溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關大數據中如何分析Lambda架構,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
一致性:
每個節點讀取的是最新結果或者是報錯。
可用性:
每個請求都會收到一個(非錯誤)響應,但不保證它包含最新的寫入。
分區容錯:
盡管節點之間的網絡丟棄(或延遲了)任意數量的消息,系統仍繼續運行。
2011年,內森·馬茲(Nathan Marz)在他的博客中提出了一種解決 CAP 定理局限性的重要方法,即 Lambda 架構。

讓我們仔細看看 Lambda 架構。Lambda 架構分為三層: 批處理層(batch layer),加速層(speed layer),和服務層(serving layer)。
它結合了對同一數據的實時(real-time)和批量(batches)處理。
首先,傳入的實時數據流在批處理層(batch layer)存儲在主數據集中,并在加速層(speed layer)存儲在內存緩存中。然后對批處理層中的數據建索引,且通過批處理視圖使之可用。加速層(speed layer)中的實時數據通過實時視圖(real-time views)暴露出來。最后,批處理視圖和實時視圖都可以獨立查詢,也可以一起查詢,以回答任何歷史的或實時的問題。
該層負責管理主數據集。主數據集中的數據必須具有以下三個屬性。
數據是原始的
數據是不可變的
數據永遠是真實的
主數據集是正確性的保證(source of truth)。即使丟失所有服務層數據集和加速層數據集,也可以從主數據集中重建應用程序。
批處理層還將主數據集預計算到批處理視圖(batch views)中,以便能進行低延遲查詢。
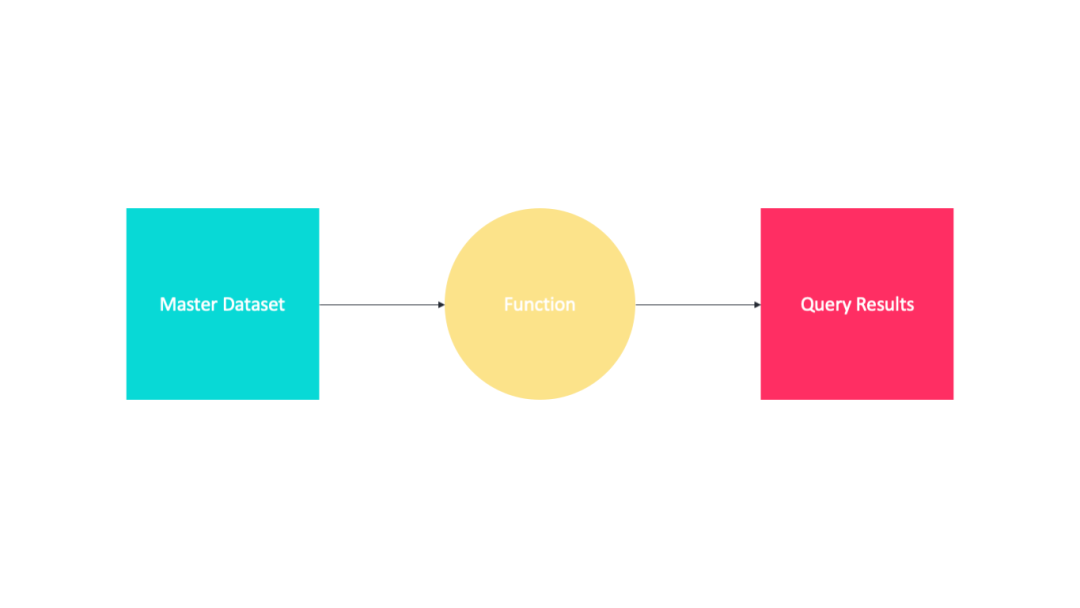 由于我們的主數據集在不斷增長,因此我們必須制定一種策略,以便在有新數據可用時管理批處理視圖(batch views)。
由于我們的主數據集在不斷增長,因此我們必須制定一種策略,以便在有新數據可用時管理批處理視圖(batch views)。
重新計算法:
拋棄舊的批處理視圖,重新計算整個主數據集的函數。
增量算法:
當新數據到達時,直接更新視圖。
加速層批處理視圖建立索引便于能快速的即席查詢(Ad hoc queries),它存儲實時視圖并處理傳入的數據流,以便更新這些視圖。基礎存儲層必須滿足以下場景。
隨機讀:
支持快速隨機讀取以快速響應查詢。
隨機寫:
為了支持增量算法,必須盡可能的以低延遲修改實時視圖。
可伸縮性:
實時視圖應隨它們存儲的數據量和應用程序所需的讀/寫速率進行縮放。
容錯性:
當機器故障,實時視圖應還能繼續正常運行。
該層提供了主數據集上執行的計算結果的低延遲訪問。讀取速度可以通過數據附加的索引來加速。與加速層類似,該層也必須滿足以下要求,例如隨機讀取,批量寫入,可伸縮性和容錯能力。
Lambda 體系結構基于幾個假定:容錯、即席查詢、可伸縮性、可擴展性。
容錯: Lambda 架構為大數據系統提供了更友好的容錯能力,一旦發生錯誤,我們可以修復算法或從頭開始重新計算視圖。
即席查詢: 批處理層允許針對任何數據進行臨時查詢。
可伸縮性: 所有的批處理層、加速層和服務層都很容易擴展。
因為它們都是完全分布式的系統,我們可以通過增加新機器來輕松地擴大規模。
擴展: 添加視圖是容易的,只是給主數據集添加幾個新的函數。
解決此問題的方法之一是通過使用通用庫或引入流之間共享的某種抽象來為各層提供通用代碼庫。譬如 Summingbird or Lambdoop,Casado 這些框架
是的,在許多應用程序中都不需要速度層(speed layer)。如果我們縮短批處理周期,則可以減少數據可用性中的延遲。另一方面,用于訪問存儲在 Hadoop 上的數據的新的更快的工具(例如 Impala , Drill 或 Tez 的新版本等),使在合理時間內對數據執行某些操作成為可能。
是的,一個例子是 Kappa Kreps 架構,它的示例建議在流中處理傳入的數據,并且每當需要更大的歷史記錄時,它將從 Kafka 緩沖區中重新流化,或者如果我們必須進一步追溯到歷史數據集群。
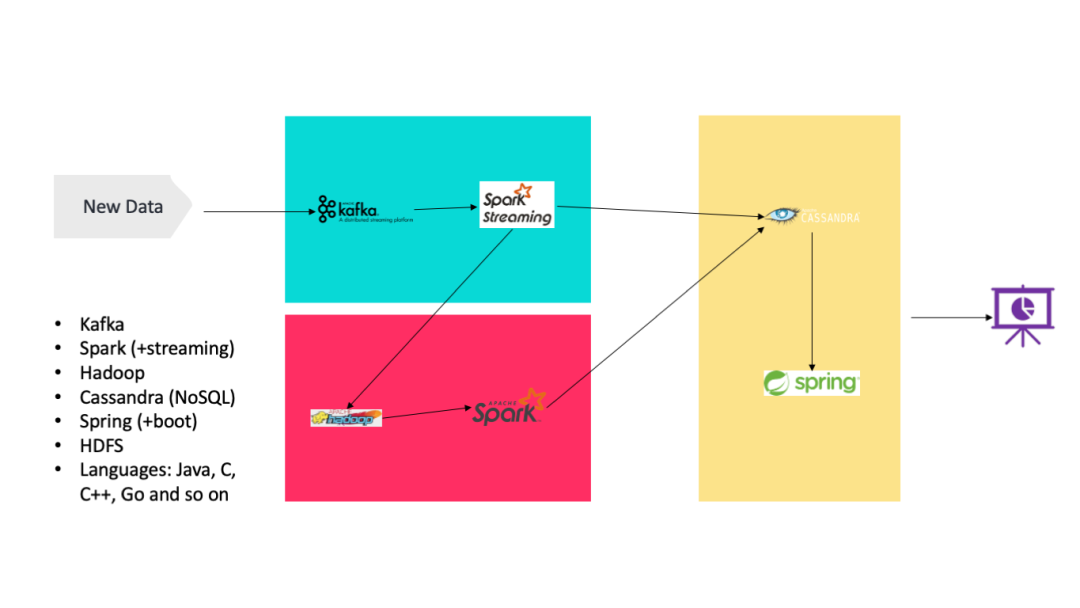
我們可以使用 Hadoop 數據湖在現實世界中實現此架構,在該數據湖中,HDFS 用于存儲主數據集, Spark(或 Storm)可構成速度層(speed layer), HBase(或 Cassandra)作為服務層,由 Hive 創建可查詢的視圖。
Spark 數據傾斜及其解決方案
為了在廣告數據倉庫上進行分析,雅虎采取了類似的方法,也使用了 Apache Storm,Apache Hadoop 和 Druid2。
Netflix Suro 項目是 Netflix 數據管道的主干,該管道有獨立的數據處理路徑,但不嚴格遵循 lambda 體系結構,因為這些路徑可能用于不同的目的,不一定提供相同類型的視圖(views)。
使用 Apache Calcite 來橋接離線和近線計算。
上述就是小編為大家分享的大數據中如何分析Lambda架構了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





