溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“MySQL是如何保證數據不丟的”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“MySQL是如何保證數據不丟的”吧!
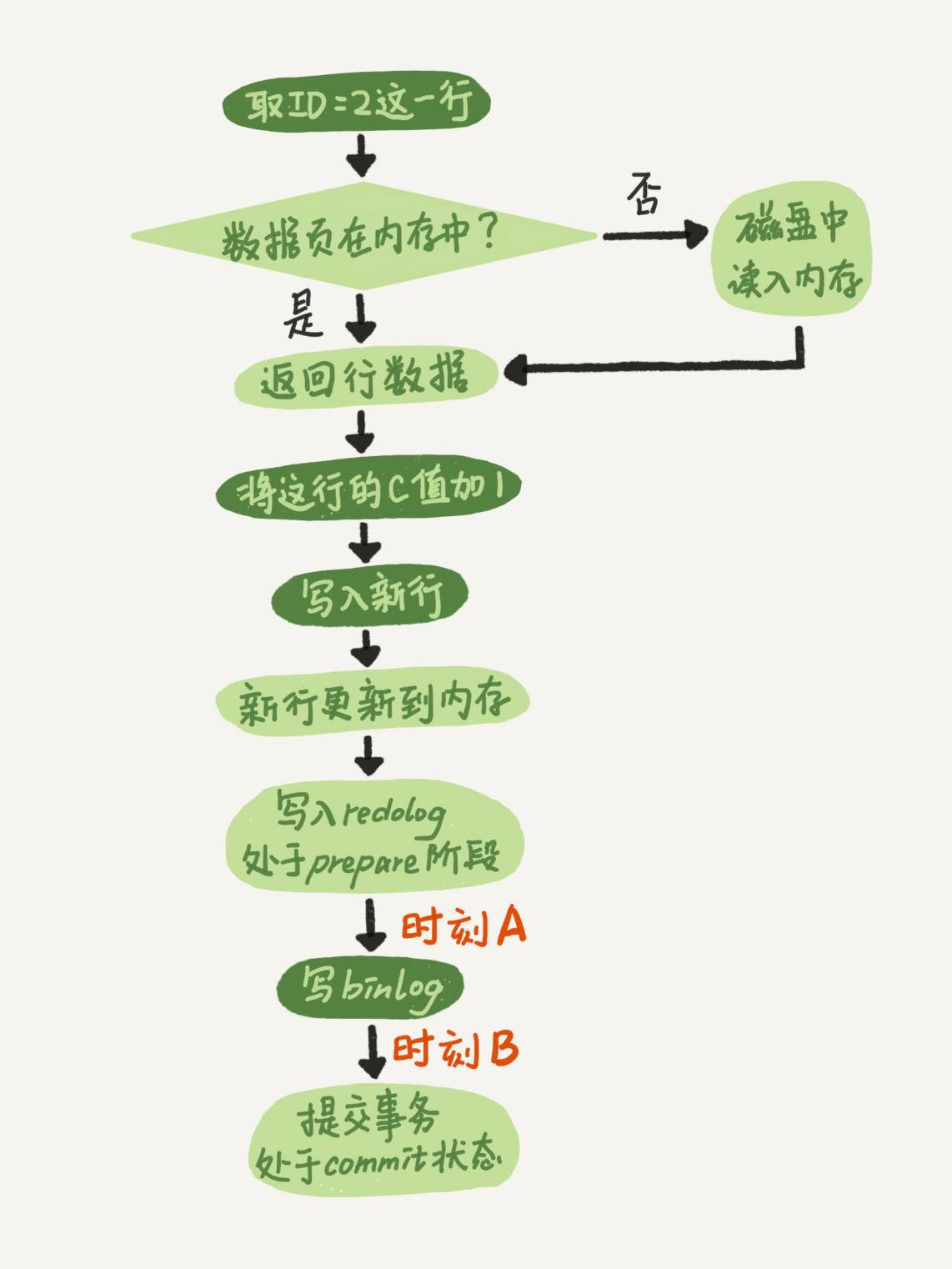
圖1 兩階段提交示意圖
這個圖不是一個update語句的執行流程嗎,怎么還會調用commit語句?原因是把兩個“commit”的概念混淆了:
平常說的commit語句,是指MySQL語法中,用于提交一個事務的命令。一般跟begin/start transaction 配對使用。
而我們圖中用到的這個commit步驟,指的是事務提交過程中的一個小步驟,也是最后一步。當這個步驟執行完成后,這個事務就提交完成了。
commit語句執行的時候,會包含commit 步驟。
而我們這個例子里面,沒有顯式地開啟事務,因此這個update語句自己就是一個事務,在執行完成后提交事務時,就會用到這個“commit步驟“。
接下來,我們就一起分析一下在兩階段提交的不同時刻,MySQL異常重啟會出現什么現象。
如果在圖中時刻A的地方,也就是寫入redo log 處于prepare階段之后、寫binlog之前,發生了崩潰(crash),由于此時binlog還沒寫,redo log也還沒提交,所以崩潰恢復的時候,這個事務會回滾。這時候,binlog還沒寫,所以也不會傳到備庫。到這里,大家都可以理解。
如果binlog寫完,redo log還沒commit前發生crash,那崩潰恢復的時候MySQL會怎么處理?
我們先來看一下崩潰恢復時的判斷規則。
如果redo log里面的事務是完整的,也就是已經有了commit標識,則直接提交;
如果redo log里面的事務只有完整的prepare,則判斷對應的事務binlog是否存在并完整:
a. 如果是,則提交事務;
b. 否則,回滾事務。
這里,時刻B發生crash對應的就是2(a)的情況,崩潰恢復過程中事務會被提交。
現在,我們繼續延展一下這個問題。
回答:一個事務的binlog是有完整格式的:
statement格式的binlog,最后會有COMMIT;
row格式的binlog,最后會有一個XID event。
另外,在MySQL 5.6.2版本以后,還引入了binlog-checksum參數,用來驗證binlog內容的正確性。對于binlog日志由于磁盤原因,可能會在日志中間出錯的情況,MySQL可以通過校驗checksum的結果來發現。所以,MySQL還是有辦法驗證事務binlog的完整性的。
回答:它們有一個共同的數據字段,叫XID。崩潰恢復的時候,會按順序掃描redo log:
如果碰到既有prepare、又有commit的redo log,就直接提交;
如果碰到只有parepare、而沒有commit的redo log,就拿著XID去binlog找對應的事務。
回答:其實,這個問題還是跟我們在反證法中說到的數據與備份的一致性有關。在時刻B,也就是binlog寫完以后MySQL發生崩潰,這時候binlog已經寫入了,之后就會被從庫(或者用這個binlog恢復出來的庫)使用。
所以,在主庫上也要提交這個事務。采用這個策略,主庫和備庫的數據就保證了一致性。
回答:其實,兩階段提交是經典的分布式系統問題,并不是MySQL獨有的。
如果必須要舉一個場景,來說明這么做的必要性的話,那就是事務的持久性問題。
對于InnoDB引擎來說,如果redo log提交完成了,事務就不能回滾(如果這還允許回滾,就可能覆蓋掉別的事務的更新)。而如果redo log直接提交,然后binlog寫入的時候失敗,InnoDB又回滾不了,數據和binlog日志又不一致了。
兩階段提交就是為了給所有人一個機會,當每個人都說“我ok”的時候,再一起提交。
回答:這位同學的意思是,只保留binlog,然后可以把提交流程改成這樣:… -> “數據更新到內存” -> “寫 binlog” -> “提交事務”,是不是也可以提供崩潰恢復的能力?
答案是不可以。
如果說歷史原因的話,那就是InnoDB并不是MySQL的原生存儲引擎。MySQL的原生引擎是MyISAM,設計之初就有沒有支持崩潰恢復。
InnoDB在作為MySQL的插件加入MySQL引擎家族之前,就已經是一個提供了崩潰恢復和事務支持的引擎了。
InnoDB接入了MySQL后,發現既然binlog沒有崩潰恢復的能力,那就用InnoDB原有的redo log好了。
而如果說實現上的原因的話,就有很多了。就按照問題中說的,只用binlog來實現崩潰恢復的流程,我畫了一張示意圖,這里就沒有redo log了。
圖2 只用binlog支持崩潰恢復
這樣的流程下,binlog還是不能支持崩潰恢復的。我說一個不支持的點吧:binlog沒有能力恢復“數據頁”。
如果在圖中標的位置,也就是binlog2寫完了,但是整個事務還沒有commit的時候,MySQL發生了crash。
重啟后,引擎內部事務2會回滾,然后應用binlog2可以補回來;但是對于事務1來說,系統已經認為提交完成了,不會再應用一次binlog1。
但是,InnoDB引擎使用的是WAL技術,執行事務的時候,寫完內存和日志,事務就算完成了。如果之后崩潰,要依賴于日志來恢復數據頁。
也就是說在圖中這個位置發生崩潰的話,事務1也是可能丟失了的,而且是數據頁級的丟失。此時,binlog里面并沒有記錄數據頁的更新細節,是補不回來的。
你如果要說,那我優化一下binlog的內容,讓它來記錄數據頁的更改可以嗎?但,這其實就是又做了一個redo log出來。
所以,至少現在的binlog能力,還不能支持崩潰恢復。
回答:如果只從崩潰恢復的角度來講是可以的。你可以把binlog關掉,這樣就沒有兩階段提交了,但系統依然是crash-safe的。
但是,如果你了解一下業界各個公司的使用場景的話,就會發現在正式的生產庫上,binlog都是開著的。因為binlog有著redo log無法替代的功能。
一個是歸檔。redo log是循環寫,寫到末尾是要回到開頭繼續寫的。這樣歷史日志沒法保留,redo log也就起不到歸檔的作用。
一個就是MySQL系統依賴于binlog。binlog作為MySQL一開始就有的功能,被用在了很多地方。其中,MySQL系統高可用的基礎,就是binlog復制。
還有很多公司有異構系統(比如一些數據分析系統),這些系統就靠消費MySQL的binlog來更新自己的數據。關掉binlog的話,這些下游系統就沒法輸入了。
總之,由于現在包括MySQL高可用在內的很多系統機制都依賴于binlog,所以“鳩占鵲巢”redo log還做不到。你看,發展生態是多么重要。
回答:redo log太小的話,會導致很快就被寫滿,然后不得不強行刷redo log,這樣WAL機制的能力就發揮不出來了。
所以,如果是現在常見的幾個TB的磁盤的話,就不要太小氣了,直接將redo log設置為4個文件、每個文件1GB吧。
回答:這個問題其實問得非常好。這里涉及到了,“redo log里面到底是什么”的問題。
實際上,redo log并沒有記錄數據頁的完整數據,所以它并沒有能力自己去更新磁盤數據頁,也就不存在“數據最終落盤,是由redo log更新過去”的情況。
如果是正常運行的實例的話,數據頁被修改以后,跟磁盤的數據頁不一致,稱為臟頁。最終數據落盤,就是把內存中的數據頁寫盤。這個過程,甚至與redo log毫無關系。
在崩潰恢復場景中,InnoDB如果判斷到一個數據頁可能在崩潰恢復的時候丟失了更新,就會將它讀到內存,然后讓redo log更新內存內容。更新完成后,內存頁變成臟頁,就回到了第一種情況的狀態。
在一個事務的更新過程中,日志是要寫多次的。比如下面這個事務:
begin; insert into t1 ... insert into t2 ... commit;
這個事務要往兩個表中插入記錄,插入數據的過程中,生成的日志都得先保存起來,但又不能在還沒commit的時候就直接寫到redo log文件里。
所以,redo log buffer就是一塊內存,用來先存redo日志的。也就是說,在執行第一個insert的時候,數據的內存被修改了,redo log buffer也寫入了日志。
但是,真正把日志寫到redo log文件(文件名是 ib_logfile+數字),是在執行commit語句的時候做的。
(這里說的是事務執行過程中不會“主動去刷盤”,以減少不必要的IO消耗。但是可能會出現“被動寫入磁盤”,比如內存不夠、其他事務提交等情況)。
單獨執行一個更新語句的時候,InnoDB會自己啟動一個事務,在語句執行完成的時候提交。過程跟上面是一樣的,只不過是“壓縮”到了一個語句里面完成。
以上這些問題,就是把大家提過的關于redo log和binlog的問題串起來,做的一次集中回答。如果你還有問題,可以在評論區繼續留言補充。
WAL 的全稱是Write-Ahead Logging,它的關鍵點就是先寫日志,再寫磁盤。 提升性能的核心機制,也的確是盡量減少隨機讀寫
結論:只要redo log和binlog保證持久化到磁盤,就能確保MySQL異常重啟后,數據可以恢復。
但是redo log的寫入流程是怎么樣的,如何保證redo log真實地寫入了磁盤。
其實,binlog的寫入邏輯比較簡單:事務執行過程中,先把日志寫到binlog cache,事務提交的時候,再把binlog cache寫到binlog文件中。
一個事務的binlog是不能被拆開的,因此不論這個事務多大,也要確保一次性寫入。這就涉及到了binlog cache的保存問題。
系統給binlog cache分配了一片內存,每個線程一個,參數 binlog_cache_size用于控制單個線程內binlog cache所占內存的大小。如果超過了這個參數規定的大小,就要暫存到磁盤。
事務提交的時候,執行器把binlog cache里的完整事務寫入到binlog中,并清空binlog cache。狀態如圖1所示。
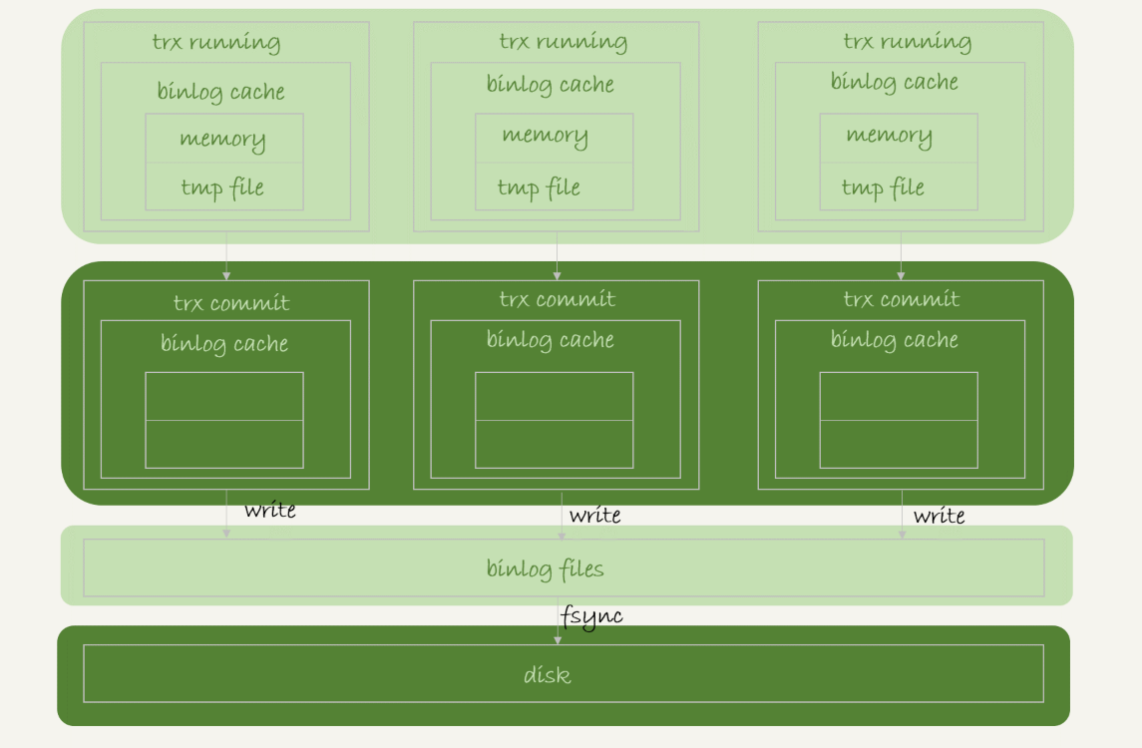
圖1 binlog寫盤狀態
可以看到,每個線程有自己binlog cache,但是共用同一份binlog文件。
圖中的write,指的就是指把日志寫入到文件系統的page cache,并沒有把數據持久化到磁盤,所以速度比較快。
圖中的fsync,才是將數據持久化到磁盤的操作。一般情況下,我們認為fsync才占磁盤的IOPS。
write 和fsync的時機,是由參數sync_binlog控制的:
sync_binlog=0的時候,表示每次提交事務都只write,不fsync;
sync_binlog=1的時候,表示每次提交事務都會執行fsync;
sync_binlog=N(N>1)的時候,表示每次提交事務都write,但累積N個事務后才fsync。
因此,在出現IO瓶頸的場景里,將sync_binlog設置成一個比較大的值,可以提升性能。在實際的業務場景中,考慮到丟失日志量的可控性,一般不建議將這個參數設成0,比較常見的是將其設置為100~1000中的某個數值。
但是,將sync_binlog設置為N,對應的風險是:如果主機發生異常重啟,會丟失最近N個事務的binlog日志。
接下來,我們再說說redo log的寫入機制。上文介紹了redo log buffer。事務在執行過程中,生成的redo log是要先寫到redo log buffer的。
然后就有同學問了,redo log buffer里面的內容,是不是每次生成后都要直接持久化到磁盤呢?答案是,不需要。
如果事務執行期間MySQL發生異常重啟,那這部分日志就丟了。由于事務并沒有提交,所以這時日志丟了也不會有損失。
那么,另外一個問題是,事務還沒提交的時候,redo log buffer中的部分日志有沒有可能被持久化到磁盤呢?
答案是,確實會有。
這個問題,要從redo log可能存在的三種狀態說起。這三種狀態,對應的就是圖2 中的三個顏色塊。
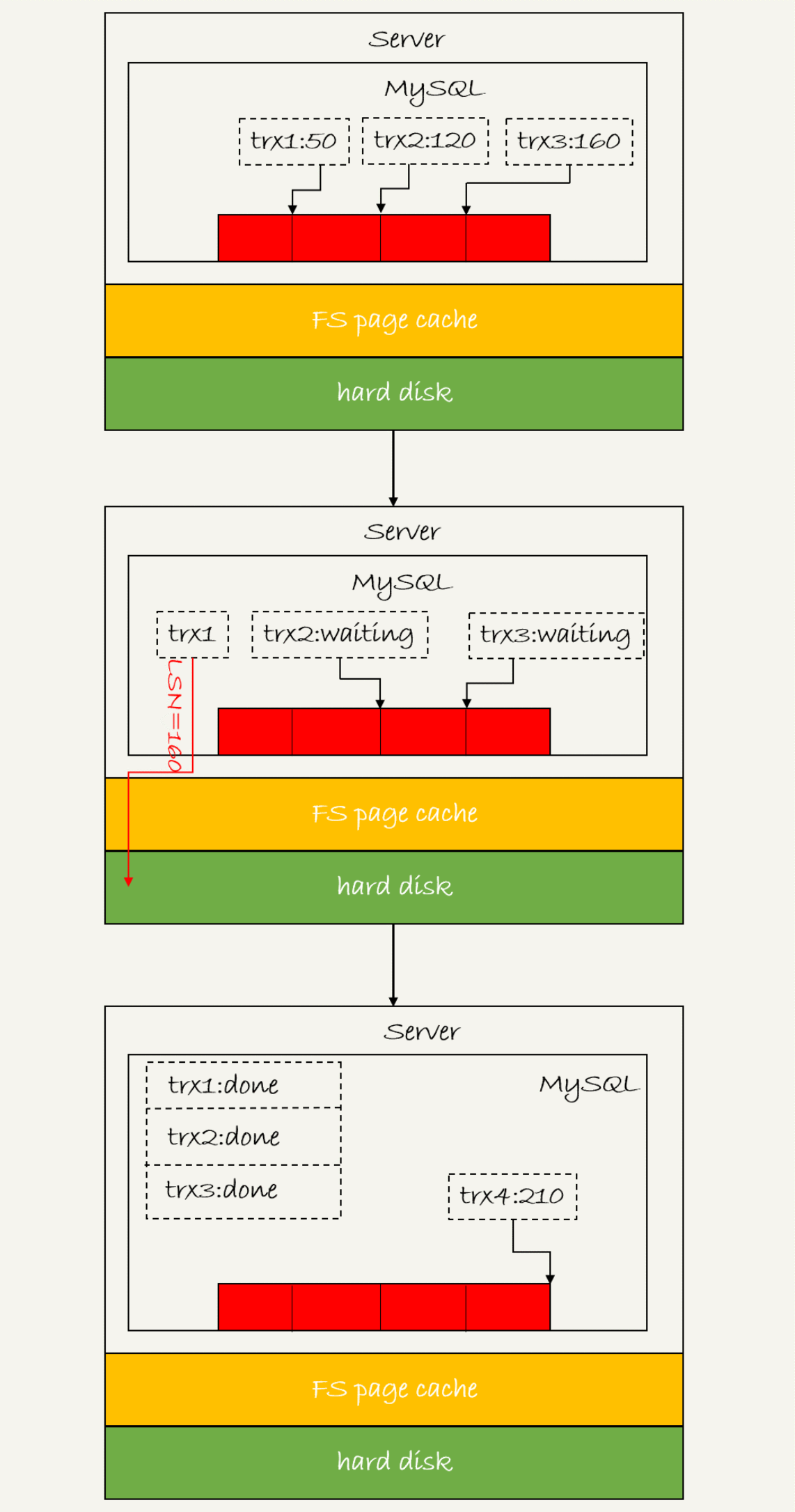
圖3 redo log 組提交
從圖中可以看到,
trx1是第一個到達的,會被選為這組的 leader;
等trx1要開始寫盤的時候,這個組里面已經有了三個事務,這時候LSN也變成了160;
trx1去寫盤的時候,帶的就是LSN=160,因此等trx1返回時,所有LSN小于等于160的redo log,都已經被持久化到磁盤;
這時候trx2和trx3就可以直接返回了。
所以,一次組提交里面,組員越多,節約磁盤IOPS的效果越好。但如果只有單線程壓測,那就只能老老實實地一個事務對應一次持久化操作了。
在并發更新場景下,第一個事務寫完redo log buffer以后,接下來這個fsync越晚調用,組員可能越多,節約IOPS的效果就越好。
為了讓一次fsync帶的組員更多,MySQL有一個很有趣的優化:拖時間。在介紹兩階段提交的時候,我曾經給你畫了一個圖,現在我把它截過來。
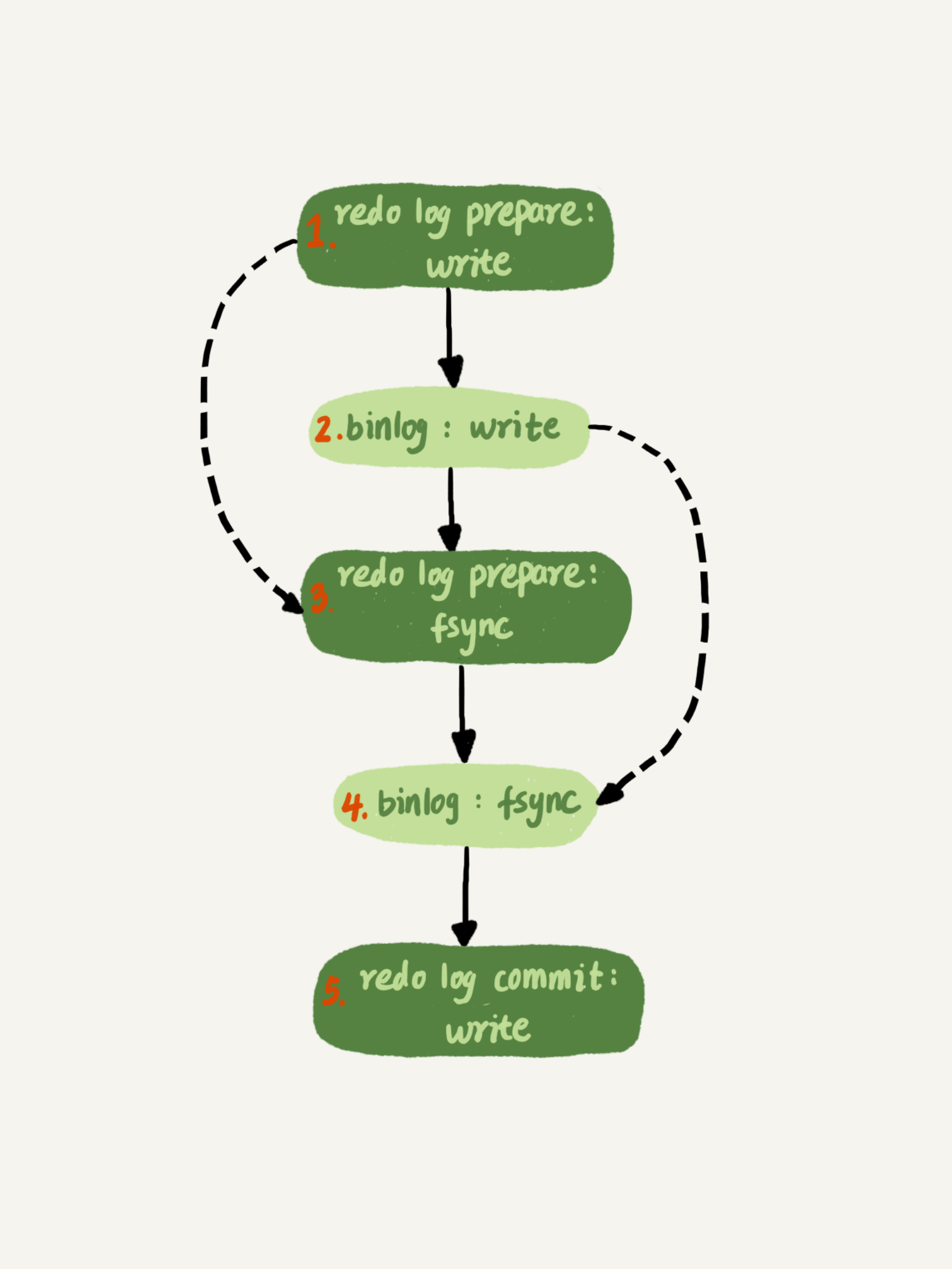
圖5 兩階段提交細化
這么一來,binlog也可以組提交了。在執行圖5中第4步把binlog fsync到磁盤時,如果有多個事務的binlog已經寫完了,也是一起持久化的,這樣也可以減少IOPS的消耗。
不過通常情況下第3步執行得會很快,所以binlog的write和fsync間的間隔時間短,導致能集合到一起持久化的binlog比較少,因此binlog的組提交的效果通常不如redo log的效果那么好。
如果你想提升binlog組提交的效果,可以通過設置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count來實現。
binlog_group_commit_sync_delay參數,表示延遲多少微秒后才調用fsync;
binlog_group_commit_sync_no_delay_count參數,表示累積多少次以后才調用fsync。
這兩個條件是或的關系,也就是說只要有一個滿足條件就會調用fsync。
所以,當binlog_group_commit_sync_delay設置為0的時候,binlog_group_commit_sync_no_delay_count也無效了。
之前有同學在評論區問到,WAL機制是減少磁盤寫,可是每次提交事務都要寫redo log和binlog,這磁盤讀寫次數也沒變少呀?
現在你就能理解了,WAL機制主要得益于兩個方面:
redo log 和 binlog都是順序寫,磁盤的順序寫比隨機寫速度要快;
組提交機制,可以大幅度降低磁盤的IOPS消耗。
分析到這里,我們再來回答這個問題:如果你的MySQL現在出現了性能瓶頸,而且瓶頸在IO上,可以通過哪些方法來提升性能呢?
針對這個問題,可以考慮以下三種方法:
設置 binlog_group_commit_sync_delay 和 binlog_group_commit_sync_no_delay_count參數,減少binlog的寫盤次數。這個方法是基于“額外的故意等待”來實現的,因此可能會增加語句的響應時間,但沒有丟失數據的風險。
將sync_binlog 設置為大于1的值(比較常見是100~1000)。這樣做的風險是,主機掉電時會丟binlog日志。
將innodb_flush_log_at_trx_commit設置為2。這樣做的風險是,主機掉電的時候會丟數據。
我不建議你把innodb_flush_log_at_trx_commit 設置成0。因為把這個參數設置成0,表示redo log只保存在內存中,這樣的話MySQL本身異常重啟也會丟數據,風險太大。而redo log寫到文件系統的page cache的速度也是很快的,所以將這個參數設置成2跟設置成0其實性能差不多,但這樣做MySQL異常重啟時就不會丟數據了,相比之下風險會更小。
在專欄的第2篇和第15篇文章中,我和你分析了,如果redo log和binlog是完整的,MySQL是如何保證crash-safe的。今天這篇文章,我著重和你介紹的是MySQL是“怎么保證redo log和binlog是完整的”。
希望這三篇文章串起來的內容,能夠讓你對crash-safe這個概念有更清晰的理解。
之前的第15篇答疑文章發布之后,有同學繼續留言問到了一些跟日志相關的問題,這里為了方便你回顧、學習,我再集中回答一次這些問題。
問題1:執行一個update語句以后,我再去執行hexdump命令直接查看ibd文件內容,為什么沒有看到數據有改變呢?
回答:這可能是因為WAL機制的原因。update語句執行完成后,InnoDB只保證寫完了redo log、內存,可能還沒來得及將數據寫到磁盤。
問題2:為什么binlog cache是每個線程自己維護的,而redo log buffer是全局共用的?
回答:MySQL這么設計的主要原因是,binlog是不能“被打斷的”。一個事務的binlog必須連續寫,因此要整個事務完成后,再一起寫到文件里。
而redo log并沒有這個要求,中間有生成的日志可以寫到redo log buffer中。redo log buffer中的內容還能“搭便車”,其他事務提交的時候可以被一起寫到磁盤中。
問題3:事務執行期間,還沒到提交階段,如果發生crash的話,redo log肯定丟了,這會不會導致主備不一致呢?
回答:不會。因為這時候binlog 也還在binlog cache里,沒發給備庫。crash以后redo log和binlog都沒有了,從業務角度看這個事務也沒有提交,所以數據是一致的。
問題4:如果binlog寫完盤以后發生crash,這時候還沒給客戶端答復就重啟了。等客戶端再重連進來,發現事務已經提交成功了,這是不是bug?
回答:不是。
你可以設想一下更極端的情況,整個事務都提交成功了,redo log commit完成了,備庫也收到binlog并執行了。但是主庫和客戶端網絡斷開了,導致事務成功的包返回不回去,這時候客戶端也會收到“網絡斷開”的異常。這種也只能算是事務成功的,不能認為是bug。
實際上數據庫的crash-safe保證的是:
如果客戶端收到事務成功的消息,事務就一定持久化了;
如果客戶端收到事務失敗(比如主鍵沖突、回滾等)的消息,事務就一定失敗了;
如果客戶端收到“執行異常”的消息,應用需要重連后通過查詢當前狀態來繼續后續的邏輯。此時數據庫只需要保證內部(數據和日志之間,主庫和備庫之間)一致就可以了。
到此,相信大家對“MySQL是如何保證數據不丟的”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





