溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Java哈希表怎么理解”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Java哈希表怎么理解”吧!
Java 中對象的 hashCode 根據對象的地址來生成的,唯一不重復。為什么要重寫hashcode跟equals
Hash表也稱散列表,也有直接譯作哈希表,Hash表是一種特殊的數據結構,它同數組、鏈表以及二叉排序樹等相比較有很明顯的區別,它能夠快速定位到想要查找的記錄,而不是與表中存在的記錄的關鍵字進行比較來進行查找。這個源于Hash表設計的特殊性,它采用了函數映射的思想將記錄的存儲位置與記錄的關鍵字關聯起來,從而能夠很快速地進行查找。
數組是方便查詢不方便刪除,鏈表是方便刪除不方便查詢。
1.Hash表的設計思想
對于一般的線性表,比如鏈表,如果要存儲聯系人信息:
張三 13980593357 李四 15828662334 王五 13409821234 張帥 13890583472
那么可能會設計一個結構體包含姓名,手機號碼這些信息,然后把4個聯系人的信息存到一張鏈表中。當要查找”李四 15828662334“這條記錄是否在這張鏈表中或者想要得到李四的手機號碼時,可能會從鏈表的頭結點開始遍歷,依次將每個結點中的姓名同”李四“進行比較,直到查找成功或者失敗為止,這種做法的時間復雜度為O(n)。即使采用二叉排序樹進行存儲,也最多為O(logn)。假設能夠通過”李四“這個信息直接獲取到該記錄在表中的存儲位置,就能省掉中間關鍵字比較的這個環節,復雜度直接降到O(1)。Hash表就能夠達到這樣的效果。
Hash表采用一個映射函數 f : key —> address 將關鍵字映射到該記錄在表中的存儲位置,從而在想要查找該記錄時,可以直接根據關鍵字和映射關系計算出該記錄在表中的存儲位置,通常情況下,這種映射關系稱作為Hash函數,而通過Hash函數和關鍵字計算出來的存儲位置(注意這里的存儲位置只是表中的存儲位置,并不是實際的物理地址)稱作為Hash地址。比如上述例子中,假如聯系人信息采用Hash表存儲,則當想要找到“李四”的信息時,直接根據“李四”和Hash函數計算出Hash地址即可。下面討論一下Hash表設計中的幾個關鍵問題。
Hash函數設計的好壞直接影響到對Hash表的操作效率。下面舉例說明:
假如對上述的聯系人信息進行存儲時,采用的Hash函數為:姓名的每個字的拼音開頭大寫字母的ASCII碼之和。
因此address(張三)=ASCII(Z)+ASCII(S)=90+83=173;
address(李四)=ASCII(L)+ASCII(S)=76+83=159;
address(王五)=ASCII(W)+ASCII(W)=87+87=174;
address(張帥)=ASCII(Z)+ASCII(S)=90+83=173;
假如只有這4個聯系人信息需要進行存儲,這個Hash函數設計的很糟糕。首先,它浪費了大量的存儲空間,假如采用char型數組存儲聯系人信息的話,則至少需要開辟174*12字節的空間,空間利用率只有4/174,不到5%;另外,根據Hash函數計算結果之后,address(張三)和address(李四)具有相同的地址,這種現象稱作沖突,對于174個存儲空間中只需要存儲4條記錄就發生了沖突,這樣的Hash函數設計是很不合理的。所以在構造Hash函數時應盡量考慮關鍵字的分布特點來設計函數使得Hash地址隨機均勻地分布在整個地址空間當中。通常有以下幾種構造Hash函數的方法:
1)直接定址法
取關鍵字或者關鍵字的某個線性函數為Hash地址,即address(key)=a*key+b;如知道學生的學號從2000開始,最大為4000,則可以將address(key)=key-2000作為Hash地址。
2)平方取中法
對關鍵字進行平方運算,然后取結果的中間幾位作為Hash地址。假如有以下關鍵字序列{421,423,436},平方之后的結果為{177241,178929,190096},那么可以取{72,89,00}作為Hash地址。
3)折疊法
將關鍵字拆分成幾部分,然后將這幾部分組合在一起,以特定的方式進行轉化形成Hash地址。假如知道圖書的ISBN號為8903-241-23,可以將address(key)=89+03+24+12+3作為Hash地址。
4)除留取余法
如果知道Hash表的最大長度為m,可以取不大于m的最大質數p,然后對關鍵字進行取余運算,address(key)=key%p。
在這里p的選取非常關鍵,p選擇的好的話,能夠最大程度地減少沖突,p一般取不大于m的最大質數。
Hash表大小的確定也非常關鍵,如果Hash表的空間遠遠大于最后實際存儲的記錄個數,則造成了很大的空間浪費,如果選取小了的話,則容易造成沖突。在實際情況中,一般需要根據最終記錄存儲個數和關鍵字的分布特點來確定Hash表的大小。還有一種情況時可能事先不知道最終需要存儲的記錄個數,則需要動態維護Hash表的容量,此時可能需要重新計算Hash地址。
在上述例子中,發生了沖突現象,因此需要辦法來解決,否則記錄無法進行正確的存儲。通常情況下有2種解決辦法:
1)開放定址法
即當一個關鍵字和另一個關鍵字發生沖突時,使用某種探測技術在Hash表中形成一個探測序列,然后沿著這個探測序列依次查找下去,當碰到一個空的單元時,則插入其中。比較常用的探測方法有線性探測法,比如有一組關鍵字{12,13,25,23,38,34,6,84,91},Hash表長為14,Hash函數為address(key)=key%11,當插入12,13,25時可以直接插入,而當插入23時,地址1被占用了,因此沿著地址1依次往下探測(探測步長可以根據情況而定),直到探測到地址4,發現為空,則將23插入其中。
2)鏈地址法
采用數組和鏈表相結合的辦法,將Hash地址相同的記錄存儲在一張線性表中,而每張表的表頭的序號即為計算得到的Hash地址。如上述例子中,采用鏈地址法形成的Hash表存儲表示為:
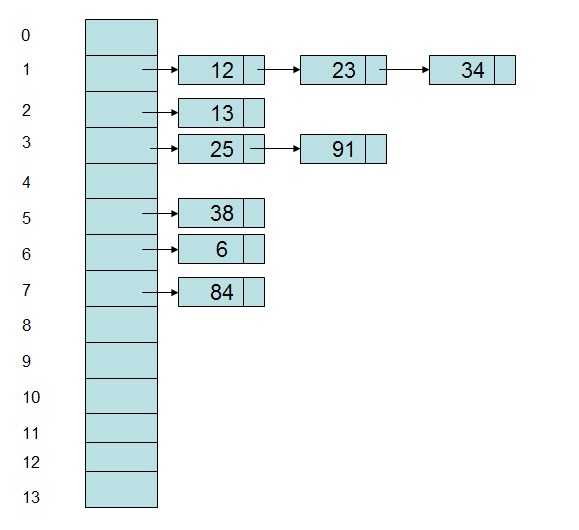
雖然能夠采用一些辦法去減少沖突,但是沖突是無法完全避免的。因此需要根據實際情況選取解決沖突的辦法。
Hash表的平均查找長度包括查找成功時的平均查找長度和查找失敗時的平均查找長度。
查找成功時的平均查找長度:表中每個元素查找成功時的比較次數之和/表中元素個數;
查找不成功時的平均查找長度:相當于在表中查找元素不成功時的平均比較次數,可以理解為向表中插入某個元素,該元素在每個位置都有可能,然后計算出在每個位置能夠插入時需要比較的次數,再除以表長即為查找不成功時的平均查找長度。
下面舉個例子:
有一組關鍵字{23,12,14,2,3,5},表長為14,Hash函數為key%11,解決沖突方式為開放定值法,則關鍵字在表中的存儲如下:
| 地址 | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 | 12 | 13 |
| 關鍵字 | 23 | 12 | 14 | 2 | 3 | 5 | ||||||||
| 比較次數 | 1 | 2 | 1 | 3 | 3 | 2 | ||||||||
| 備注 | 比較1次 | 比較1次移動1次 | 比較1次 | 比較1次移動2次 | 比較1次移動2次 | 比較1次移動1次 |
查找成功時的平均查找長度為 :(1+2+1+3+3+2)/6=11/6;
查找失敗時的平均查找長度為(1+7+6+5+4+3+2+1+1+1+1+1+1+1)/14=38/14;
查找失敗的長度重點理解下是需要比較的次數(為1 時說明就調用了hash函數一次,7說明計算了1次還可能會出現沖突6次)。就可以退出上述值了。
這里有一個概念
裝填因子 = 表中的記錄數 / 哈希表的長度,
如果裝填因子越小,表明表中還有很多的空單元,則發生沖突的可能性越小;
而裝填因子越大,則發生沖突的可能性就越大,在查找時所耗費的時間就越多。
因此,Hash表的平均查找長度和裝填因子有關。有相關文獻證明當裝填因子在0.5左右的時候,Hash的性能能夠達到最優。因此,一般情況下,裝填因子取經驗值0.5。
Hash表存在的優點顯而易見,能夠在常數級的時間復雜度上進行查找,并且插入數據和刪除數據比較容易。但是它也有某些缺點,比如不支持排序,一般比用線性表存儲需要更多的空間,并且記錄的關鍵字不能重復。
/*Hash表,采用數組實現/
#include<stdio.h>
#define DataType int
#define M 30
typedef struct HashNode
{
DataType data; //存儲值
int isNull; //標志該位置是否已被填充
}HashTable;
HashTable hashTable[M];
void initHashTable() //對hash表進行初始化
{
int i;
for(i = 0; i<M; i++)
{
hashTable[i].isNull = 1; //初始狀態為空
}
}
int getHashAddress(DataType key) //Hash函數
{
return key % 29; //Hash函數為 key%29
}
int insert(DataType key) //向hash表中插入元素
{
int address = getHashAddress(key);
if(hashTable[address].isNull == 1) //沒有發生沖突
{
hashTable[address].data = key;
hashTable[address].isNull = 0;
}
else //當發生沖突的時候
{
while(hashTable[address].isNull == 0 && address<M)
{
address++; //采用線性探測法,步長為1
}
if(address == M) //Hash表發生溢出
return -1;
hashTable[address].data = key;
hashTable[address].isNull = 0;
}
return 0;
}
int find(DataType key) //進行查找
{
int address = getHashAddress(key);
while( !(hashTable[address].isNull == 0 && hashTable[address].data == key && address<M))
{
address++;
}
if( address == M)
address = -1;
return address;
}
int main(int argc, char *argv[])
{
int key[]={123,456,7000,8,1,13,11,555,425,393,212,546,2,99,196};
int i;
initHashTable();
for(i = 0; i<15; i++)
{
insert(key[i]);
}
for(i = 0; i<15; i++)
{
int address;
address = find(key[i]);
printf("%d %d\n", key[i],address);
}
return 0;
}HashCode的存在主要是用于查找的快捷性,如Hashtable,HashMap等,HashCode經常用于確定對象的存儲地址(不是真實的物理地址!);
如果兩個對象相同(物理地址一樣), equals方法一定返回true,并且這兩個對象的HashCode一定相同;
兩個對象的HashCode相同,并不一定表示兩個對象就相同,即equals()不一定為true,只能說明這兩個對象在一個散列存儲結構中(因為可能存在沖突,采用了拉鏈法解決了沖突)。
如果對象的equals方法被重寫,那么對象的HashCode也盡量重寫。
Java中的集合有兩類,一類是List,再有一類是Set。前者集合內的元素是有序的,元素可以重復;后者元素無序,但元素不可重復。 equals方法可用于保證元素不重復,但如果每增加一個元素就檢查一次,若集合中現在已經有1000個元素,那么第1001個元素加入集合時,就要調用1000次equals方法。這顯然會大大降低效率。 于是,Java采用了哈希表的原理。
哈希算法也稱為散列算法,是將數據依特定算法直接指定到一個地址上。這樣一來,當集合要添加新的元素時,先調用這個元素的HashCode方法,就一下子能定位到它應該放置的物理位置上。
如果這個位置上沒有元素,它就可以直接存儲在這個位置上,不用再進行任何比較了;
如果這個位置上已經有元素了,就調用它的equals方法與新元素進行比較,相同的話就不存了;
不相同的話,也就是發生了Hash key相同導致沖突的情況,那么就在這個Hash key的地方產生一個鏈表,將所有產生相同HashCode的對象放到這個單鏈表上去,串在一起。這樣一來實際調用equals方法的次數就大大降低了,幾乎只需要一兩次。
從Object角度看,JVM每new一個Object,它都會將這個Object丟到一個Hash表中去,這樣的話,下次做Object的比較或者取這個對象的時候(讀取過程),它會根據對象的HashCode再從Hash表中取這個對象。這樣做的目的是提高取對象的效率。若HashCode相同再去調用equal。Java底層獲取hashCode的方法如下:
// 表示的是 JVM 根據某種策略 為這個Object對象分配的一個int類型的數值 public native int hashCode();
比如Integer類型獲得hashCode的方法如下:
public int hashCode() {
return value;
}String類型的hashCode獲得方法如下:
public int hashCode() {
int h = hash;
if (h == 0) {
int off = offset;
char val[] = value;
int len = count;
for (int i = 0; i < len; i++) {
h = 31*h + val[off++];
}
hash = h;
}
return h;
}HashCode是用于查找使用的,而equals是用于比較兩個對象是否相等的。
(1)例如內存中有這樣的位置 :
0 1 2 3 4 5 6 7
而我有個類,這個類有個字段叫ID,我要把這個類存放在以上8個位置之一,如果不用HashCode而任意存放,那么當查找時就需要到這八個位置里挨個去找,或者用二分法一類的算法。 但以上問題如果用HashCode就會使效率提高很多。 定義我們的HashCode為ID%8,比如我們的ID為9,9除8的余數為1,那么我們就把該類存在1這個位置,如果ID是13,求得的余數是5,那么我們就把該類放在5這個位置。依此類推。
(2)如果兩個類有相同的HashCode,例如9除以8和17除以8的余數都是1,也就是說,我們先通過 HashCode來判斷兩個類是否存放某個桶里,但這個桶里可能有很多類,那么我們就需要再通過equals在這個桶里找到我們要的類。
請看下面這個例子 :
public class HashTest {
private int i;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
public int hashCode() {
return i % 10;
}
public final static void main(String[] args) {
HashTest a = new HashTest();
HashTest b = new HashTest();
a.setI(1);
b.setI(1);
Set<HashTest> set = new HashSet<HashTest>();
set.add(a);
set.add(b);
System.out.println(a.hashCode() == b.hashCode());
System.out.println(a.equals(b));
System.out.println(set);
}
}
=====
true
false
[HashTest@1, HashTest@1]以上這個示例,我們只是重寫了HashCode方法,從上面的結果可以看出,雖然兩個對象的HashCode相等,但是實際上兩個對象并不是相等,因為我們沒有重寫equals方法,那么就會調用Object默認的equals方法,顯示這是兩個不同的對象。
這里我們將生成的對象放到了HashSet中,而HashSet中只能夠存放唯一的對象,也就是相同的(適用于equals方法來判斷是否放入)的對象只會存放一個,但是這里實際上是兩個對象ab都被放到了HashSet中,這樣HashSet就失去了他本身的意義了。
下面我們繼續重寫equals方法:
public class HashTest {
private int i;
public int getI() {
return i;
}
public void setI(int i) {
this.i = i;
}
public boolean equals(Object object) {
if (object == null) {
return false;
}
if (object == this) {
return true;
}
if (!(object instanceof HashTest)) {
return false;
}
HashTest other = (HashTest) object;
if (other.getI() == this.getI()) {
return true;
}
return false;
}
public int hashCode() {
return i % 10;
}
public final static void main(String[] args) {
HashTest a = new HashTest();
HashTest b = new HashTest();
a.setI(1);
b.setI(1);
Set<HashTest> set = new HashSet<HashTest>();
set.add(a);
set.add(b);
System.out.println(a.hashCode() == b.hashCode());
System.out.println(a.equals(b));
System.out.println(set);
}
}
=======
true
true
[HashTest@1]從結果我們可以看出,現在兩個對象就完全相等了,HashSet中也只存放了一份對象。
感謝各位的閱讀,以上就是“Java哈希表怎么理解”的內容了,經過本文的學習后,相信大家對Java哈希表怎么理解這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





