溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“數據庫中經典的同期群舉例分析”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“數據庫中經典的同期群舉例分析”吧!
同期群分析是數據分析中一個hin經典的思維,核心是將用戶按初始行為的發生時間,劃分為不同的群組,進而分析相似群組的行為如何隨時間變化而變化。一般是通過像這樣的留存表來實現: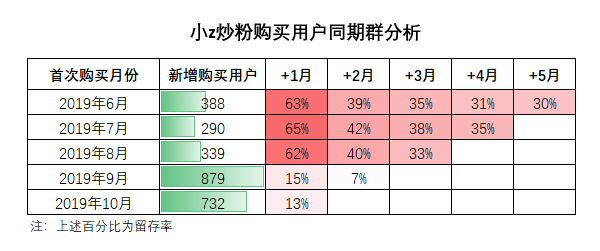
每一行,代表當月新增客戶,在接下來幾個月的留存情況。
通過橫向對比,能夠對客戶留存和生命周期有初步的認識。基于縱向觀察,可以發現不同期客戶,留存情況的差異,以反推該期引入的客戶是否精準。
這個表看起來簡單明晰,也有一些成熟的工具能夠實現,但是,真要基于訂單數據用Python來實現,還是要絞一番腦汁的。
首先,導入訂單數據,順帶看一看源數據長什么樣子: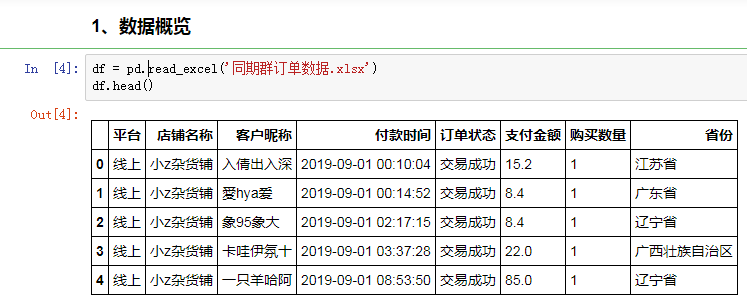
后續分析會用到的關鍵字段有客戶昵稱,付款時間,訂單狀態和支付金額。
再查看數據量和缺失情況: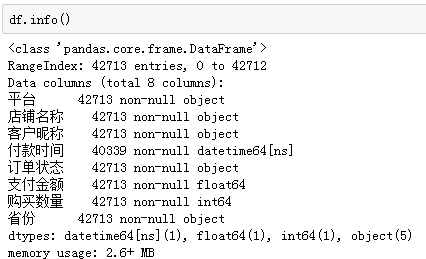
訂單共計42713行,除付款時間外,其他都是完整的(不含缺失值)。格式整體規整,付款時間為datetime格式,購買金額和數量則是數值型。
清洗的重點在于搞清楚為什么會有那么多付款時間是缺失的。我們先篩選出付款時間為空值的行,一探究竟: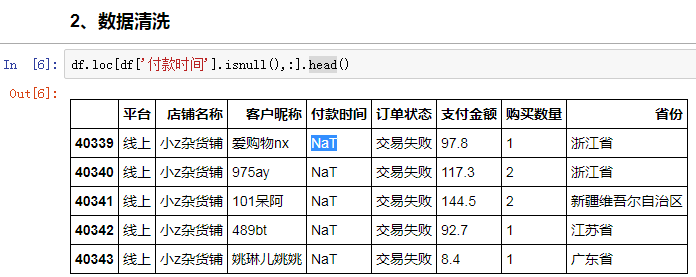
貌似,缺失付款時間的數據,訂單狀態主要是交易失敗。這里做一個初步推斷,之所以缺失付款時間,是因為沒有產生實際交易。
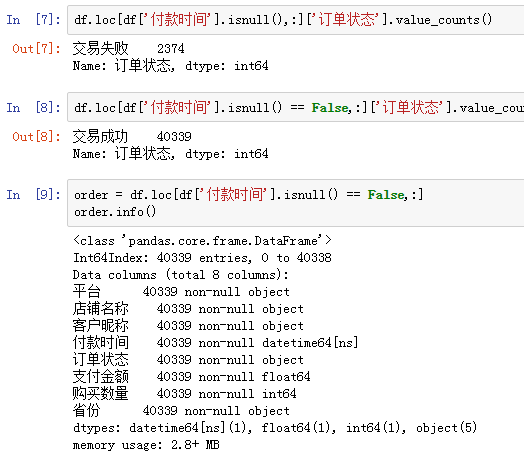
果然,缺失付款時間的訂單都是交易失敗狀態,而完整的數據則是交易成功。接下來,只需要篩選出交易成功的訂單就好,40339行數據,就是同期群分析的主戰場。
再讓最開始的留存表刷一下存在感:
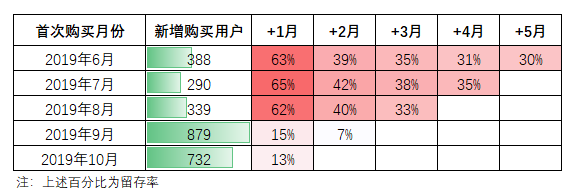
直接思考怎么樣一次性生成這張表,著實費頭發。更合理的方式是用搭積木的思維來拆解這張表。這張表的每一行,代表一個同期群,而他們的本質邏輯是一樣的。
首先計算出當月新增的客戶數,并記錄客戶昵稱。
然后拿這部分客戶,分別去和后面每個月購買的客戶做匹配,并統計有多少客戶出現復購(留存)
只要我們計算出每個月的新增客戶和對應留存情況,把這些數據拼接在一起,就得到了夢寐以求的同期群留存表。
循著上一步的思路,問題變得簡單起來,實現一個月的計算邏輯,其他月份套用即可。給同期群留存表添加一列標記數據歸屬與哪個年月。

我們以2019年10月的數據為樣板,實現單行的同期群分析。
顯而易見,2019年10月份一共有7336位客戶,購買了8096筆訂單。
接下來,我們要計算的是每個月的新增客戶數,這個新增,是需要和之前的月份遍歷匹配來驗證的,2019年10月之前的客戶就是2019年9月的數據: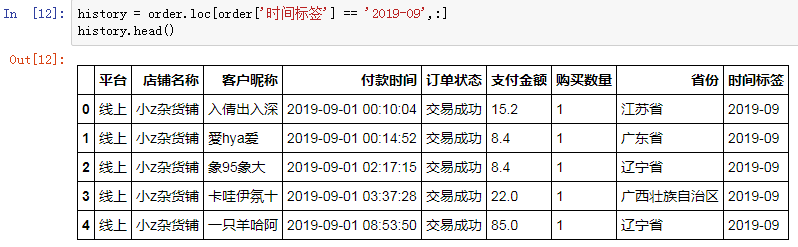
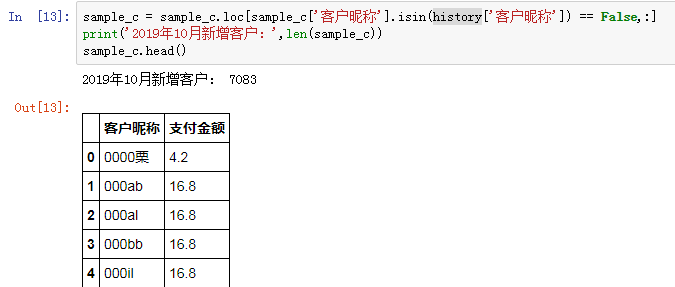
和歷史數據做匹配,驗證并篩選出2019年10月新增的客戶數:
然后,和10月之后每個月的客戶昵稱進行匹配,計算出每個月的留存情況,把最開始的當月新增客戶加入到列表:
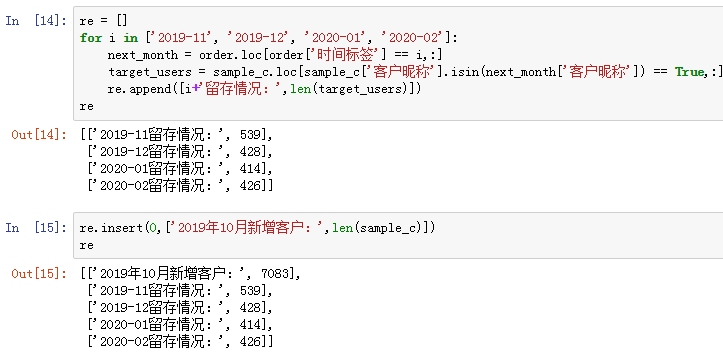
2019年10月新增客戶7083位,次月(11月)留存539人,隨后有所降低,而到了2020年2月留存回購客戶數較上月有小幅上升。
#引入時間標簽month_lst = order['時間標簽'].unique()final = pd.DataFrame()for i in range(len(month_lst) - 1):#構造和月份一樣長的列表,方便后續格式統一count = [0] * len(month_lst)#篩選出當月訂單,并按客戶昵稱分組target_month = order.loc[order['時間標簽'] == month_lst[i],:]target_users = target_month.groupby('客戶昵稱')['支付金額'].sum().reset_index()#如果是第一個月份,則跳過(因為不需要和歷史數據驗證是否為新增客戶)if i == 0:new_target_users = target_month.groupby('客戶昵稱')['支付金額'].sum().reset_index()else:#如果不是,找到之前的歷史訂單history = order.loc[order['時間標簽'].isin(month_lst[:i]),:]#篩選出未在歷史訂單出現過的新增客戶new_target_users = target_users.loc[target_users['客戶昵稱'].isin(history['客戶昵稱']) == False,:]#當月新增客戶數放在第一個值中count[0] = len(new_target_users)#以月為單位,循環遍歷,計算留存情況for j,ct in zip(range(i + 1,len(month_lst)),range(1,len(month_lst))):#下一個月的訂單next_month = order.loc[order['時間標簽'] == month_lst[j],:]next_users = next_month.groupby('客戶昵稱')['支付金額'].sum().reset_index()#計算在該月仍然留存的客戶數量isin = new_target_users['客戶昵稱'].isin(next_users['客戶昵稱']).sum()count[ct] = isin#格式轉置result = pd.DataFrame({
month_lst[i]:count}).T#合并final = pd.concat([final,result])final.columns = ['當月新增','+1月','+2月','+3月','+4月','+5月']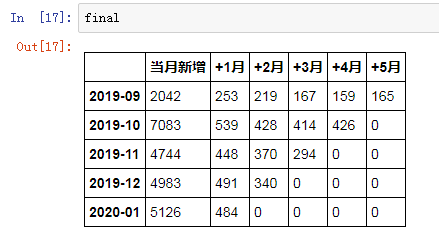
不過,真實數據是留存率形式體現,再稍做加工即可:
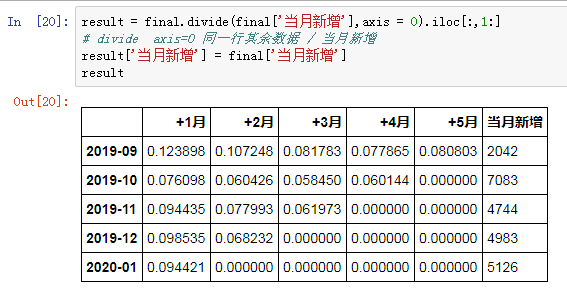
終于,大功告成!實現了我們所希望的同期群分析表。簡單掃兩眼,可以發現:
橫向觀察,次月流失嚴重,表現最好的月份次月留存也只有12%,隨后平穩降低,穩定在6%左右。
縱向對比,2019年當月新增客戶最少,僅有2042位,但人群相對精準,留存率表現優于其他月份。
感謝各位的閱讀,以上就是“數據庫中經典的同期群舉例分析”的內容了,經過本文的學習后,相信大家對數據庫中經典的同期群舉例分析這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





