后,就無法連接上了。報錯和我之前通過java api連接報錯一樣,缺少關于phoenix.schema的配置。這一點沒法解決,我真找不到哪里的配置有問題。網上大把的教程沒能解決我這個問題,最后我只有放棄squirrel,而是使用shell來操作phoenix。
以上都是小問題,還在我的接受范圍之內。那么接下來就是要將phoenix和hbase已有的表進行映射。按照我對phoenix的理解,phoenix在使用上是和mysql一樣的,schema映射為命名空間,table假如沒有就在hbase中新建一個表并且將它們映射在一起,我操作phoenix中的表就能將修改轉換成hbase的語句;假如table和hbase已有表名一樣那么就新建映射,操作還是一樣的。那么最好hbase中的表名本身就是大寫,我就不用特地用雙引號修飾表名,寫起來方便很多。
事實上我的想法沒有錯,只要映射的表名相同,那么就能夠通過phoenix來修改hbase的數據。但是當我通過phoenix修改已有數據的時候,我發現了一件奇怪的事——phoenix不能看見hbase已有數據,但是假如把phoenix表刪掉的話,hbase表也會一起被刪掉,這說明映射是成功的。但是為什么在phoenix中會看不到數據呢?在hbase中是能夠看到的數據的,當我嘗試用phoenix往映射表中加數據,再在hbase中查看數據時,發現了一件奇怪的事:
hbase創表(通過sqoop將mysql表導入hbase):
sqoop import \ --connect jdbc:mysql://192.168.49.201:3306/envir \ --username root \ --password Hskj123456! \ --table hs_apply_detailinfo_r \ --hbase-table ENVIR:HS_APPLY_DETAILINFO_R \ --m 1 \ --column-family 0 \ --hbase-create-table \ --hbase-row-key ID
phoenix創表:
CREATE TABLE envir.hs_apply_detailinfo_r ( ID varchar primary key, APPLY_TYPE varchar , APPLY_ID varchar , MAT_CD varchar , MAT_NUM double , PRODUCE_TIME date , OUTDATE_TIME date, SUP_CD varchar )
phoenix修改數據:
upsert envir.hs_apply_detailinfo_r (ID,APPLY_ID) values ('10','2');在phoenix中查看envir.hs_apply_detailinfo_r的數據,能看到新加的數據,并且只有這一條,hbase導入的表的數據是沒有的。再到hbase中scan一下,發現了表中新加了數據,而不是修改原來row為10 ,列為0:APPLY_ID的單元格,而是新加了一個單元格,列限定符為十六進制碼,而不是我在phoenix中輸入的APPLY_ID;并且值也不是我所輸入的字符串2,而是一串十六進制碼。在hue中,我也無法查看由phoenix映射的表的數據。
這個問題比較大,直接影響到我是否會繼續使用phoenix,但是我又不是很明白哪里出了問題,在網上一直搜索,大概知道了問題出在phoenix在保存字符的時候處理方式和hbase是不一樣的,假如phoenix表字段要映射到hbase表字段,要加上column_encoded_bytes=0;并且字段屬性要修改,能用unsigned_的盡量用unsigned_。
Phoenix 映射已存在 HBase 表,查詢不到數據
phoenix映射hbase中數據類型問題
所以phoenix表的創建應該改為:
CREATE TABLE envir.hs_apply_detailinfo_r( "ID" varchar primary key, "info"."APPLY_TYPE" VARBINARY, "info"."APPLY_ID" VARBINARY, "info"."MAT_CD" varchar, "info"."MAT_NUM" UNSIGNED_DOUBLE, "info"."PRODUCE_TIME" UNSIGNED_DATE, "info"."OUTDATE_TIME" UNSIGNED_DATE, "info"."SUP_CD" varchar)column_encoded_bytes=0;
我將列族改為了info,所以上面用sqoop導入的時候也應該將--column-family改為info。0是在phoenix不指定列族的時候默認列族。
修改之后,表字段映射的問題解決了,我能修改row=10,列為info:APPLY_TYPE單元格的值了。但是數值的問題依然沒有解決,我在phoenix輸入的值為‘2’,在hbase查看的結果依然是十六進制碼。這個問題有點無解,太底層了,我看了phoenix官網給出的關于數據類型轉換的介紹(http://phoenix.apache.org/language/datatypes.html) ,里面沒有解決辦法。其它網友也遇到了類似的問題,給出的解決辦法是:當用hbase存儲的時候,先用Bytes.toBytes()壓縮成phoenix的形式,這樣就能用phoenix來獲得hbase所插入的數據了。
此外,phoenix存儲hbase的int時會有問題,會報錯字段長度不夠。還是以上的hbase表和phoenix表,假如我先創建phoenix表,再通過sqoop將數據導入hbase,就會報錯字段長度不夠(hbase-presto-phoenix遇到的坑)。那么假如要使用phoenix,我就需要放棄很多東西,數據的導入不能用sqoop導入,而要手寫map/reduce;數據的查詢修改都要使用phoenix,不然無法正確識別。從mysql向HBase+Phoenix遷移數據的心得總結 中寫了一些解決方案,但是我看不懂,對我來說太難了,而且太麻煩了。與其繼續堅持下去,不如換個合適的中間件來滿足需求。
我同事用了antdb(antdb官網),我大概看了它的使用過程,和phoenix感覺差不多,創建一個虛擬的mysql來映射hbase表,讓用戶可以像修改mysql一樣修改hbase數據。但是不能設置主鍵,一些像phoenix的特性不知道有沒有,并且在我使用過程中RegionServer直接被停了,不知道什么原因。感覺太不成熟,也沒有什么教程貼來教教我如何用,還是當做備用方案,先去看看simplehbase如何使用吧。
看完上述內容是否對您有幫助呢?如果還想對相關知識有進一步的了解或閱讀更多相關文章,請關注億速云行業資訊頻道,感謝您對億速云的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





