溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
小編給大家分享一下網易數據湖Iceberg的示例分析,相信大部分人都還不怎么了解,因此分享這篇文章給大家參考一下,希望大家閱讀完這篇文章后大有收獲,下面讓我們一起去了解一下吧!
痛點一:
我們凌晨一些大的離線任務經常會因為一些原因出現延遲,這種延遲會導致核心報表的產出時間不穩定,有些時候會產出比較早,但是有時候就可能會產出比較晚,業務很難接受。
為什么會出現這種現象的發生呢?目前來看大致有這么幾點要素:
任務本身要請求的數據量會特別大。通常來說一天原始的數據量可能在幾十TB。幾百個分區,甚至上千個分區,五萬+的文件數這樣子。如果說全量讀取這些文件的話,幾百個分區就會向NameNode發送幾百次請求,我們知道離線任務在凌晨運行的時候,NameNode的壓力是非常大的。所以就很有可能出現Namenode響應很慢的情況,如果請求響應很慢就會導致任務初始化時間很長。
任務本身的ETL效率是相對低效的,這個低效并不是說Spark引擎低效,而是說我們的存儲在這塊支持的不是特別的好。比如目前我們查一個分區的話是需要將所有文件都掃描一遍然后進行分析,而實際上我可能只對某些文件感興趣。所以相對而言這個方案本身來說就是相對低效的。
這種大的離線任務一旦遇到磁盤壞盤或者機器宕機,就需要重試,重試一次需要耗費很長的時間比如幾十分鐘。如果說重試一兩次的話這個延遲就會比較大了。
痛點二:
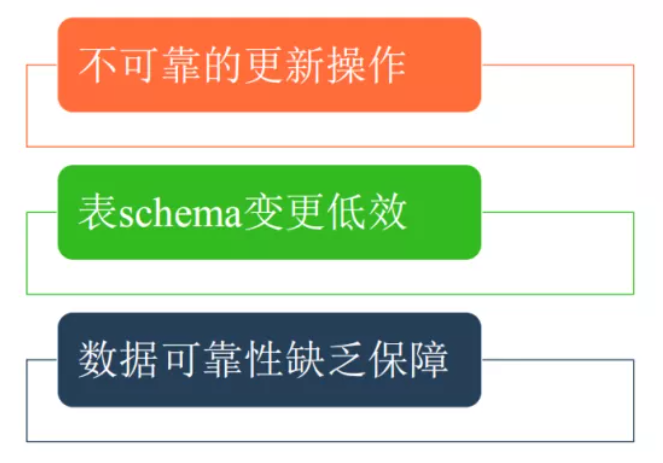
針對一些細瑣的一些問題而言的。這里簡單列舉了三個場景來分析:
不可靠的更新操作。我們經常在ETL過程中執行一些insert overwrite之類的操作,這類操作會先把相應分區的數據刪除,再把生成的文件加載到分區中去。在我們移除文件的時候,很多正在讀取這些文件的任務就會發生異常,這就是不可靠的更新操作。
表Schema變更低效。目前我們在對表做一些加字段、更改分區的操作其實是非常低效的操作,我們需要把所有的原始數據讀出來,然后在重新寫回去。這樣就會非常耗時,并且低效。
數據可靠性缺乏保障。主要是我們對于分區的操作,我們會把分區的信息分為兩個地方,HDFS和Metastore,分別存儲一份。在這種情況下,如果進行更新操作,就可能會出現一個更新成功而另一個更新失敗,會導致數據不可靠。
痛點三:
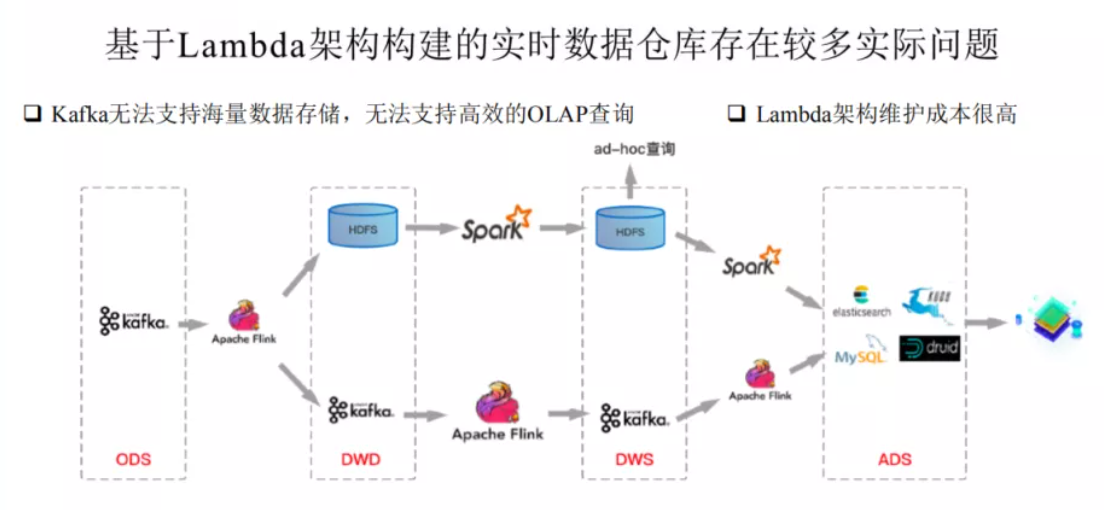
基于Lambda架構建設的實時數倉存在較多的問題。如上圖的這個架構圖,第一條鏈路是基于kafka中轉的一條實時鏈路(延遲要求小于5分鐘),另一條是離線鏈路(延遲大于1小時),甚至有些公司會有第三條準實時鏈路(延遲要求5分鐘~一小時),甚至更復雜的場景。
兩條鏈路對應兩份數據,很多時候實時鏈路的處理結果和離線鏈路的處理結果對不上。
Kafka無法存儲海量數據, 無法基于當前的OLAP分析引擎高效查詢Kafka中的數據。
Lambda維護成本高。代碼、數據血緣、Schema等都需要兩套。運維、監控等成本都非常高。
痛點四:
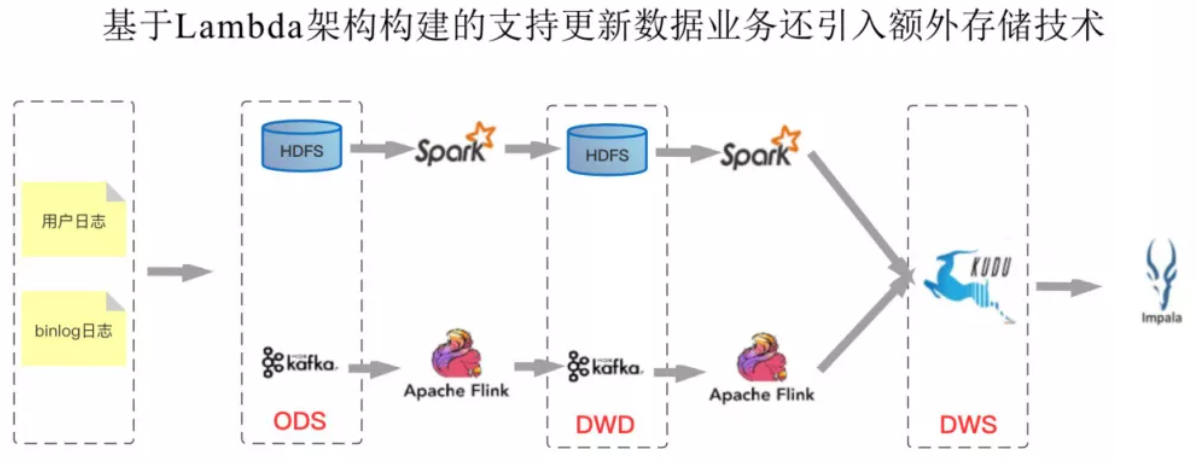
不能友好地支持高效更新場景。大數據的更新場景一般有兩種,一種是CDC ( Change Data Capture ) 的更新,尤其在電商的場景下,將binlog中的更新刪除同步到HDFS上。另一種是延遲數據帶來的聚合后結果的更新。目前HDFS只支持追加寫,不支持更新。因此業界很多公司引入了Kudu。但是Kudu本身是有一些局限的,比如計算存儲沒有做到分離。這樣整個數倉系統中引入了HDFS、Kafka以及Kudu,運維成本不可謂不大。
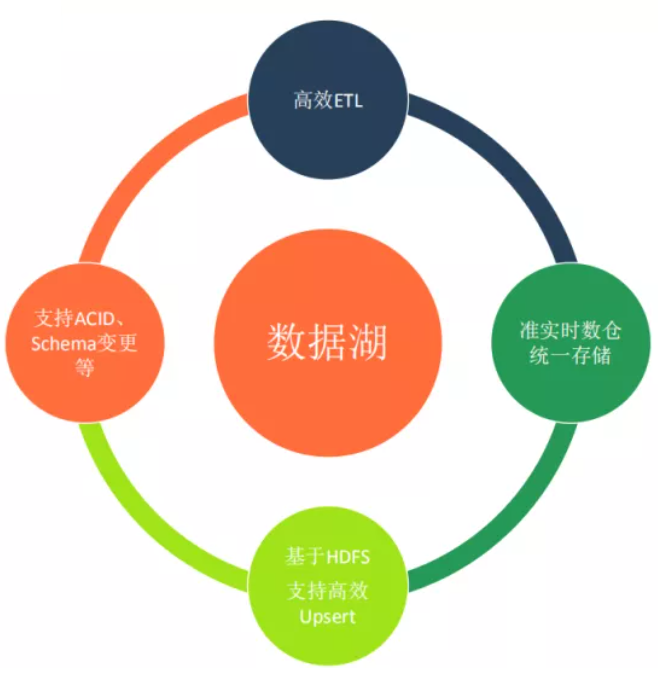
上面就是針對目前數倉所涉及到的四個痛點的大致介紹,因此我們也是通過對數據湖的調研和實踐,希望能在這四個方面對數倉建設有所幫助。接下來重點講解下對數據湖的一些思考。
1. 數據湖開源產品調研
數據湖大致是從19年開始慢慢火起來的,目前市面上核心的數據湖開源產品大致有這么幾個:
DELTA LAKE,在17年的時候DataBricks就做了DELTA LAKE的商業版。主要想解決的也是基于Lambda架構帶來的存儲問題,它的初衷是希望通過一種存儲來把Lambda架構做成kappa架構。
Hudi ( Uber開源 ) 可以支持快速的更新以及增量的拉取操作。這是它最大的賣點之一。
Iceberg的初衷是想做標準的Table Format以及高效的ETL。
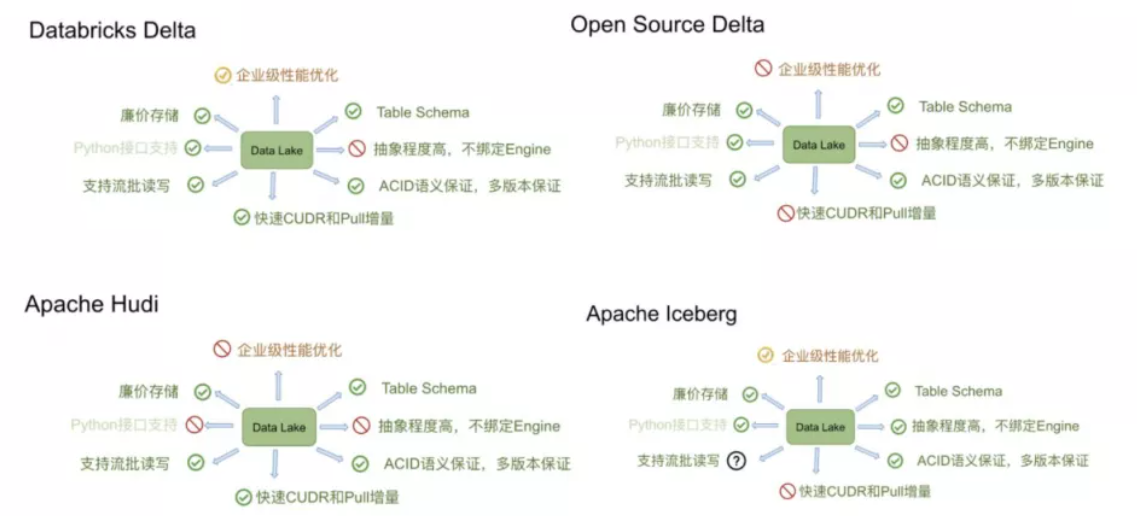
上圖是來自阿里Flink團體針對數據湖方案的一些調研對比,總體來看這些方案的基礎功能相對都還是比較完善的。我說的基礎功能主要包括:
高效Table Schema的變更,比如針對增減分區,增減字段等功能
ACID語義保證
同時支持流批讀寫,不會出現臟讀等現象
支持OSS這類廉價存儲
2. 當然還有一些不同點:
Hudi的特性主要是支持快速的更新刪除和增量拉取。
Iceberg的特性主要是代碼抽象程度高,不綁定任何的Engine。它暴露出來了非常核心的表層面的接口,可以非常方便的與Spark/Flink對接。然而Delta和Hudi基本上和spark的耦合很重。如果想接入flink,相對比較難。
3. 我們選擇Iceberg的原因:
現在國內的實時數倉建設圍繞flink的情況會多一點。所以能夠基于flink擴展生態,是我們選擇iceberg一個比較重要的點。
國內也有很多基于Iceberg開發的重要力量,比如騰訊團隊、阿里Flink官方團隊,他們的數據湖選型也是Iceberg。目前他們在社區分別主導update以及flink的生態對接。
4. 接下來我們重點介紹一下Iceberg:
這是來自官方對于Iceberg的一段介紹,大致就是Iceberg是一個開源的基于表格式的數據湖。關于table format再給大家詳細介紹下:
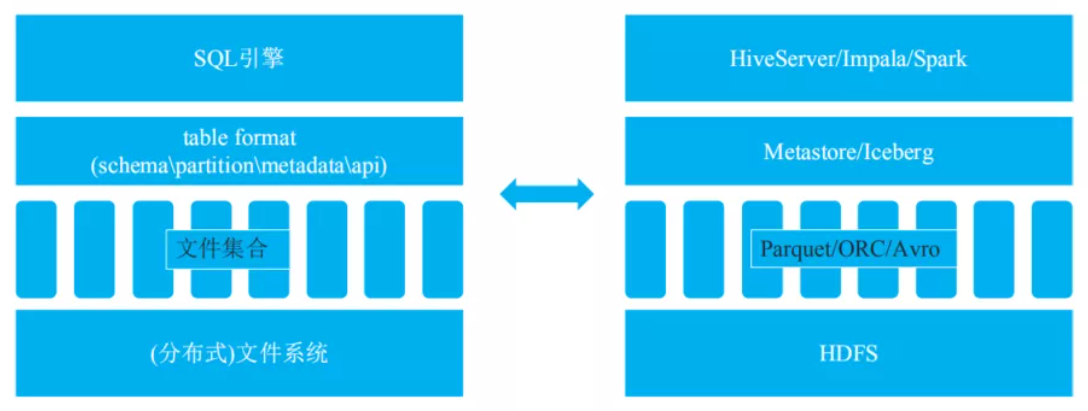
左側圖是一個抽象的數據處理系統,分別由SQL引擎、table format、文件集合以及分布式文件系統構成。右側是對應的現實中的組件,SQL引擎比如HiveServer、Impala、Spark等等,table format比如Metastore或者Iceberg,文件集合主要有Parquet文件等,而分布式文件系統就是HDFS。
對于table format,我認為主要包含4個層面的含義,分別是表schema定義(是否支持復雜數據類型),表中文件的組織形式,表相關統計信息、表索引信息以及表的讀寫API實現。詳述如下:
表schema定義了一個表支持字段類型,比如int、string、long以及復雜數據類型等。
表中文件組織形式最典型的是Partition模式,是Range Partition還是Hash Partition。
Metadata數據統計信息。
封裝了表的讀寫API。上層引擎通過對應的API讀取或者寫入表中的數據。
和Iceberg差不多相當的一個組件是Metastore。不過Metastore是一個服務,而Iceberg就是一個jar包。這里就Metastore 和 Iceberg在表格式的4個方面分別進行一下對比介紹:
① 在schema層面上沒有任何區別:
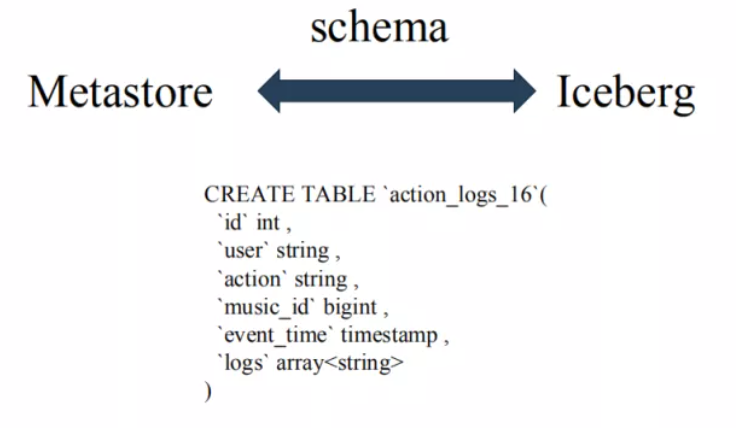
都支持int、string、bigint等類型。
② partition實現完全不同:
兩者在partition上有很大的不同:
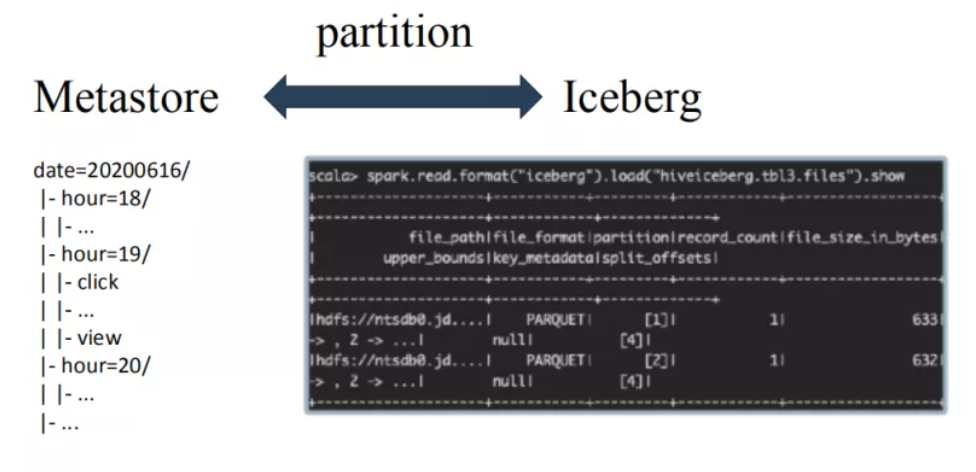
metastore中partition字段不能是表字段,因為partition字段本質上是一個目錄結構,不是用戶表中的一列數據。基于metastore,用戶想定位到一個partition下的所有數據,首先需要在metastore中定位出該partition對應的所在目錄位置信息,然后再到HDFS上執行list命令獲取到這個分區下的所有文件,對這些文件進行掃描得到這個partition下的所有數據。
iceberg中partition字段就是表中的一個字段。Iceberg中每一張表都有一個對應的文件元數據表,文件元數據表中每條記錄表示一個文件的相關信息,這些信息中有一個字段是partition字段,表示這個文件所在的partition。
很明顯,iceberg表根據partition定位文件相比metastore少了一個步驟,就是根據目錄信息去HDFS上執行list命令獲取分區下的文件。
試想,對于一個二級分區的大表來說,一級分區是小時時間分區,二級分區是一個枚舉字段分區,假如每個一級分區下有30個二級分區,那么這個表每天就會有24 * 30 = 720個分區。基于Metastore的partition方案,如果一個SQL想基于這個表掃描昨天一天的數據的話,就需要向Namenode下發720次list請求,如果掃描一周數據或者一個月數據,請求數就更是相當夸張。這樣,一方面會導致Namenode壓力很大,一方面也會導致SQL請求響應延遲很大。而基于Iceberg的partition方案,就完全沒有這個問題。
③ 表統計信息實現粒度不同:
Metastore中一張表的統計信息是表/分區級別粒度的統計信息,比如記錄一張表中某一列的記錄數量、平均長度、為null的記錄數量、最大值\最小值等。
Iceberg中統計信息精確到文件粒度,即每個數據文件都會記錄所有列的記錄數量、平均長度、最大值\最小值等。
很明顯,文件粒度的統計信息對于查詢中謂詞(即where條件)的過濾會更有效果。
④ 讀寫API實現不同:
metastore模式下上層引擎寫好一批文件,調用metastore的add partition接口將這些文件添加到某個分區下。
Iceberg模式下上層業務寫好一批文件,調用iceberg的commit接口提交本次寫入形成一個新的snapshot快照。這種提交方式保證了表的ACID語義。同時基于snapshot快照提交可以實現增量拉取實現。
總結下Iceberg相對于Metastore的優勢:
新partition模式:避免了查詢時n次調用namenode的list方法,降低namenode壓力,提升查詢性能
新metadata模式:文件級別列統計信息可以用來根據where字段進行文件過濾,很多場景下可以大大減少掃描文件數,提升查詢性能
新API模式:存儲批流一體
1. 流式寫入-增量拉取(基于Iceberg統一存儲模式可以同時滿足業務批量讀取以及增量訂閱需求)
2. 支持批流同時讀寫同一張表,統一表schema,任務執行過程中不會出現FileNotFoundException
Iceberg的提升體現在:
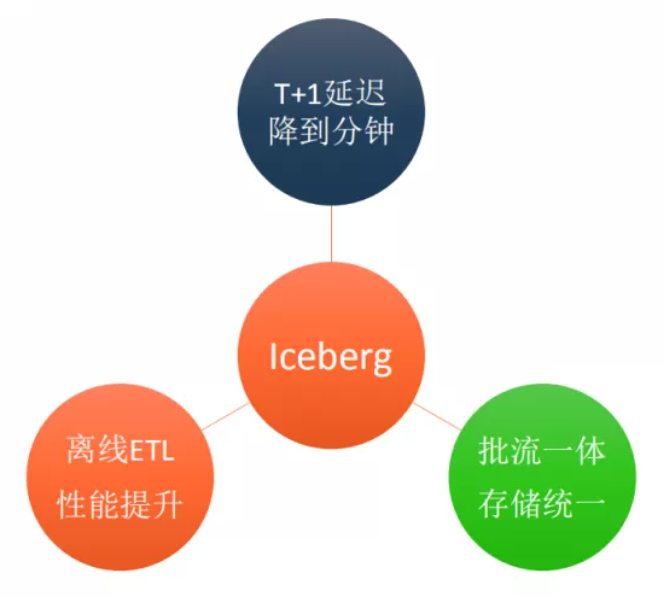
目前Iceberg主要支持的計算引擎包括Spark2.4.5、Spark 3.x以及Presto。同時,一些運維工作比如snapshot過期、小文件合并、增量訂閱消費等功能都可以實現。
在此基礎上,目前社區正在開發的功能主要有Hive集成、Flink集成以及支持Update/Delete功能。相信下一個版本就可以看到Hive/Flink集成的相關功能。
Iceberg針對目前的大數量的情況下,可以大大提升ETL任務執行的效率,這主要得益于新Partition模式下不再需要請求NameNode分區信息,同時得益于文件級別統計信息模式下可以過濾很多不滿足條件的數據文件。
當前iceberg社區僅支持Spark2.4.5,我們在這個基礎上做了更多計算引擎的適配工作。主要包括如下:
集成Hive。可以通過Hive創建和刪除iceberg表,通過HiveSQL查詢Iceberg表中的數據。
集成Impala。用戶可以通過Impala新建iceberg內表\外表,并通過Impala查詢Iceberg表中的數據。目前該功能已經貢獻給Impala社區。
集成Flink。已經實現了Flink到Iceberg的sink實現,業務可以消費kafka中的數據將結果寫入到Iceberg中。同時我們基于Flink引擎實現了小文件異步合并的功能,這樣可以實現Flink一邊寫數據文件,一邊執行小文件的合并。基于Iceberg的小文件合并通過commit的方式提交,不需要刪除合并前的小文件,也就不會引起讀取任務的任何異常。
以上是“網易數據湖Iceberg的示例分析”這篇文章的所有內容,感謝各位的閱讀!相信大家都有了一定的了解,希望分享的內容對大家有所幫助,如果還想學習更多知識,歡迎關注億速云行業資訊頻道!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





