溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“什么是Antlr4”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“什么是Antlr4”吧!
Antlr4(Another Tool for Language Recognition)是一款基于Java開發的開源的語法分析器生成工具,能夠根據語法規則文件生成對應的語法分析器,廣泛應用于DSL構建,語言詞法語法解析等領域。現在在非常多的流行的框架中都用使用,例如,在構建特定語言的AST方面,CheckStyle工具,就是基于Antlr來解析Java的語法結構的(當前Java Parser是基于JavaCC來解析Java文件的,據說有規劃在下個版本改用Antlr來解析),還有就是廣泛應用在DSL構建上,著名的Eclipse Xtext就有使用Antlr。
Antlr可以生成不同target的AST(https://www.antlr.org/download.html),包括Java、C++、JS、Python、C#等,可以滿足不同語言的開發需求。當前Antlr最新穩定版本為4.9,Antlr4官方github倉庫中,已經有數十種語言的grammer(https://github.com/antlr/grammars-v4,不過雖然這么多語言的規則文法定義都在一個倉庫中,但是每種語言的grammer的license是不一樣的,如果要使用,需要參考每種語言自己的語法結構的license)。
本文將首先介紹Antlr4 grammer的定義方式(簡單介紹語法結構,并介紹如何基于IDEA Antlr4插件進行調試),然后介紹如何通過Antlr4 grammer生成對應的AST,最后介紹Antlr4 的兩種AST遍歷方式:Visitor方式和Listener方式。
下面簡單介紹一部分Antlr4的g4(grammar)文件的寫法 (主要參考Antlr4官方wiki:https://github.com/antlr/antlr4/blob/master/doc/index.md)。 最有效的學習Antlr4的規則文法的寫法的方法,就是參考已有的規則文法,大家在學習中,可以參考已有語言的文法。而且Antlr4已經實現了數十種語言的文法,如果需要自己定義,可以參考和自己的語言最接近的文法來開發。
首先,如果有一點兒C或者Java基礎,對上手Antlr4 g4的文法非常快。主要有下面的一些文法結構:
注釋:和Java的注釋完全一致,也可參考C的注釋,只是增加了JavaDoc類型的注釋;
標志符:參考Java或者C的標志符命名規范,針對Lexer 部分的 Token 名的定義,采用全大寫字母的形式,對于parser rule命名,推薦首字母小寫的駝峰命名;
不區分字符和字符串,都是用單引號引起來的,同時,雖然Antlr g4支持 Unicode編碼(即支持中文編碼),但是建議大家盡量還有英文;
Action,行為,主要有@header 和@members,用來定義一些需要生成到目標代碼中的行為,例如,可以通過@header設置生成的代碼的package信息,@members可以定義額外的一些變量到Antlr4語法文件中;
Antlr4語法中,支持的關鍵字有:import, fragment, lexer, parser, grammar, returns, locals, throws, catch, finally, mode, options, tokens。
Antlr4整體結構如下:
/** Optional javadoc style comment */
grammar Name;
options {...}
import ... ;
tokens {...}
channels {...} // lexer only
@actionName {...}
rule1 // parser and lexer rules, possibly intermingled
...
ruleN一般如果語法非常復雜,會基于Lexer和Parser寫到兩個不同的文件中(例如Java,可參考:https://github.com/antlr/grammars-v4/tree/master/java/java8),如果語法比較簡單,可以只寫到一個文件中(例如Lua,可參考:https://github.com/antlr/grammars-v4/blob/master/lua/Lua.g4)。
下面我們結合Lua.g4中的一部分語法結構,介紹使用方法。寫Antlr4的文法,需要依據源碼的結構來決定。定義時,依據源碼文件的寫法,從上到下開始構造語法結構。例如,下面是Lua.g4的一部分:
chunk
: block EOF
;
block
: stat* retstat?
;
stat
: ';'
| varlist '=' explist
| functioncall
| label
| 'break'
| 'goto' NAME
| 'do' block 'end'
| 'while' exp 'do' block 'end'
| 'repeat' block 'until' exp
| 'if' exp 'then' block ('elseif' exp 'then' block)* ('else' block)? 'end'
| 'for' NAME '=' exp ',' exp (',' exp)? 'do' block 'end'
| 'for' namelist 'in' explist 'do' block 'end'
| 'function' funcname funcbody
| 'local' 'function' NAME funcbody
| 'local' attnamelist ('=' explist)?
;
attnamelist
: NAME attrib (',' NAME attrib)*
;如上語法中,整個文件被表示成一個chunk,chunk表示為一個block和一個文件結束符(EOF);block又被表示為一系列的語句的集合,而每一種語句又有特定的語法結構,包含了特定的表達式、關鍵字、變量、常量等信息,然后遞歸表達式的文法組成,變量的寫法等,最終全部都歸結到Lexer(Token)上,遞歸樹結束。
上面其實已經可以看到Antlr4規則的寫法,下面介紹一部分比較重要的規則的寫法。
首先,如2.2.1節的代碼所示,stat可以有非常多的類型,例如變量定義、函數定義、if、while等,這些都沒有進行區分,這樣解析出來語法樹時,會很不清晰,需要結合很多的標記完成具體語句的識別,這種情況下,我們可以結合替代標簽完成區分,如下代碼:
stat
: ';'
| varlist '=' explist #varListStat
| functioncall #functionCallStat
| label #labelStat
| 'break' #breakStat
| 'goto' NAME #gotoStat
| 'do' block 'end' #doStat
| 'while' exp 'do' block 'end' #whileStat
| 'repeat' block 'until' exp #repeatStat
| 'if' exp 'then' block ('elseif' exp 'then' block)* ('else' block)? 'end' #ifStat
| 'for' NAME '=' exp ',' exp (',' exp)? 'do' block 'end' #forStat
| 'for' namelist 'in' explist 'do' block 'end' #forInStat
| 'function' funcname funcbody #functionDefStat
| 'local' 'function' NAME funcbody #localFunctionDefStat
| 'local' attnamelist ('=' explist)? #localVarListStat
;通過在語句后面,添加 #替代標簽,可以將語句轉換為這些替代標簽,從而加以區分。
默認情況下,ANTLR從左到右結合運算符,然而某些像指數群這樣的運算符則是從右到左。可以使用選項assoc手動指定運算符記號上的相關性。如下面的操作:
expr : expr '^'<assoc=right> expr
^ 表示指數運算,增加 assoc=right,表示該運算符是右結合。
實際上,Antlr4 已經對一些常用的操作符的優先級進行了處理,例如加減乘除等,這些就不需要再特殊處理。
很多信息,例如注釋、空格等,是結果信息生成不需要處理的,但是我們又不適合直接丟棄,安全地忽略掉注釋和空格的方法是把這些發送給語法分析器的記號放到一個“隱藏通道”中,語法分析器僅需要調協到單個通道即可。我們可以把任何我們想要的東西傳遞到其它通道中。在Lua.g4中,這類信息的處理如下:
COMMENT
: '--[' NESTED_STR ']' -> channel(HIDDEN)
;
LINE_COMMENT
: '--'
( // --
| '[' '='* // --[==
| '[' '='* ~('='|'['|'\r'|'\n') ~('\r'|'\n')* // --[==AA
| ~('['|'\r'|'\n') ~('\r'|'\n')* // --AAA
) ('\r\n'|'\r'|'\n'|EOF)
-> channel(HIDDEN)
;
WS
: [ \t\u000C\r\n]+ -> skip
;
SHEBANG
: '#' '!' ~('\n'|'\r')* -> channel(HIDDEN)
;放到 channel(HIDDEN) 中的 Token,不會被語法解析階段處理,但是可以通過Token遍歷獲取到。
Antlr4采用BNF范式,用’|’表示分支選項,’*’表示匹配前一個匹配項0次或者多次,’+’ 表示匹配前一個匹配項至少一次。下面介紹幾種常見的詞法舉例(均來自Lua.g4文件):
1) 注釋信息
COMMENT
: '--[' NESTED_STR ']' -> channel(HIDDEN)
;
LINE_COMMENT
: '--'
( // --
| '[' '='* // --[==
| '[' '='* ~('='|'['|'\r'|'\n') ~('\r'|'\n')* // --[==AA
| ~('['|'\r'|'\n') ~('\r'|'\n')* // --AAA
) ('\r\n'|'\r'|'\n'|EOF)
-> channel(HIDDEN)
;2) 數字
INT : Digit+ ; Digit : [0-9] ;
3) ID(命名)
NAME : [a-zA-Z_][a-zA-Z_0-9]* ;
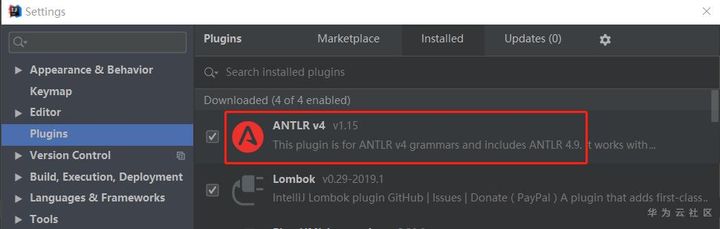
如果要安裝Antlr4,選擇 File -> Settings -> Plugins,然后在搜索框搜索 Antlr安裝即可,可以選擇安裝搜索出來的最新版本,下圖是剛剛安裝的ANTLR v4,版本是v1.15,支持最新的Antlr 4.9版本。
基于IDEA調試Antlr4語法一般步驟:
1) 創建一個調試工程,并創建一個g4文件
這里,我自己測試用Java開發,所以創建的是一個Maven工程,g4文件放在了src/main/resources 目錄下,取名 Test.g4
2)寫一個簡單的語法結構
這里我們參考寫一個加減乘除操作的表達式,然后在賦值操作對應的Rule上右鍵,可選擇測試:
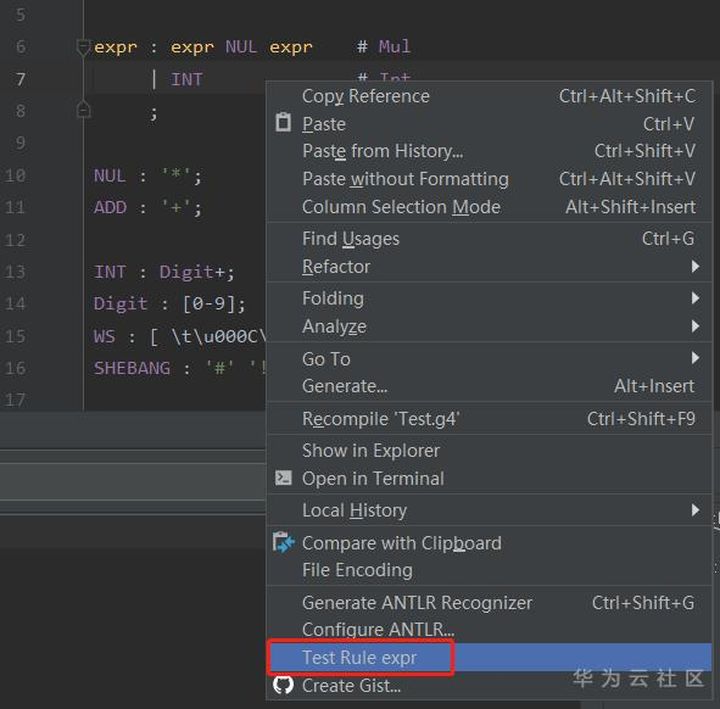
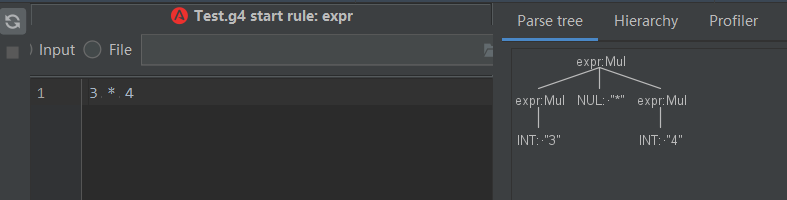
如上圖,expr 表示的是一個乘法操作,所以我們如下測試:
但是,如果改成一個加法操作,則無法識別,只能識別到第一個數字。
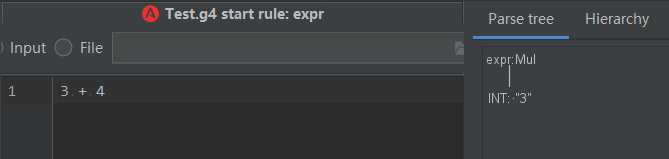
這種情況下,就需要繼續擴充 expr的定義,豐富不同的語法,來繼續支持其他的語法,如下:
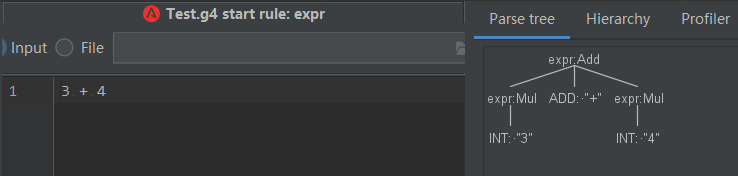
還可以繼續擴充其他類型的支持,這樣一步步將整個語言的語法都支持完整。這里,我們形成的一個完整的格式如下(表示整形數字的加減乘除):
grammar Test;
@header {
package zmj.test.antlr4.parser;
}
stmt : expr;
expr : expr NUL expr # Mul
| expr ADD expr # Add
| expr DIV expr # Div
| expr MIN expr # Min
| INT # Int
;
NUL : '*';
ADD : '+';
DIV : '/';
MIN : '-';
INT : Digit+;
Digit : [0-9];
WS : [ \t\u000C\r\n]+ -> skip;
SHEBANG : '#' '!' ~('\n'|'\r')* -> channel(HIDDEN);這一步介紹兩種生成解析語法樹的兩種方法,供參考:
Maven Antlr4插件自動生成(針對Java工程,也可以用于Gradle)
pom.xml設置Antlr4 Maven插件,可以通過執行 mvn generate-sources自動生成需要的代碼(參考鏈接: https://www.antlr.org/api/maven-plugin/latest/antlr4-mojo.html,主要的意義在于,代碼入庫的時候,不需要再將生成的這些語法文件入庫,減少庫里面的代碼冗余,只包含自己開發的代碼,不會有自動生成的代碼,也不需要做clean code整改),下面是一個示例:
<build>
<plugins>
<plugin>
<groupId>org.antlr</groupId>
<artifactId>antlr4-maven-plugin</artifactId>
<version>4.3</version>
<executions>
<execution>
<id>antlr</id>
<goals>
<goal>antlr4</goal>
</goals>
<phase>generate-sources</phase>
</execution>
</executions>
<configuration>
<sourceDirectory>${basedir}/src/main/resources</sourceDirectory>
<outputDirectory>${project.build.directory}/generated-sources/antlr4/zmj/test/antlr4/parser</outputDirectory>
<listener>true</listener>
<visitor>true</visitor>
<treatWarningsAsErrors>true</treatWarningsAsErrors>
</configuration>
</plugin>
</plugins>
</build>按照上面設置后,只需要執行 mvn generate-sources 即可在maven工程中自動生成代碼。
命令行方式
主要參考鏈接(https://www.antlr.org/download.html),有每種語言的語法配置,我們這里考慮下載Antlr4完整jar:

下載好后(antlr-4.9-complete.jar),可以使用如下命令來生成需要的信息:
java -jar antlr-4.9-complete.jar -Dlanguage=Python3 -visitor Test.g4
這樣就可以生成Python3 target的源碼,支持的源碼可以從上面鏈接查看,如果不希望生成Listener,可以添加參數 -no-listener
Antlr4在AST遍歷時,支持兩種設計模式:訪問者設計模式 和 監聽器模式。
對于 訪問者設計模式,我們需要自己定義對 AST 的訪問(https://xie.infoq.cn/article/5f80da3c014fd69f8dbe09b28,這是一篇針對訪問者設計模式的介紹,大家可以參考)。下面直接通過代碼展示訪問者模式在Antlr4中使用(基于第3章的例子):
import org.antlr.v4.runtime.CharStream;
import org.antlr.v4.runtime.CharStreams;
import org.antlr.v4.runtime.CommonTokenStream;
import zmj.test.antlr4.parser.TestBaseVisitor;
import zmj.test.antlr4.parser.TestLexer;
import zmj.test.antlr4.parser.TestParser;
public class App {
public static void main(String[] args) {
CharStream input = CharStreams.fromString("12*2+12");
TestLexer lexer=new TestLexer(input);
CommonTokenStream tokens = new CommonTokenStream(lexer);
TestParser parser = new TestParser(tokens);
TestParser.ExprContext tree = parser.expr();
TestVisitor tv = new TestVisitor();
tv.visit(tree);
}
static class TestVisitor extends TestBaseVisitor<Void> {
@Override
public Void visitAdd(TestParser.AddContext ctx) {
System.out.println("========= test add");
System.out.println("first arg: " + ctx.expr(0).getText());
System.out.println("second arg: " + ctx.expr(1).getText());
return super.visitAdd(ctx);
}
}
}如上,main方法中,解析出了表達式的AST結構,同時在源碼中也定義了一個Visitor:TestVisitor,訪問AddContext,并且打印該加表達式的前后兩個表達式,上面例子的輸出為:
========= test add first arg: 12*2 second arg: 12
對于監聽器模式,就是通過監聽某對象,如果該對象上有特定的事件發生,則觸發該監聽行為執行。比如有個監控(監聽器),監控的是大門(事件對象),如果發生了闖門的行為(事件源),則進行報警(觸發操作行為)。
在Antlr4中,如果使用監聽器模式,首先需要開發一個監聽器,該監聽器可以監聽每個AST節點(例如表達式、語句等)的不同的行為(例如進入該節點、結束該節點)。在使用時,Antlr4會對生成的AST進行遍歷(ParseTreeWalker),如果遍歷到某個具體的節點,并且執行了特定行為,就會觸發監聽器的事件。
監聽器方法是沒有返回值的(即返回類型是void)。因此需要一種額外的數據結構(可以通過Map或者棧)來存儲當次的計算結果,供下一次計算調用。
一般來說,面向程序靜態分析時,都是使用訪問者模式的,很少使用監聽器模式(無法主動控制遍歷AST的順序,不方便在不同節點遍歷之間傳遞數據),用法對咱們也不友好,所以本文不介紹監聽器模式,如果有興趣,可以自己搜索測試使用。
這部分實際上,算是Antlr4最基礎的內容,但是放到最后一部分來講,有特定的目的,就是探討一下詞法解析和語法解析的界限,以及Antlr4的結果的處理。
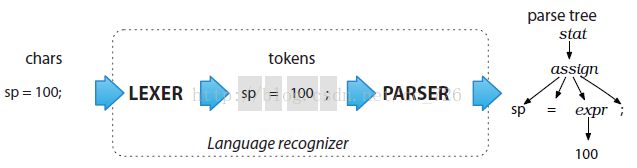
如前面的語法定義,分為Lexer和Parser,實際上表示了兩個不同的階段:
詞法分析階段:對應于Lexer定義的詞法規則,解析結果為一個一個的Token;
解析階段:根據詞法,構造出來一棵解析樹或者語法樹。
如下圖所示:
首先,我們應該有個普遍的認知:語法解析相對于詞法解析,會產生更多的開銷,所以,應該盡量將某些可能的處理在詞法解析階段完成,減少語法解析階段的開銷,主要下面的這些例子:
合并語言不關心的標記,例如,某些語言(例如js)不區分int、double,只有 number,那么在詞法解析階段,就不需要將int和double區分開,統一合并為一個number;
空格、注釋等信息,對于語法解析并無大的幫助,可以在詞法分析階段剔除掉;
諸如標志符、關鍵字、字符串和數字這樣的常用記號,均應該在詞法解析時完成,而不要到語法解析階段再進行。
但是,這樣的操作在節省了語法分析的開銷之外,其實對我們也產生了一些影響:
雖然語言不區分類型,例如只有 number,沒有 int 和 double 等,但是面向靜態代碼分析,我們可能需要知道確切的類型來幫助分析特定的缺陷;
雖然注釋對代碼幫助不大,但是我們有時候也需要解析注釋的內容來進行分析,如果無法在語法解析的時候獲取,那么就需要遍歷Token,從而導致靜態代碼分析開銷更大等;
…
這樣的一些問題該如何處理呢?
大部分的資料中,都把Antlr4生成的樹狀結構,稱為解析樹或者是語法樹,但是,如果我們細究的話,可能說成是解析樹更加準確,因為Antlr4的結果,只是簡單的文法解析,不能稱之為語法樹(語法樹應該是能夠體現出來語法特性的信息),如上面的那些問題,就很難在Antlr4生成的解析樹上獲取到。
所以,現在很多工具,基于Antlr4進行封裝,然后進行了更進一步地處理,從而獲取到了更加豐富的語法樹,例如CheckStyle。因此,如果通過Antlr4解析語言簡單使用,可以直接基于Antlr4的結果開發,但是如果要進行更加深入的處理,就需要對Antlr4的結果進行更進一步的處理,以更符合我們的使用習慣(例如,Java Parser格式的Java的AST,Clang格式的C/C++的AST),然后才能更好地在上面進行開發。
到此,相信大家對“什么是Antlr4”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





