溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
監控利器Prometheus怎么用,針對這個問題,這篇文章詳細介紹了相對應的分析和解答,希望可以幫助更多想解決這個問題的小伙伴找到更簡單易行的方法。
前言:
Kubernetes作為當下最炙手可熱的容器管理平臺,在給應用部署運維帶來便捷的同時,也給應用及性能監控帶來了新的挑戰。下面給大家分享一款十分火熱的開源監控工具Prometheus,讓我們一起來看它是如何兼顧傳統的應用監控、主機性能監控和
一、Prometheus簡介
什么是Prometheus?
Prometheus是一個開源的系統監控及告警工具,最初建設在SoundCloud。從2012 Prometheus推出以來,許多公司都采用它搭建監控及告警系統。同時,項目擁有非常活躍的開發者和用戶社區。
它現在是一個獨立于任何公司的開源項目,為了強調這一點并明確項目的管理結構,在2016年Prometheus加入CNCF基金會成為繼Kubernetes之后的第二個托管項目。
Prometheus有什么特點?
多維的數據模型(基于時間序列的k/v鍵值對)。
靈活的查詢及聚合語句(PromQL)。
不依賴分布式存儲,節點自治。
基于HTTP的pull模式采集時間序列數據。
可以使用pushgateway(prometheus的可選中間件)實現push模式。
可以使用動態服務發現或靜態配置采集的目標機器。
支持多種圖形及儀表盤。
Prometheus適用場景。
在選擇Prometheus作為監控工具前,要明確它的適用范圍,以及不適用的場景。
Prometheus在記錄純數值時間序列方面表現非常好。它既適用于以服務器為中心的監控,也適用于高動態的面向服務架構的監控。
在微服務的監控上,Prometheus對多維度數據采集及查詢的支持也是特殊的優勢。
Prometheus更強調可靠性,即使在故障的情況下也能查看系統的統計信息。權衡利弊,以可能丟失少量數據為代價確保整個系統的可用性。因此,它不適用于對數據準確率要求100%的系統,比如實時計費系統(涉及到錢)。
二、Prometheus構架圖
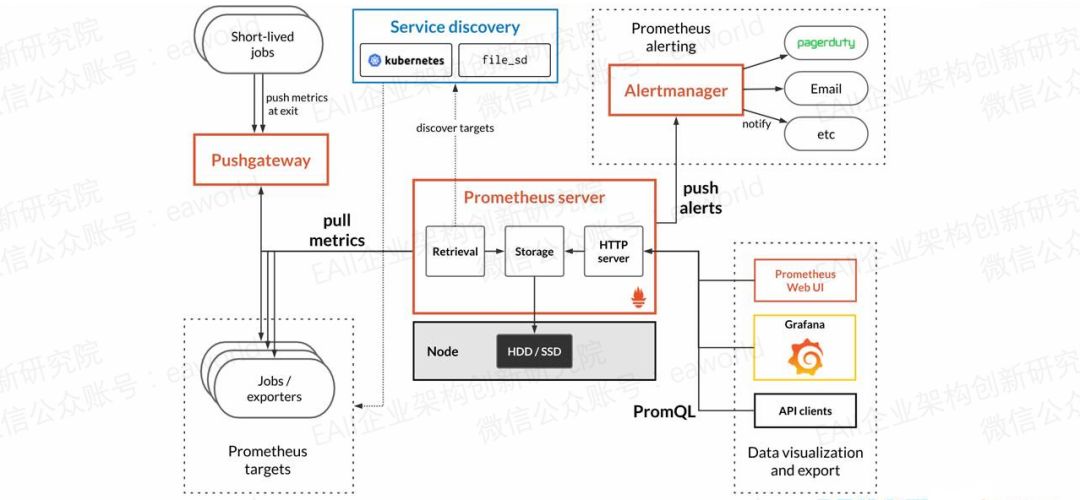
上圖是Prometheus的架構圖,從圖中可以看出Prometheus的架構設計理念,中心化的數據采集,分析。
1. Prometheus Server:Prometheus的核心,根據配置完成數據采集, 服務發現以及數據存儲。
2. Pushgateway:為應對部分push場景提供的插件,監控數據先推送到pushgateway上,然后再由server端采集pull。(若server采集間隔期間,pushgateway上的數據沒有變化,server將采集2次相同數據,僅時間戳不同)
3. Prometheus targets:探針(exporter)提供采集接口,或應用本身提供的支持Prometheus數據模型的采集接口。
4. Service discovery:支持根據配置file_sd監控本地配置文件的方式實現服務發現(需配合其他工具修改本地配置文件),同時支持配置監聽Kubernetes的API來動態發現服務。
5. Alertmanager:Prometheus告警插件,支持發送告警到郵件,Pagerduty,HipChat等。
三、Prometheus架構詳解
接下來,讓我們一起了解rometheus架構中各個組件是如何協同工作來完成監控任務。
Prometheus server and targets
利用Prometheus官方或第三方提供的探針,基本可以完成對所有常用中間件或第三方工具的監控。
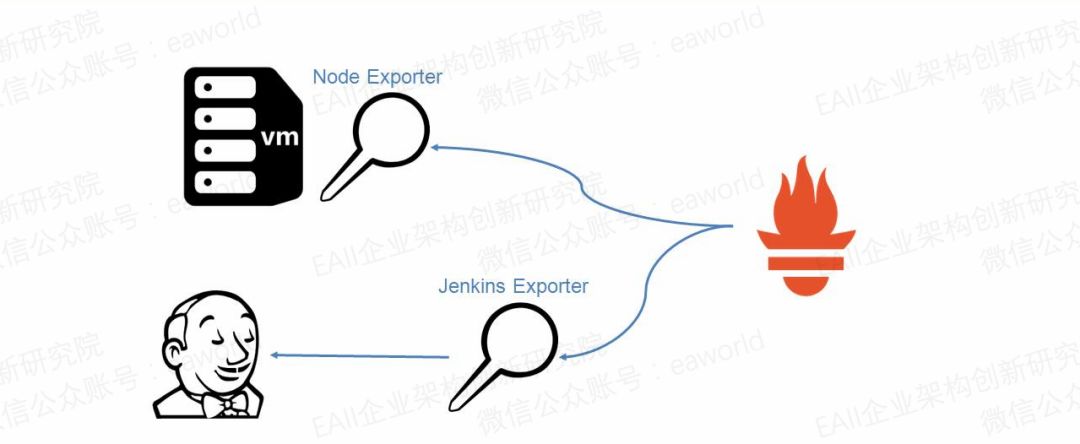
之前講到Prometheus是中心化的數據采集分析,那這里的探針(exporter)是做什么工作呢?
上圖中硬件及系統監控探針node exporter通過getMemInfo()方法獲取機器的內存信息,然后將機器總內存數據對應上指標node_memory_MemTotal。
Jenkins探針Jenkins Exporter通過訪問Jenkins的api獲取到Jenkins的job數量并對應指標Jenkins_job_count_value。
探針的作用就是通過調用應用或系統接口的方式采集監控數據并對應成指標返回給prometheus server。(探針不一定要和監控的應用部署在一臺機器)
總的來說Prometheus數據采集流程就是,在Prometheus server中配置探針暴露的端口地址以及采集的間隔時間,Prometheus按配置的時間間隔通過http的方式去訪問探針,這時探針通過調用接口的方式獲取監控數據并對應指標返回給Prometheus server進行存儲。(若探針在Prometheus配置的采集間隔時間內沒有完成采集數據,這部分數據就會丟失)
Prometheus alerting

Prometheus serve又是如何根據采集到的監控數據配和alertmanager完成告警呢?
舉一個常見的告警示例,在主機可用內存低于總內存的20%時發送告警。我們可以根據Prometheus server采集的主機性能指標配置這樣一條規則node_memory_Active/node_memory_MemTotal < 0.2,Prometheus server分析采集到的數據,當滿足該條件時,發送告警信息到alertmanager,alertmanager根據本地配置處理告警信息并發送到第三方工具由相關的負責人接收。
Prometheus server在這里主要負責根據告警規則分析數據并發送告警信息到alertmanager,alertmanager則是根據配置處理告警信息并發送。
Alertmanager又有哪些處理告警信息的方式呢?
分組:將監控目標相同的告警進行分組。如發生停電,收到的應該是單一信息,信息中包含所有受影響宕機的機器,而不是針對每臺宕機的機器都發送一條告警信息。
抑制:抑制是指當告警發出后,停止發送由此告警引發的其他告警的機制。如機器網絡不可達,就不再發送因網絡問題造成的其他告警。
沉默:根據定義的規則過濾告警信息,匹配的告警信息不會發送。
Service discovery
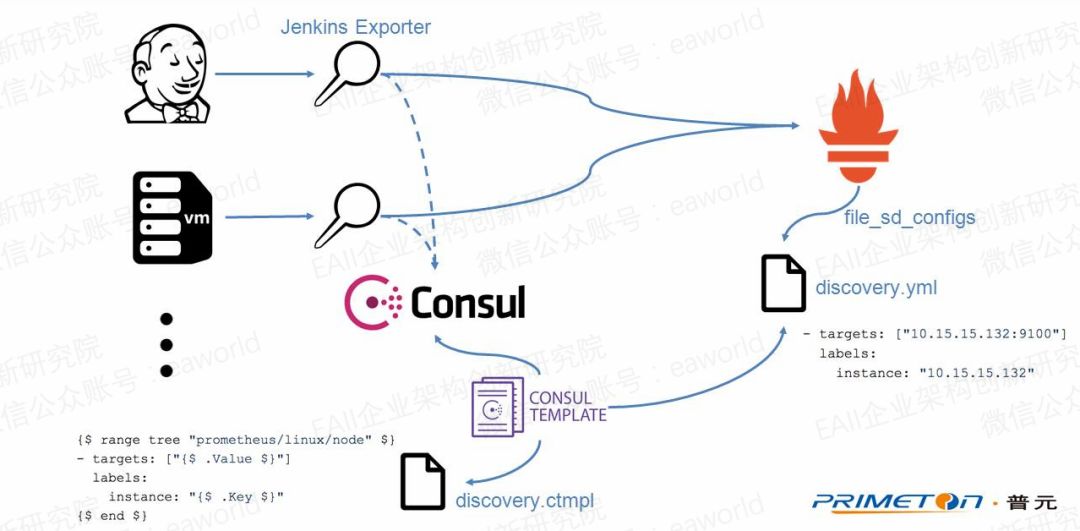
Prometheus支持多種服務發現的方式,這里主要介紹架構圖中提到的file_sd的方式。之前提到Prometheus server的數據采集配置都是通過配置文件,那服務發現該怎么做?總不能每次要添加采集目標還要修改配置文件并重啟服務吧。
這里使用file_sd_configs指定定義了采集目標的文件。Prometheus server會動態檢測該配置文件的變化來更新采集目標信息。現在只要能更新這個配置文件就能動態的修改采集目標的配置了。
這里采用consul+consul template的方式。在新增或減少探針(增減采集目標)時在consul更新k/v,如新增一個探針,添加如下記錄Prometheus/linux/node/10.15.15.132=10.15.15.132:9100,然后配置consul template監控consul的Prometheus/linux/node/目錄下k/v的變化,根據k/v的值以及提前定義的discovery.ctmpl模板動態生成Prometheus server的配置文件discovery.yml。
Web UI

至此,已經完成了數據采集和告警配置,是時候通過頁面展示一波成果了。
Grafana已經對Prometheus做了很好的支撐,在Grafana中添加Prometheus數據源,然后就可以使用PromQL查詢語句結合grafana強大的圖形化能力來配置我們的性能監控頁面了。
聯邦模式
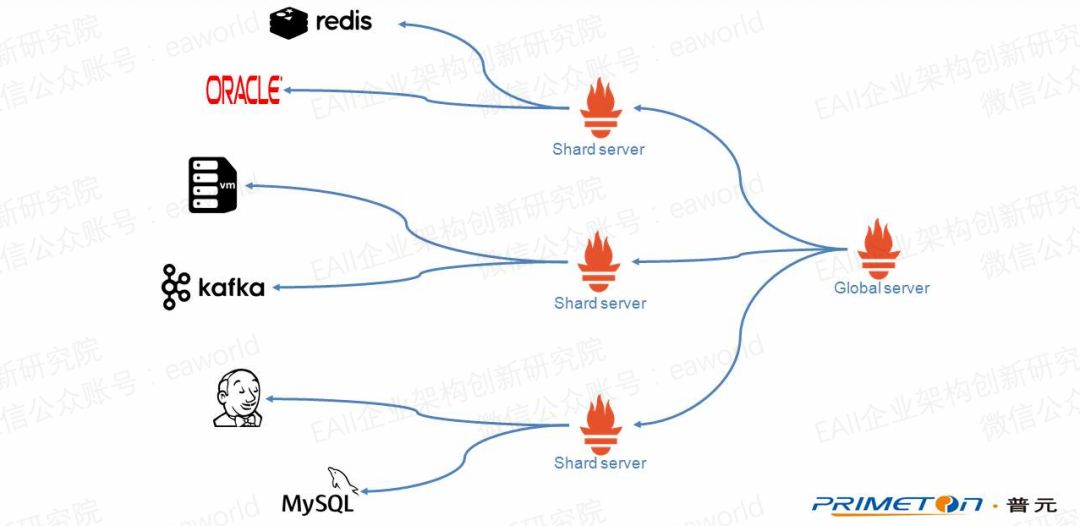
中心化的數據采集存儲,分析,而且還不支持集群模式。帶來的性能問題顯而易見。Prometheus給出了一種聯邦的部署方式,就是Prometheus server可以從其他的Prometheus server采集數據。
可能有人會問,這樣最后的數據不是還是要全部匯集到Prometheus的global節點嗎?
并不是這樣的,我們可以在shard節點就完成分析處理,然后global節點直接采集分析處理過的數據進行展示。
比如在shard節點定義指標可用內存占比job:memory_available:proportion的結果為(node_memory_MemFree + node_memory_Buffers + node_memory_Cached)/node_memory_MemTotal,這樣在shard節點就可以完成聚合操作,然后global節點直接采集處理過的數據就可以了,而不用采集零散的如node_memory_MemFree這類指標。
四、Prometheus監控Kubernetes
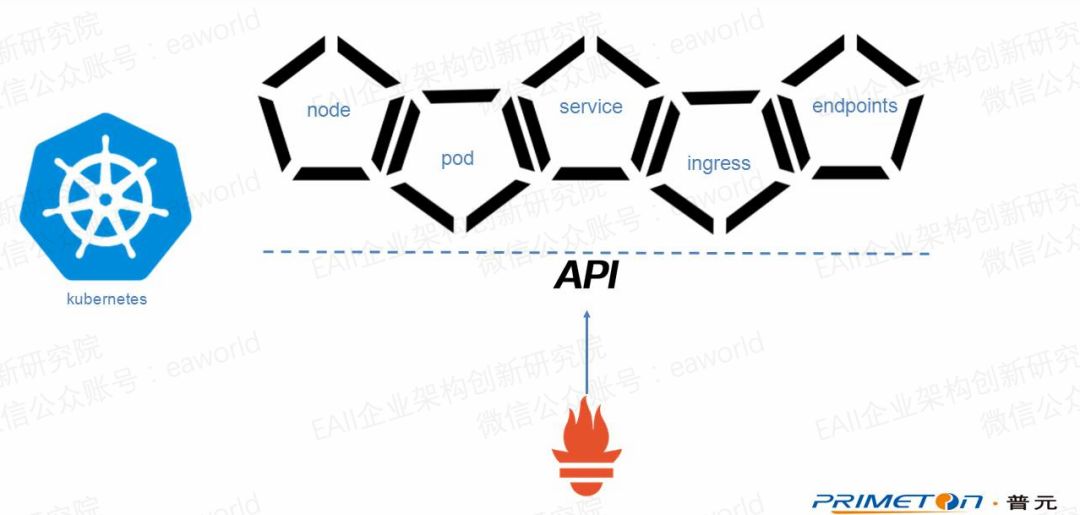
Kubernetes官方之前推薦了一種性能監控的解決方案,heapster+influxdb,heapster根據定義的間隔時間從Advisor中獲取的關于pod及container的性能數據并存儲到時間序列數據庫influxdb。
也可以使用grafana配置influxdb的數據源并配置dashboard來做展現。而且Kubernetes中pod的自動伸縮的功能(Horizontal Pod Autoscaling)也是基于heapster,默認支持根據cpu的指標做動態伸縮,也可以自定義擴展使用其他指標。
但是Heapster無法做Kubernetes下應用的監控。現在,Heapster作為Kubernetes下的開源監控解決方案已經被其棄用(https://github.com/kubernetes/heapster),Prometheus成為Kubernetes官方推薦的監控解決方案。
Prometheus同樣通過Kubernetes的cAdvisor接口(/api/v1/nodes/${1}/proxy/metrics/cadvisor)獲取pod和container的性能監控數據,同時可以使用Kubernetes的Kube-state-metrics插件來獲取集群上Pod, DaemonSet, Deployment, Job, CronJob等各種資源對象的狀態,這反應了使用這些資源的應用的狀態。
同時通過Kubernetes api獲取node,service,pod,endpoints,ingress等服務的信息,然后通過匹配注解中的值來獲取采集目標。
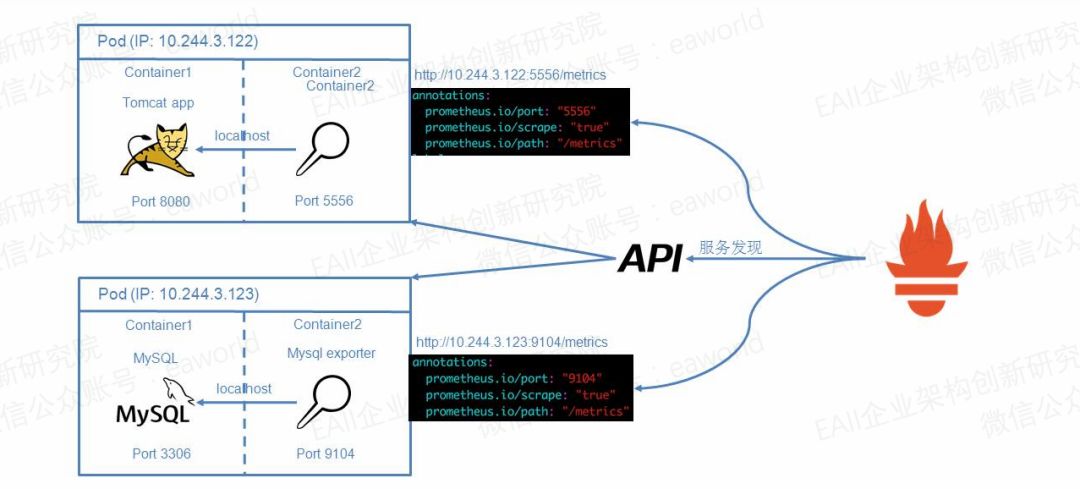
上面提到了Prometheus可以通過Kubernetes的api接口實現服務發現,并將匹配定義了annotation參數的pod,service等配置成采集目標。那現在要解決的問題就是探針到應用部署配置問題了。
這里我們使用了Kubernetes的pod部署的sidecar模式,單個應用pod部署2個容器,利用單個pod中僅共享網絡的namespace的隔離特性,探針與應用一同運行,并可以使用localhost直接訪問應用的端口,而在pod的注解中僅暴露探針的端口(prometheus.io/port: “9104”)即可。
Prometheus server根據配置匹配定義注解prometheus.io/scrape: “true”的pod,并將pod ip和注解中定義的端口(prometheus.io/port: “9104”)和路徑(prometheus.io/path: “/metrics”)拼接成采集目標http://10.244.3.123:9104/metrics。通過這種方式就可以完成動態添加需要采集的應用。
關于監控利器Prometheus怎么用問題的解答就分享到這里了,希望以上內容可以對大家有一定的幫助,如果你還有很多疑惑沒有解開,可以關注億速云行業資訊頻道了解更多相關知識。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





