溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“什么是DPDK”,在日常操作中,相信很多人在什么是DPDK問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”什么是DPDK”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
從我們用戶的使用就可以感受到網速一直在提升,而網絡技術的發展也從1GE/10GE/25GE/40GE/100GE的演變,從中可以得出單機的網絡IO能力必須跟上時代的發展。
1. 傳統的電信領域
IP層及以下,例如路由器、交換機、防火墻、基站等設備都是采用硬件解決方案。基于專用網絡處理器(NP),有基于FPGA,更有基于ASIC的。但是基于硬件的劣勢非常明顯,發生Bug不易修復,不易調試維護,并且網絡技術一直在發展,例如2G/3G/4G/5G等移動技術的革新,這些屬于業務的邏輯基于硬件實現太痛苦,不能快速迭代。傳統領域面臨的挑戰是急需一套軟件架構的高性能網絡IO開發框架。
2. 云的發展
私有云的出現通過網絡功能虛擬化(NFV)共享硬件成為趨勢,NFV的定義是通過標準的服務器、標準交換機實現各種傳統的或新的網絡功能。急需一套基于常用系統和標準服務器的高性能網絡IO開發框架。
3. 單機性能的飆升
網卡從1G到100G的發展,CPU從單核到多核到多CPU的發展,服務器的單機能力通過橫行擴展達到新的高點。但是軟件開發卻無法跟上節奏,單機處理能力沒能和硬件門當戶對,如何開發出與時并進高吞吐量的服務,單機百萬千萬并發能力。即使有業務對QPS要求不高,主要是CPU密集型,但是現在大數據分析、人工智能等應用都需要在分布式服務器之間傳輸大量數據完成作業。這點應該是我們互聯網后臺開發最應關注,也最關聯的。
想了解更多的小伙伴歡迎進群973961276來一起交流學習,更有海量學習資料跟大廠面試經驗分享。
在數年前曾經寫過《網卡工作原理及高并發下的調優》一文,描述了Linux的收發報文流程。根據經驗,在C1(8核)上跑應用每1W包處理需要消耗1%軟中斷CPU,這意味著單機的上限是100萬PPS(Packet Per Second)。從TGW(Netfilter版)的性能100萬PPS,AliLVS優化了也只到150萬PPS,并且他們使用的服務器的配置還是比較好的。假設,我們要跑滿10GE網卡,每個包64字節,這就需要2000萬PPS(注:以太網萬兆網卡速度上限是1488萬PPS,因為最小幀大小為84B《Bandwidth, Packets Per Second, and Other Network Performance Metrics》),100G是2億PPS,即每個包的處理耗時不能超過50納秒。而一次Cache Miss,不管是TLB、數據Cache、指令Cache發生Miss,回內存讀取大約65納秒,NUMA體系下跨Node通訊大約40納秒。所以,即使不加上業務邏輯,即使純收發包都如此艱難。我們要控制Cache的命中率,我們要了解計算機體系結構,不能發生跨Node通訊。
從這些數據,我希望可以直接感受一下這里的挑戰有多大,理想和現實,我們需要從中平衡。問題都有這些
1.傳統的收發報文方式都必須采用硬中斷來做通訊,每次硬中斷大約消耗100微秒,這還不算因為終止上下文所帶來的Cache Miss。
2.數據必須從內核態用戶態之間切換拷貝帶來大量CPU消耗,全局鎖競爭。
3.收發包都有系統調用的開銷。
4.內核工作在多核上,為可全局一致,即使采用Lock Free,也避免不了鎖總線、內存屏障帶來的性能損耗。
5.從網卡到業務進程,經過的路徑太長,有些其實未必要的,例如netfilter框架,這些都帶來一定的消耗,而且容易Cache Miss。
從前面的分析可以得知IO實現的方式、內核的瓶頸,以及數據流過內核存在不可控因素,這些都是在內核中實現,內核是導致瓶頸的原因所在,要解決問題需要繞過內核。所以主流解決方案都是旁路網卡IO,繞過內核直接在用戶態收發包來解決內核的瓶頸。
Linux社區也提供了旁路機制Netmap,官方數據10G網卡1400萬PPS,但是Netmap沒廣泛使用。其原因有幾個:
1.Netmap需要驅動的支持,即需要網卡廠商認可這個方案。
2.Netmap仍然依賴中斷通知機制,沒完全解決瓶頸。
3.Netmap更像是幾個系統調用,實現用戶態直接收發包,功能太過原始,沒形成依賴的網絡開發框架,社區不完善。
那么,我們來看看發展了十幾年的DPDK,從Intel主導開發,到華為、思科、AWS等大廠商的加入,核心玩家都在該圈子里,擁有完善的社區,生態形成閉環。早期,主要是傳統電信領域3層以下的應用,如華為、中國電信、中國移動都是其早期使用者,交換機、路由器、網關是主要應用場景。但是,隨著上層業務的需求以及DPDK的完善,在更高的應用也在逐步出現。
DPDK旁路原理:
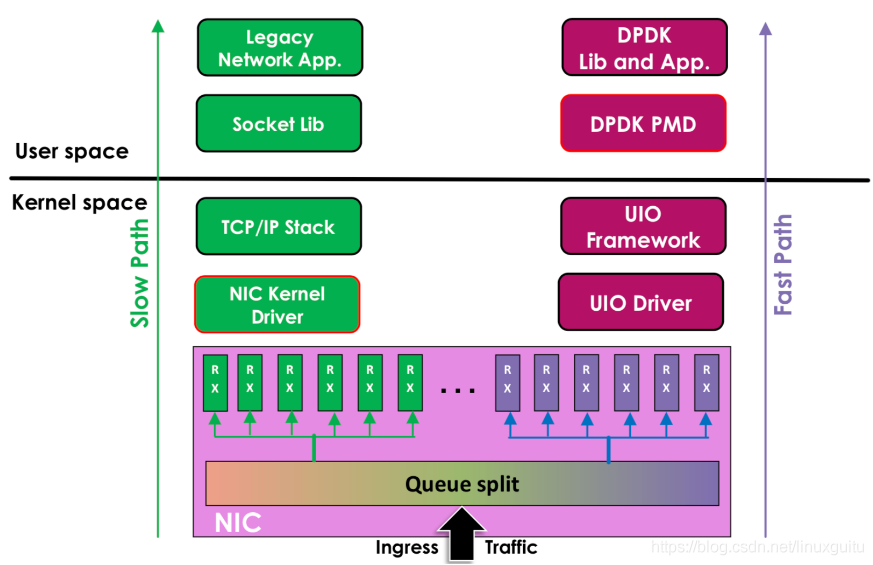
圖片引自Jingjing Wu的文檔《Flow Bifurcation on Intel? Ethernet Controller X710/XL710》
左邊是原來的方式數據從 網卡 -> 驅動 -> 協議棧 -> Socket接口 -> 業務
右邊是DPDK的方式,基于UIO(Userspace I/O)旁路數據。數據從 網卡 -> DPDK輪詢模式-> DPDK基礎庫 -> 業務
用戶態的好處是易用開發和維護,靈活性好。并且Crash也不影響內核運行,魯棒性強。
DPDK支持的CPU體系架構:x86、ARM、PowerPC(PPC)
DPDK支持的網卡列表:https://core.dpdk.org/supported/,我們主流使用Intel 82599(光口)、Intel x540(電口)
為了讓驅動運行在用戶態,Linux提供UIO機制。使用UIO可以通過read感知中斷,通過mmap實現和網卡的通訊。
UIO原理:
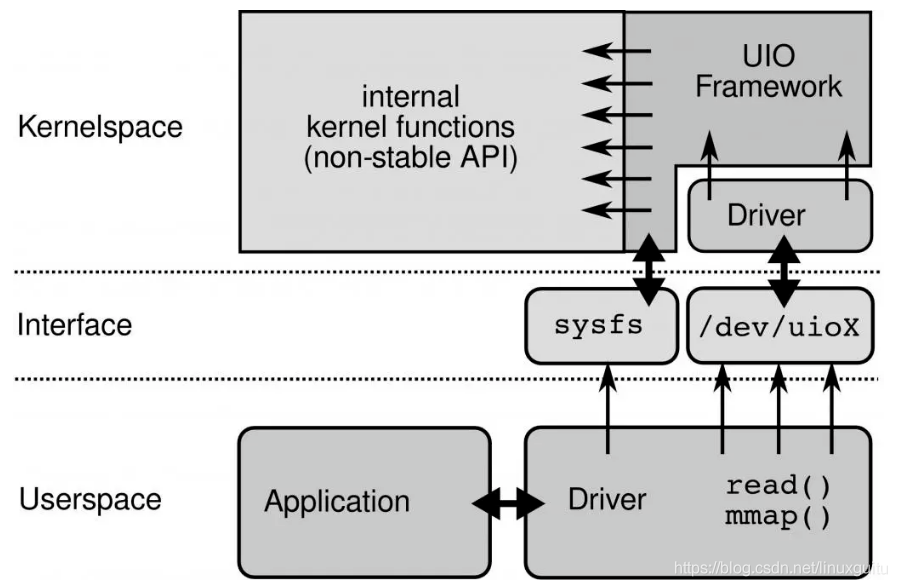
要開發用戶態驅動有幾個步驟:
1.開發運行在內核的UIO模塊,因為硬中斷只能在內核處理
2.通過/dev/uioX讀取中斷
3.通過mmap和外設共享內存
DPDK的UIO驅動屏蔽了硬件發出中斷,然后在用戶態采用主動輪詢的方式,這種模式被稱為PMD(Poll Mode Driver)。
UIO旁路了內核,主動輪詢去掉硬中斷,DPDK從而可以在用戶態做收發包處理。帶來Zero Copy、無系統調用的好處,同步處理減少上下文切換帶來的Cache Miss。
運行在PMD的Core會處于用戶態CPU100%的狀態
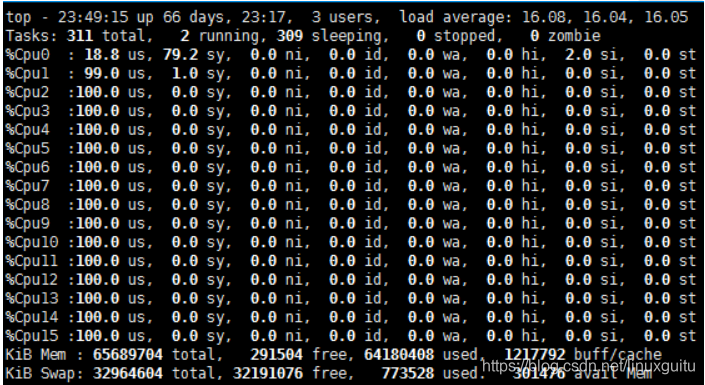
網絡空閑時CPU長期空轉,會帶來能耗問題。所以,DPDK推出Interrupt DPDK模式。
Interrupt DPDK:
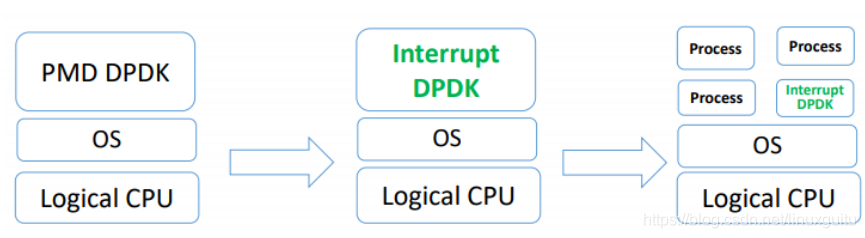
圖片引自David Su/Yunhong Jiang/Wei Wang的文檔《Towards Low Latency Interrupt Mode DPDK》
它的原理和NAPI很像,就是沒包可處理時進入睡眠,改為中斷通知。并且可以和其他進程共享同個CPU Core,但是DPDK進程會有更高調度優先級。
六、DPDK的高性能代碼實現
1. 采用HugePage減少TLB Miss
默認下Linux采用4KB為一頁,頁越小內存越大,頁表的開銷越大,頁表的內存占用也越大。CPU有TLB(Translation Lookaside Buffer)成本高所以一般就只能存放幾百到上千個頁表項。如果進程要使用64G內存,則64G/4KB=16000000(一千六百萬)頁,每頁在頁表項中占用16000000 * 4B=62MB。如果用HugePage采用2MB作為一頁,只需64G/2MB=2000,數量不在同個級別。
而DPDK采用HugePage,在x86-64下支持2MB、1GB的頁大小,幾何級的降低了頁表項的大小,從而減少TLB-Miss。并提供了內存池(Mempool)、MBuf、無鎖環(Ring)、Bitmap等基礎庫。根據我們的實踐,在數據平面(Data Plane)頻繁的內存分配釋放,必須使用內存池,不能直接使用rte_malloc,DPDK的內存分配實現非常簡陋,不如ptmalloc。
2. SNA(Shared-nothing Architecture)
軟件架構去中心化,盡量避免全局共享,帶來全局競爭,失去橫向擴展的能力。NUMA體系下不跨Node遠程使用內存。
3. SIMD(Single Instruction Multiple Data)
從最早的mmx/sse到最新的avx2,SIMD的能力一直在增強。DPDK采用批量同時處理多個包,再用向量編程,一個周期內對所有包進行處理。比如,memcpy就使用SIMD來提高速度。
SIMD在游戲后臺比較常見,但是其他業務如果有類似批量處理的場景,要提高性能,也可看看能否滿足。
4. 不使用慢速API
這里需要重新定義一下慢速API,比如說gettimeofday,雖然在64位下通過vDSO已經不需要陷入內核態,只是一個純內存訪問,每秒也能達到幾千萬的級別。但是,不要忘記了我們在10GE下,每秒的處理能力就要達到幾千萬。所以即使是gettimeofday也屬于慢速API。DPDK提供Cycles接口,例如rte_get_tsc_cycles接口,基于HPET或TSC實現。
在x86-64下使用RDTSC指令,直接從寄存器讀取,需要輸入2個參數,比較常見的實現:
static inline uint64_t
rte_rdtsc(void)
{
uint32_t lo, hi;
__asm__ __volatile__ (
"rdtsc" : "=a"(lo), "=d"(hi)
);
return ((unsigned long long)lo) | (((unsigned long long)hi) << 32);
}這么寫邏輯沒錯,但是還不夠極致,還涉及到2次位運算才能得到結果,我們看看DPDK是怎么實現:
static inline uint64_t
rte_rdtsc(void)
{
union {
uint64_t tsc_64;
struct {
uint32_t lo_32;
uint32_t hi_32;
};
} tsc;
asm volatile("rdtsc" :
"=a" (tsc.lo_32),
"=d" (tsc.hi_32));
return tsc.tsc_64;
}巧妙的利用C的union共享內存,直接賦值,減少了不必要的運算。但是使用tsc有些問題需要面對和解決
CPU親和性,解決多核跳動不精確的問題
內存屏障,解決亂序執行不精確的問題
禁止降頻和禁止Intel Turbo Boost,固定CPU頻率,解決頻率變化帶來的失準問題
5. 編譯執行優化
分支預測
現代CPU通過pipeline、superscalar提高并行處理能力,為了進一步發揮并行能力會做分支預測,提升CPU的并行能力。遇到分支時判斷可能進入哪個分支,提前處理該分支的代碼,預先做指令讀取編碼讀取寄存器等,預測失敗則預處理全部丟棄。我們開發業務有時候會非常清楚這個分支是true還是false,那就可以通過人工干預生成更緊湊的代碼提示CPU分支預測成功率。
#pragma once #if !__GLIBC_PREREQ(2, 3) # if !define __builtin_expect # define __builtin_expect(x, expected_value) (x) # endif #endif #if !defined(likely) #define likely(x) (__builtin_expect(!!(x), 1)) #endif #if !defined(unlikely) #define unlikely(x) (__builtin_expect(!!(x), 0)) #endif
CPU Cache預取
Cache Miss的代價非常高,回內存讀需要65納秒,可以將即將訪問的數據主動推送的CPU Cache進行優化。比較典型的場景是鏈表的遍歷,鏈表的下一節點都是隨機內存地址,所以CPU肯定是無法自動預加載的。但是我們在處理本節點時,可以通過CPU指令將下一個節點推送到Cache里。
API文檔:https://doc.dpdk.org/api/rte__prefetch_8h.html
static inline void rte_prefetch0(const volatile void *p)
{
asm volatile ("prefetcht0 %[p]" : : [p] "m" (*(const volatile char *)p));
}#if !defined(prefetch) #define prefetch(x) __builtin_prefetch(x) #endif
…等等
內存對齊
內存對齊有2個好處:
l 避免結構體成員跨Cache Line,需2次讀取才能合并到寄存器中,降低性能。結構體成員需從大到小排序和以及強制對齊。參考《Data alignment: Straighten up and fly right》
#define __rte_packed __attribute__((__packed__))
l 多線程場景下寫產生False sharing,造成Cache Miss,結構體按Cache Line對齊
#ifndef CACHE_LINE_SIZE #define CACHE_LINE_SIZE 64 #endif #ifndef aligined #define aligined(a) __attribute__((__aligned__(a))) #endif
常量優化
常量相關的運算的編譯階段完成。比如C++11引入了constexp,比如可以使用GCC的__builtin_constant_p來判斷值是否常量,然后對常量進行編譯時得出結果。舉例網絡序主機序轉換
#define rte_bswap32(x) ((uint32_t)(__builtin_constant_p(x) ? \ rte_constant_bswap32(x) : \ rte_arch_bswap32(x)))
其中rte_constant_bswap32的實現
#define RTE_STATIC_BSWAP32(v) \ ((((uint32_t)(v) & UINT32_C(0x000000ff)) << 24) | \ (((uint32_t)(v) & UINT32_C(0x0000ff00)) << 8) | \ (((uint32_t)(v) & UINT32_C(0x00ff0000)) >> 8) | \ (((uint32_t)(v) & UINT32_C(0xff000000)) >> 24))
5)使用CPU指令
現代CPU提供很多指令可直接完成常見功能,比如大小端轉換,x86有bswap指令直接支持了。
static inline uint64_t rte_arch_bswap64(uint64_t _x)
{
register uint64_t x = _x;
asm volatile ("bswap %[x]"
: [x] "+r" (x)
);
return x;
}這個實現,也是GLIBC的實現,先常量優化、CPU指令優化、最后才用裸代碼實現。畢竟都是頂端程序員,對語言、編譯器,對實現的追求不一樣,所以造輪子前一定要先了解好輪子。
Google開源的cpu_features可以獲取當前CPU支持什么特性,從而對特定CPU進行執行優化。高性能編程永無止境,對硬件、內核、編譯器、開發語言的理解要深入且與時俱進。
七、DPDK生態
對我們互聯網后臺開發來說DPDK框架本身提供的能力還是比較裸的,比如要使用DPDK就必須實現ARP、IP層這些基礎功能,有一定上手難度。如果要更高層的業務使用,還需要用戶態的傳輸協議支持。不建議直接使用DPDK。
目前生態完善,社區強大(一線大廠支持)的應用層開發項目是FD.io(The Fast Data Project),有思科開源支持的VPP,比較完善的協議支持,ARP、VLAN、Multipath、IPv4/v6、MPLS等。用戶態傳輸協議UDP/TCP有TLDK。從項目定位到社區支持力度算比較靠譜的框架。
騰訊云開源的F-Stack也值得關注一下,開發更簡單,直接提供了POSIX接口。
Seastar也很強大和靈活,內核態和DPDK都隨意切換,也有自己的傳輸協議Seastar Native TCP/IP Stack支持,但是目前還未看到有大型項目在使用Seastar,可能需要填的坑比較多。
我們GBN Gateway項目需要支持L3/IP層接入做Wan網關,單機20GE,基于DPDK開發。
到此,關于“什么是DPDK”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





