溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么正確設計一個訂單號”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!
我們經常提及到的訂單號,大多數是在電商購物場景下的一個唯一標識字符串。實則訂單號并不僅僅指的是電商系統,只要需要這樣的業務場景,我們都可以使用訂單號的模式來處理。例如我們的省份證號,要求唯一可讀性強等特點,也可以將之理解為一個訂單號。
1.不重復。不管你的訂單號設計的是多復雜還是多簡單,首先我們需要確保的是訂單號在一個系統中是唯一的。
2.安全性。訂單號需要做到不容易被人為的猜測或者推測出來。例如訂單號包含系統的流水信息,用戶信息等保密相關的信息。
3.禁用隨機碼。隨機碼從一定程度來說,更安全、不重復性更高,但是可讀性差。例如生成類似這樣的隨機碼(sdfsad12312sfsdf201),不管是從系統角度還是從人為角度去讀取,完全沒法直接辨別。
4.防止并發。針對系統的并發業務場景(如秒殺),一定需要做到并發場景下,訂單編號生成快速、不重復等要求。
5.控制位數。訂單號的位數盡量在 10 位-20 位之間。太短的情況下,如果交易量過大,很難做到防止重復,太長可讀性差、意義也不大。
6.盡量使用數字。從軟件角度,數字存儲的訂單號,占用空間小、檢索快。
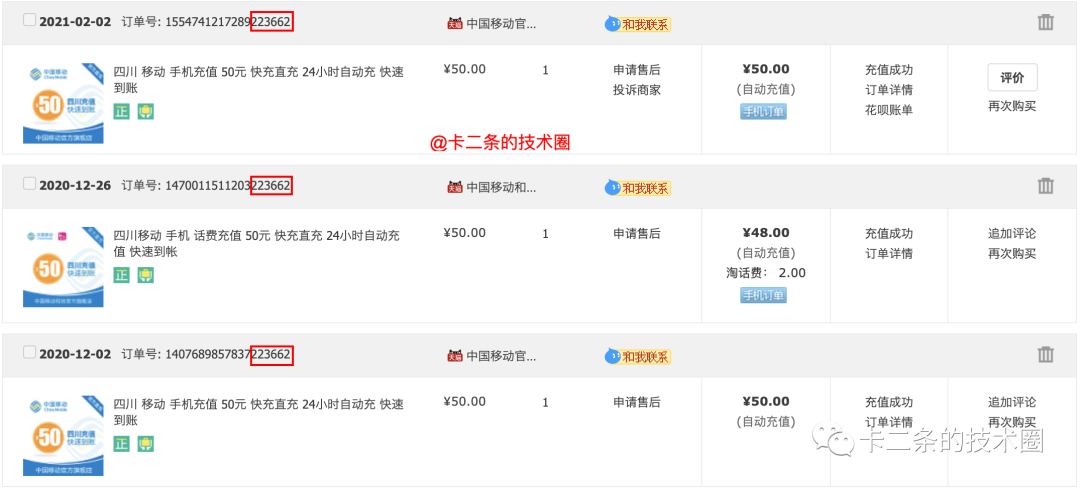
上面的截圖,是個人在淘寶上面進行充值的訂單編號,這里只截取了幾個。在實際的過程中,發現所有訂單號都有一個相似的特點(紅色框出來的地方)。個人猜測,這應該是和買家相關的信息,例如買家的 ID 編號情況。
下面的的幾個規則,是淘寶訂單編號生成的規則(只具備參考意義,與實際存在差距)。
1.總共 18 位。
2.前 14 位為序號。
3.15-16 位賣家 ID 的倒數 1-2 位。。
4.17-18 位買家 ID 的倒數 3-4 位。
上面的幾個規則具備一定的參考意義。從第 3 和 4 點,我們不難分析出來,通過這樣的方式來實現訂單號,在一定程度很難出現重復的訂單編號。那是為什么呢?
1.賣家的 ID 和買家 ID 的都是在下單之前生成的,具備唯一性。因為這兩個 ID 事先生成,即使出現并發場景,通過這兩組的唯一標識就很難生成重復的單號。
2.很大程度上滿足了一些并發高的業務場景下,單號重復的情況。或許你會考慮像雙十一這樣的場景下,實則絕大部分系統都無法達到這樣的業務場景。
前面提到了生成的規則,那要實現這樣的規則,該如何實現會比較好呢?下面總結幾種常見的處理方式。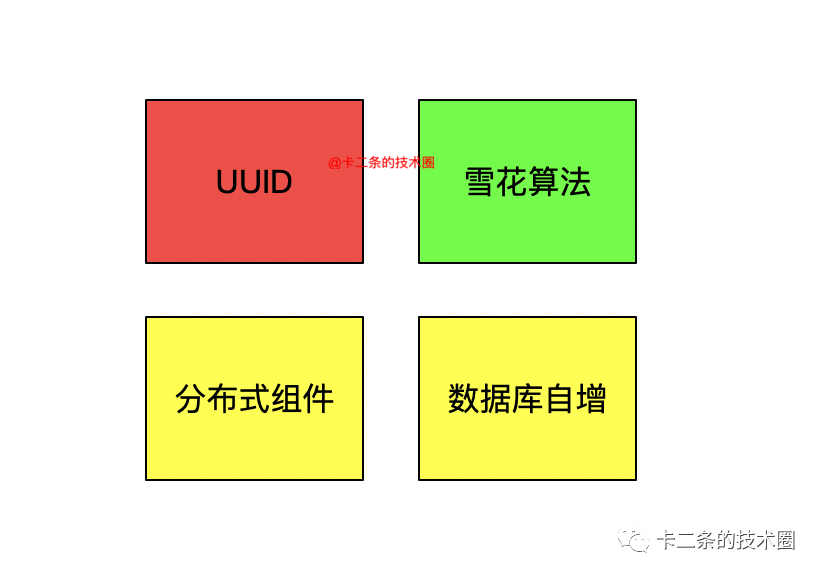
UUID 是 Universally Unique Indentifier 的縮寫,翻譯為通用唯一識別碼,顧名思義 UUID 是一個用于唯一標識一條數據、記錄的,其按照開放軟件基金會(OSF)指定的標準進行計算,用到了以太網卡地址(MAC)、納秒級時間、芯片 ID 碼和許多可能的數字。
總的來說,UUID 碼由以下三部分組成:
1.當前日期和時間。
2.時鐘序列。
3.全局唯一的 IEEE 機器識別碼(如何有網卡,從網卡獲得,沒有網卡則以其他方式獲得)。
UUID 的標準形式包含 32 個 16 進制數字,以連字號分為五段,形式為 8-4-4-4-12 的 32 個字符。示例:550e8400-e29b-41d4-a716-446655440000。關于 UUID 的更多介紹,可以參考該文章
Snowflake 是 Twitter 內部的一個 ID 生算法,可以通過一些簡單的規則保證在大規模分布式情況下生成唯一的 ID 號碼。其組成為:
第一個 bit 為未使用的符號位。
第二部分由 41 位的時間戳(毫秒)構成,它的取值是當前時間相對于某一時間的偏移量。
第三部分和第四部分的 5 個 bit 位表示數據中心和機器 ID,其能表示的最大值為 2^5 -1 = 31。
最后部分由 12 個 bit 組成,其表示每個工作節點每毫秒生成的序列號 ID,同一毫秒內最多可生成 2^12 -1 即 4095 個 ID。
需要注意的是:
在分布式環境中,5 個 bit 位的 datacenter 和 worker 表示最多能部署 31 個數據中心,每個數據中心最多可部署 31 臺節點。
41 位的二進制長度最多能表示 2^41 -1 毫秒即 69 年,所以雪花算法最多能正常使用 69 年,為了能最大限度的使用該算法,你應該為其指定一個開始時間。
在數據庫中可以通過給訂單列設置為自增列,并且給該列設置一個初始值。這樣通過數據庫實現訂單的自增、無重復情況。但通過數據庫實現并發能力低,單表存在只能有一個自增列的情況,后期對數據的分表處理也不夠友好。
通過分布式組件的方式,我們也可以實現訂單號的處理。例如使用 Redis 作為分布式組件。通過 Redis 的隊列、incr 等功能來實現。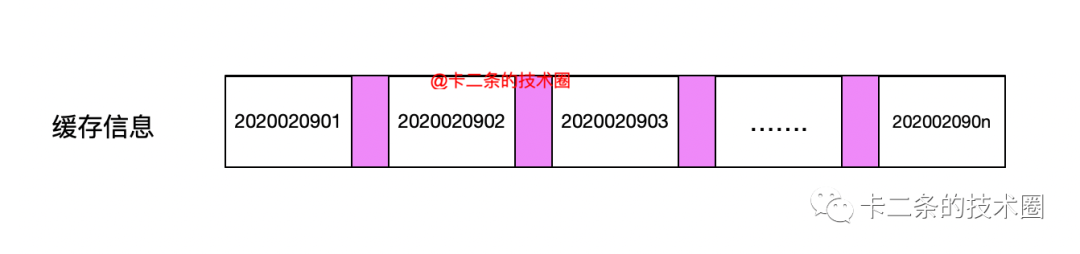
// 生成方式一
function uuid($prefix = '') {
$chars = md5(uniqid(mt_rand(), true));
$uuid = substr($chars,0,8) . '-';
$uuid .= substr($chars,8,4) . '-';
$uuid .= substr($chars,12,4) . '-';
$uuid .= substr($chars,16,4) . '-';
$uuid .= substr($chars,20,12);
return $prefix . $uuid;
}
echo uuid();
// output
// b2fa188c-23a8-d1b6-432d-649db4eb34c7
// 生成方式二(利用Linux內部生成的uuid)
echo exec("cat /proc/sys/kernel/random/uuid");
// output
// b2792783-7c9f-43d0-8d31-38411e17fc2f
// 生成方式三
function uniqidReal($lenght = 13) {
if (function_exists("random_bytes")) {
try {
$bytes = random_bytes(ceil($lenght / 2));
} catch (Exception $e) {
}
} elseif (function_exists("openssl_random_pseudo_bytes")) {
$bytes = openssl_random_pseudo_bytes(ceil($lenght / 2));
} else {
throw new Exception("no cryptographically secure random function available");
}
return substr(bin2hex($bytes), 0, $lenght);
}
echo uniqidReal();
// output
// 9f39aa0ecd89d
require_once __DIR__.'/vendor/autoload.php';
$snowflake = new \Godruoyi\Snowflake\Snowflake;
echo $snowflake->id();
// output
// 199778615951360000
// 更多高級用法及實現原理參考原倉庫:https://github.com/godruoyi/php-snowflake/blob/master/README-zh_CN.md
// 連接Redis
$redis = new \Redis();
$redis->connect('192.168.0.112', 6379);
$cacheKey = date('Y:m:d');
$initVal = 10000;
// 實現方式一(使用隊列)
for ($i = 0; $i < 10; $i++) {
$redis->lPush($cacheKey, $initVal + $i);
}
$redis->rPop($cacheKey);
// 實現方式二(使用incr)
if ($redis->get($cacheKey)) {
// 返回新增后的值
return $redis->incr($cacheKey);
} else {
// 設置一個默認的初始值
$redis->set($cacheKey, $initVal);
return $cacheKey;
}
數據庫直接就不演示,直接通過設置表字段屬性就行。主要設置字段值的初始值、偏移量。
mysql root@127.0.0.1:(none)> show variables like '%auto_incr%';
+--------------------------+-------+
| Variable_name | Value |
+--------------------------+-------+
| auto_increment_increment | 1 |
| auto_increment_offset | 1 |
+--------------------------+-------+
2 rows in set
Time: 0.012s
通過上面的示例演示,下面針對這幾種情況做一個分析與總結。盡可能的選擇一種合理的方式。
| 實現方案 | 優勢 | 劣勢 |
|---|---|---|
| UUID | 實現簡單、方便;重復性低;數據庫查詢效率低 | 可讀性低;過于冗長 |
| 雪花算法 | 基于內存、速度快;性能高;不會產生額外的網絡開銷;數據依次成遞增 | 依賴于服務器時間,如變動服務器時間則存在重復的情況 |
| Redis | 基于內存、速度庫;使用簡單;可分布數據、擴展性強 | 需要獨立搭建一套服務、增加了維護成本;跨應用調用、存在網絡開銷 |
| 數據庫自增 | 代碼層面無需任何特殊處理;利用MySQL特點實現數據遞增 | 并發性能差;MySQL負擔重 |
“怎么正確設計一個訂單號”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





