溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關如果vsan主機發生故障會怎么樣的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
如果vsan主機發生故障,會如何呢?我們再來看看下面這幅圖: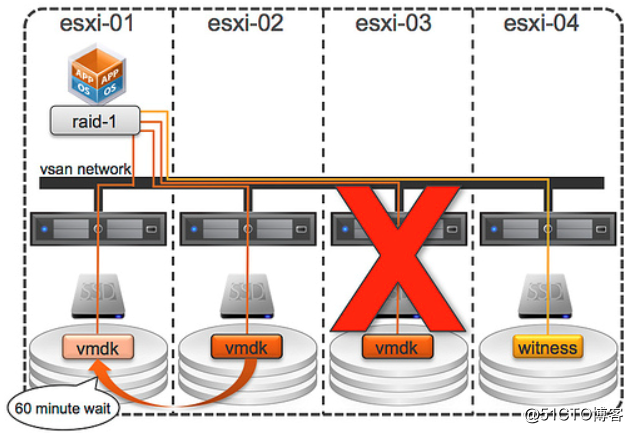
這種情況與“磁盤故障”稍有不同。發生磁盤故障時,VSAN 會注意到所發生的情況,它會注意到磁盤無法恢復,會觸發組件重構。但發生主機故障時,VSAN 不會注意到所發生的情況。這種故障狀態稱為“不存在”。一旦 VSAN 注意到組件(在上述示例中為 VMDK)不存在,計時器就會開始 60 分鐘計時。如果組件在 60 分鐘內恢復,VSAN就會同步鏡像副本。如果組件無法恢復,則 VSAN 就會創建新的鏡像副本。請注意,您可以通過更改高級設置“VSAN.ClomRepairDelay”來減少此超時值。
如果原先故障的主機恢復并重新加入了群集,VSAN會檢查對象重構狀態。如果對象已經在其他一個或多個節點上完成了重構,就不會有其他動作。如果對象重構仍在進行中,原先故障主機的組件仍將被重新同步,以防新的組件會出現問題。當所有對象同步完成,原先主機的組件會被丟棄,而新創建的副本會被啟用。不過,如果新組件因為某種原因無法完成同步,那么原先主機上原來的組件會被繼續使用。
注:當主機發生了故障,其上運行的所有虛擬機會被VSPHERE HA重啟。vsphere ha可能會在群集中任何可用的主機上重啟虛擬機,而不管這些主機是否擁有VSAN組件。
補充優化資料:(來自https://blog.51cto.com/roberthu/2049330)
vsan6.2高級參數優化
esxcfg-advcfg -s 1024 /LSOM/heapSize
esxcfg-advcfg -s 180 /VSAN/ClomMaxComponentSizeGB
esxcfg-advcfg -s 512 /LSOM/blPLOGCacheLines 默認值為 128 K,增加至 512 K
esxcfg-advcfg -s 32 /LSOM/blLLOGCacheLines 默認值為 128,增加至 32 K
該參數必須在主機正式部署虛擬機前完成修改
附錄學習:
擁堵表明的含義
擁堵是一種反饋機制,它反映了從 vSAN DOM 客戶端層傳入 vSAN 磁盤組所服務的級別的入站 IO 請求速率降低。這種入站 IO 請求速率降低的行為是由 IO 延遲引起的,而底層的瓶頸會導致發生 IO 延遲。因此,一個有效的方法是,將滯后時間從底層轉移到輸入流量,而無需更改系統的總吞吐量。這可避免在 vSAN LSOM 層中出現不必要的排隊以及尾丟隊列,于是避免了在處理最終可能丟棄的 IO 請求時浪費大量的 CPU 周期。因此,無論何種類型的擁堵,臨時和較小的擁堵值通常沒問題,但對系統性能無益。不過,持續和較大的擁堵值可能會導致滯后時間延長和吞吐量降低的程度超出預期,因此應進行關注并解決以提高基準性能。
擁堵的報告方式
vSAN 衡量并以介于 0 至 255 之間的標量值報告擁堵。引入的 IO 延遲會隨擁堵值的增加呈指數增長。
處理擁堵的可行方法
檢查擁堵是否持續且居高不下 (> 50)。許多情況下,高擁堵值是系統配置錯誤或系統性能不佳造成的。如果一直呈現高擁堵值,請檢查以下項:
1.IO 控制器和設備中支持的最大隊列深度。支持的最大隊列深度低于 100 可能會導致問題。請檢查控制器是否已經過認證并列在 vSAN HCL 列表中。
2.固件或設備驅動程序軟件的不正確版本。請參考 VMware HCL,了解 vSAN 兼容的軟件。
3.不正確的大小設置。緩存層磁盤和內存的大小設置不正確可能會導致擁堵值較高。
如果問題不是上述任何狀況,必須進行調試,確定是否可以更好地調整基準,以減少擁堵。您必須注意,是:
4.所有磁盤組都出現擁堵,還是
5.一個或兩個磁盤組的擁堵值異常高于其他磁盤組。
對于情況 (1),很有可能 vSAN 群集后端無法處理 IO 工作負載。如果可能,可以通過以下方法調整基準:
6.關閉某些虛擬機或
7.減少每個虛擬機中的未完成 IO/線程數,或者
8.對于寫入工作負載,減小工作集的大小。
對于情況 (2),即,一個磁盤組上的擁堵遠遠高于系統中的其他磁盤組,這表明磁盤組間的寫入 IO 活動不平衡。如果持續發生這種情況,請嘗試增加用于創建虛擬機磁盤的 vSAN 存儲策略中的磁盤帶數。
報告的常見擁堵類型以及解決方法
下面列出了擁堵類型和每種類型的補救措施:
9.SSD 擁堵:特定磁盤組的寫入 IO 的活動工作集顯著大于該磁盤組緩存層的大小時,通常會引發 SSD 擁堵。在混合和全閃存 vSAN 群集中,數據首先寫入到寫入緩存(也稱為寫入緩沖區)。一個稱為降級轉儲的進程會將數據從寫入緩沖區移至容量磁盤。寫入緩存承受較高的寫入速率,從而確保寫入性能不受容量磁盤的限制。不過,如果基準以非常快的速率填充寫入緩存,降級轉儲進程可能跟不上到達 IO 速率。在這種情況下,會引發 SSD 擁堵,以指示 vSAN DOM 客戶端層將 IO 減速到 vSAN 磁盤組可以處理的速率。
補救措施:要避免 SSD 擁堵,請調整基準所用的虛擬機磁盤的大小。為達到最佳效果,我們建議虛擬機磁盤(活動工作集)的大小不超過所有磁盤組寫入緩存累計大小的 40%。請注意,對于混合 vSAN 群集,寫入緩存的大小為緩存層磁盤大小的 30%。在全閃存群集中,寫入緩存的大小是緩存層磁盤的大小,但不應超過 600 GB。
2.日志擁堵:vSAN LSOM 日志(存儲未降級轉儲的 IO 操作的元數據)消耗寫入緩存中的大量空間時,通常會引發日志擁堵。
通常情況下,小工作集上的大量小規模寫入會導致出現大量 vSAN LSOM 日志條目,于是會導致出現這種類型的擁堵。此外,如果基準不發出 4K 對齊 IO,則 vSAN 堆棧上的 IO 數將增加,從而引發 4K 對齊。IO 數增加可能會導致日志擁堵。
補救措施:檢查基準是否與 4K 邊界上的 IO 請求一致。如果不一致,請檢查基準是否使用一個非常小的工作集(訪問虛擬機磁盤的總大小低于緩存層大小的 10% 時,則認為工作集較小。請參見上文有關如何計算緩存層大小的內容)。如果是,請將工作集增加到緩存層大小的 40%。如果以上兩個條件都不成立,將需要通過以下兩種方法減少寫入流量:減少基準發出的未完成 IO 數或減少基準創建的虛擬機數量。
3.組件擁堵:這種擁堵表明,由于某些組件的 IO 請求排入隊列,致使這些組件存在大量的未完成提交操作。這可能會導致延長滯后時間。通常情況下,幾個虛擬機磁盤的大量寫入會導致出現這種擁堵。
補救措施:增加基準所用的虛擬機磁盤數。確保基準不向少量虛擬機磁盤發出 IO。
4.內存和 Slab 擁堵:內存和 slab 擁堵通常意味著 vSAN LSOM 層所用的堆內存空間或 slab 空間不足,無法維持其內部數據結構。vSAN 會為內部操作置備一定量的系統內存。但是,如果基準積極地發出 IO,而沒有任何限制,則可能會導致 vSAN 用光所有為其分配的內存空間。
補救措施:減小基準的工作集。或者,在體驗基準時提高以下設置以增加為 vSAN LSOM 層預留的內存量。請注意,這些設置是針對每個磁盤組的。此外,我們不建議在生產群集上使用這些設置。可以通過 esxcli 更改這些設置(請參見 知識庫文章 1038578),如下所示:
/LSOM/blPLOGCacheLines,默認值為 128 K,增加至 512 K
/LSOM/blPLOGLsnCacheLines,默認值為 4 K,調整為 32 K
/LSOM/blLLOGCacheLines,默認值為 128,增加至 32 K
感謝各位的閱讀!關于“如果vsan主機發生故障會怎么樣”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





