溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹了Flink容器化環境下OOM Killed是什么,具有一定借鑒價值,感興趣的朋友可以參考下,希望大家閱讀完這篇文章之后大有收獲,下面讓小編帶著大家一起了解一下。
對于大多數 Java 用戶而言,日常開發中與 JVM Heap 打交道的頻率遠大于其他 JVM 內存分區,因此常把其他內存分區統稱為 Off-Heap 內存。而對于 Flink 來說,內存超標問題通常來自 Off-Heap 內存,因此對 JVM 內存模型有更深入的理解是十分必要的。
根據 JVM 8 Spec[1],JVM 管理的內存分區如下圖:
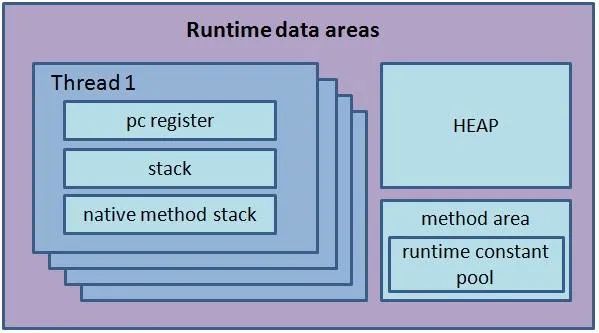
JVM 8 內存模型
除了上述 Spec 規定的標準分區,在具體實現上 JVM 常常還會加入一些額外的分區供進階功能模塊使用。以 HotSopt JVM 為例,根據 Oracle NMT[5] 的標準,我們可以將 JVM 內存細分為如下區域:
Heap: 各線程共享的內存區域,主要存放 new 操作符創建的對象,內存的釋放由 GC 管理,可被用戶代碼或 JVM 本身使用。
Class: 類的元數據,對應 Spec 中的 Method Area (不含 Constant Pool),Java 8 中的 Metaspace。
Thread: 線程級別的內存區,對應 Spec 中的 PC Register、Stack 和 Natvive Stack 三者的總和。
Compiler: JIT (Just-In-Time) 編譯器使用的內存。
Code Cache: 用于存儲 JIT 編譯器生成的代碼的緩存。
GC: 垃圾回收器使用的內存。
Symbol: 存儲 Symbol (比如字段名、方法簽名、Interned String) 的內存,對應 Spec 中的 Constant Pool。
Arena Chunk: JVM 申請操作系統內存的臨時緩存區。
NMT: NMT 自己使用的內存。
Internal: 其他不符合上述分類的內存,包括用戶代碼申請的 Native/Direct 內存。
Unknown: 無法分類的內存。
理想情況下,我們可以嚴格控制各分區內存的上限,來保證進程總體內存在容器限額之內。但是過于嚴格的管理會帶來會有額外使用成本且缺乏靈活度,所以在實際中為了 JVM 只對其中幾個暴露給用戶使用的分區提供了硬性的上限,而其他分區則可以作為整體被視為 JVM 本身的內存消耗。
具體可以用于限制分區內存的 JVM 參數如下表所示(值得注意的是,業界對于 JVM Native 內存并沒有準確的定義,本文的 Native 內存指的是 Off-Heap 內存中非 Direct 的部分,與 Native Non-Direct 可以互換)。
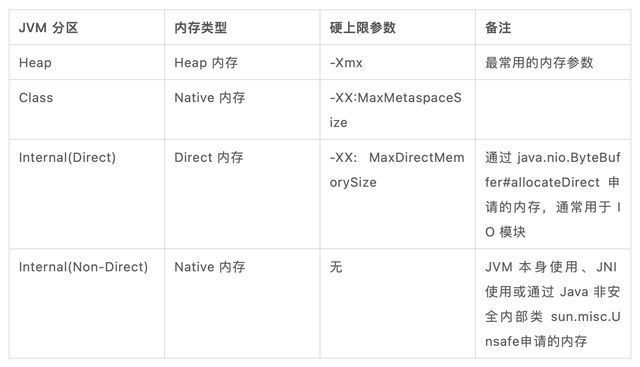
從表中可以看到,使用 Heap、Metaspace 和 Direct 內存都是比較安全的,但非 Direct 的 Native 內存情況則比較復雜,可能是 JVM 本身的一些內部使用(比如下文會提到的 MemberNameTable),也可能是用戶代碼引入的 JNI 依賴,還有可能是用戶代碼自身通過 sun.misc.Unsafe 申請的 Native 內存。理論上講,用戶代碼或第三方 lib 申請的 Native 內存需要用戶來規劃內存用量,而 Internal 的其余部分可以并入 JVM 本身的內存消耗。而實際上 Flink 的內存模型也遵循了類似的原則。
首先回顧下 Flink 1.10+ 的 TaskManager 內存模型。
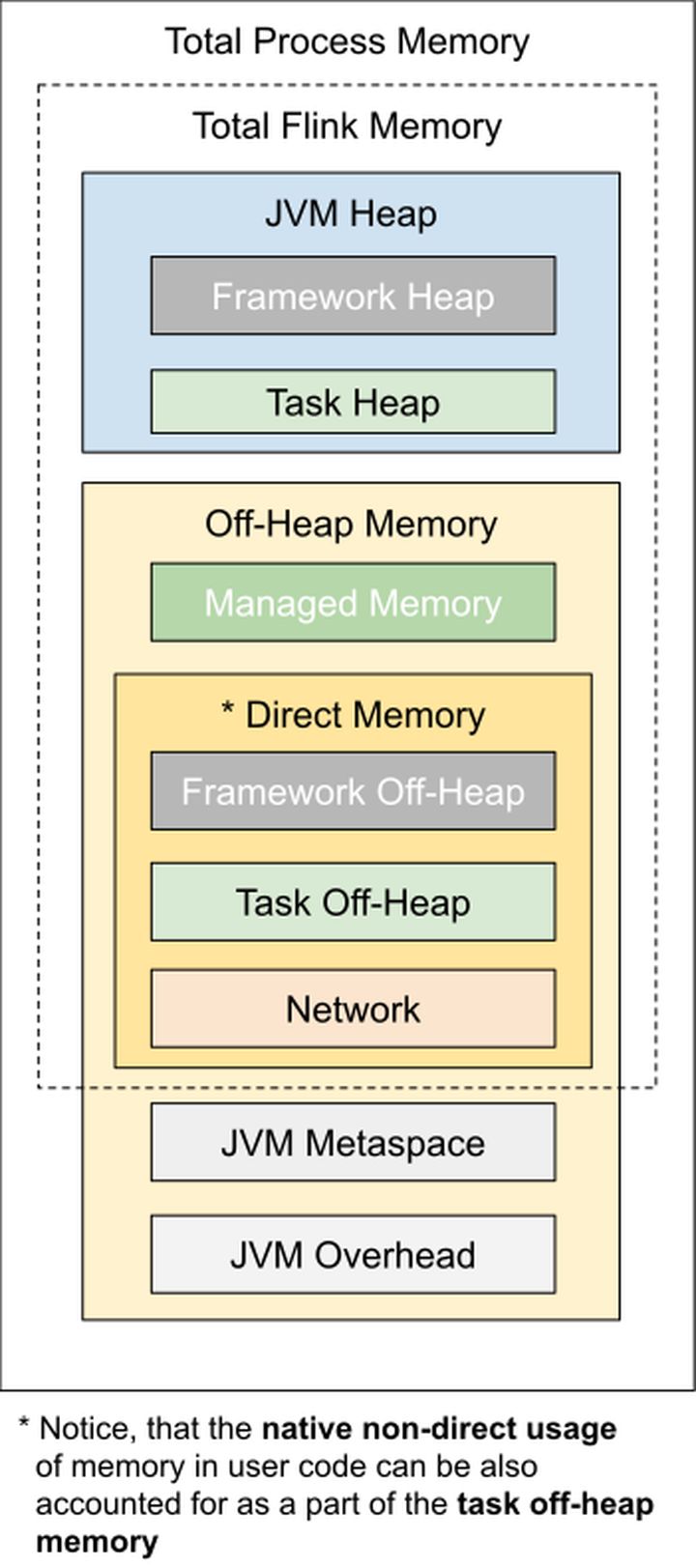
Flink TaskManager 內存模型
顯然,Flink 框架本身不僅會包含 JVM 管理的 Heap 內存,也會申請自己管理 Off-Heap 的 Native 和 Direct 內存。在筆者看來,Flink 對于 Off-Heap 內存的管理策略可以分為三種:
硬限制(Hard Limit): 硬限制的內存分區是 Self-Contained 的,Flink 會保證其用量不會超過設置的閾值(若內存不夠則拋出類似 OOM 的異常)
軟限制(Soft Limit): 軟限制意味著內存使用長期會在閾值以下,但可能短暫地超過配置的閾值。
預留(Reserved): 預留意味著 Flink 不會限制分區內存的使用,只是在規劃內存時預留一部分空間,但不能保證實際使用會不會超額。
結合 JVM 的內存管理來看,一個 Flink 內存分區的內存溢出會導致何種后果,判斷邏輯如下:
1、若是 Flink 有硬限制的分區,Flink 會報該分區內存不足。否則進入下一步。
2、若該分區屬于 JVM 管理的分區,在其實際值增長導致 JVM 分區也內存耗盡時,JVM 會報其所屬的 JVM 分區的 OOM (比如 java.lang.OutOfMemoryError: Jave heap space)。否則進入下一步。
3、該分區內存持續溢出,最終導致進程總體內存超出容器內存限制。在開啟嚴格資源控制的環境下,資源管理器(YARN/k8s 等)會 kill 掉該進程。
為直觀地展示 Flink 各內存分區與 JVM 內存分區間的關系,筆者整理了如下的內存分區映射表:
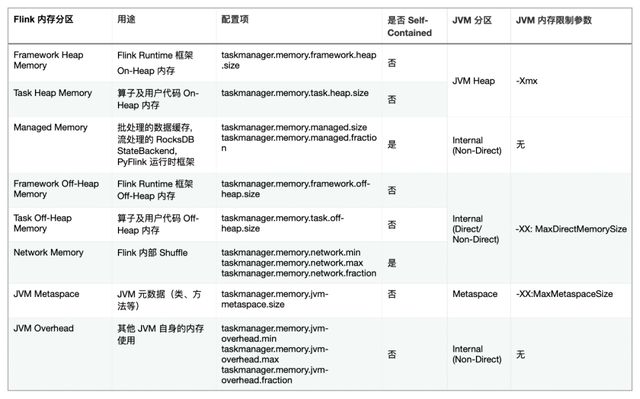
Flink 分區及 JVM 分區內存限制關系
根據之前的邏輯,在所有的 Flink 內存分區中,只有不是 Self-Contained 且所屬 JVM 分區也沒有內存硬限制參數的 JVM Overhead 是有可能導致進程被 OOM kill 掉的。作為一個預留給各種不同用途的內存的大雜燴,JVM Overhead 的確容易出問題,但同時它也可以作為一個兜底的隔離緩沖區,來緩解來自其他區域的內存問題。
舉個例子,Flink 內存模型在計算 Native Non-Direct 內存時有一個 trick:
Although, native non-direct memory usage can be accounted for as a part of the framework off-heap memory or task off-heap memory, it will result in a higher JVM’s direct memory limit in this case.
雖然 Task/Framework 的 Off-Heap 分區中可能含有 Native Non-Direct 內存,而這部分內存嚴格來說屬于 JVM Overhead,不會被 JVM -XX:MaxDirectMemorySize 參數所限制,但 Flink 還是將它算入 MaxDirectMemorySize 中。這部分預留的 Direct 內存配額不會被實際使用,所以可以留給沒有上限 JVM Overhead 占用,達到為 Native Non-Direct 內存預留空間的效果。
與上文分析一致,實踐中導致 OOM Killed 的常見原因基本源于 Native 內存的泄漏或者過度使用。因為虛擬內存的 OOM Killed 通過資源管理器的配置很容易避免且通常不會有太大問題,所以下文只討論物理內存的 OOM Killed。
RocksDB Native 內存的不確定性
眾所周知,RocksDB 通過 JNI 直接申請 Native 內存,并不受 Flink 的管控,所以實際上 Flink 通過設置 RocksDB 的內存參數間接影響其內存使用。然而,目前 Flink 是通過估算得出這些參數,并不是非常精確的值,其中有以下的幾個原因。
首先是部分內存難以準確計算的問題。RocksDB 的內存占用有 4 個部分[6]:
Block Cache: OS PageCache 之上的一層緩存,緩存未壓縮的數據 Block。
Indexes and filter blocks: 索引及布隆過濾器,用于優化讀性能。
Memtable: 類似寫緩存。
Blocks pinned by Iterator: 觸發 RocksDB 遍歷操作(比如遍歷 RocksDBMapState 的所有 key)時,Iterator 在其生命周期內會阻止其引用到的 Block 和 Memtable 被釋放,導致額外的內存占用[10]。
前三個區域的內存都是可配置的,但 Iterator 鎖定的資源則要取決于應用業務使用模式,且沒有提供一個硬限制,因此 Flink 在計算 RocksDB StateBackend 內存時沒有將這部分納入考慮。
其次是 RocksDB Block Cache 的一個 bug[8][9],它會導致 Cache 大小無法嚴格控制,有可能短時間內超出設置的內存容量,相當于軟限制。
對于這個問題,通常我們只要調大 JVM Overhead 的閾值,讓 Flink 預留更多內存即可,因為 RocksDB 的內存超額使用只是暫時的。
glibc Thread Arena 問題
另外一個常見的問題就是 glibc 著名的 64 MB 問題,它可能會導致 JVM 進程的內存使用大幅增長,最終被 YARN kill 掉。
具體來說,JVM 通過 glibc 申請內存,而為了提高內存分配效率和減少內存碎片,glibc 會維護稱為 Arena 的內存池,包括一個共享的 Main Arena 和線程級別的 Thread Arena。當一個線程需要申請內存但 Main Arena 已經被其他線程加鎖時,glibc 會分配一個大約 64 MB (64 位機器)的 Thread Arena 供線程使用。這些 Thread Arena 對于 JVM 是透明的,但會被算進進程的總體虛擬內存(VIRT)和物理內存(RSS)里。
默認情況下,Arena 的最大數目是 cpu 核數 * 8,對于一臺普通的 32 核服務器來說最多占用 16 GB,不可謂不可觀。為了控制總體消耗內存的總量,glibc 提供了環境變量 MALLOC_ARENA_MAX 來限制 Arena 的總量,比如 Hadoop 就默認將這個值設置為 4。然而,這個參數只是一個軟限制,所有 Arena 都被加鎖時,glibc 仍會新建 Thread Arena 來分配內存[11],造成意外的內存使用。
通常來說,這個問題會出現在需要頻繁創建線程的應用里,比如 HDFS Client 會為每個正在寫入的文件新建一個 DataStreamer 線程,所以比較容易遇到 Thread Arena 的問題。如果懷疑你的 Flink 應用遇到這個問題,比較簡單的驗證方法就是看進程的 pmap 是否存在很多大小為 64MB 倍數的連續 anon 段,比如下圖中藍色幾個的 65536 KB 的段就很有可能是 Arena。
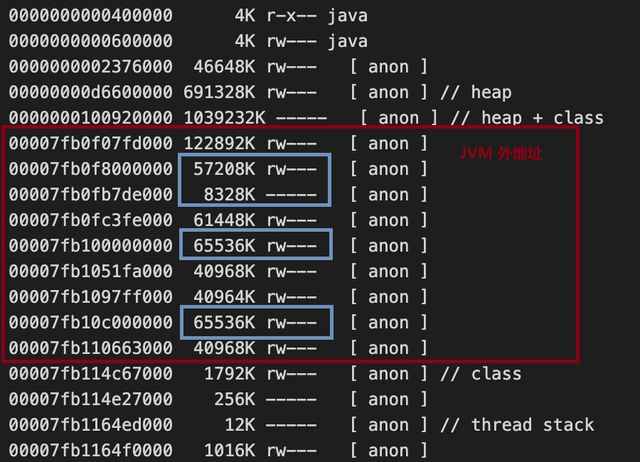
pmap 64 MB arena
這個問題的修復辦法比較簡單,將 MALLOC_ARENA_MAX 設置為 1 即可,也就是禁用 Thread Arena 只使用 Main Arena。當然,這樣的代價就是線程分配內存效率會降低。不過值得一提的是,使用 Flink 的進程環境變量參數(比如 containerized.taskmanager.env.MALLOC_ARENA_MAX=1)來覆蓋默認的 MALLOC_ARENA_MAX 參數可能是不可行的,原因是在非白名單變量(yarn.nodemanager.env-whitelist)沖突的情況下, NodeManager 會以合并 URL 的方式來合并原有的值和追加的值,最終造成 MALLOC_ARENA_MAX="4:1" 這樣的結果。
最后,還有一個更徹底的可選解決方案,就是將 glibc 替換為 Google 家的 tcmalloc 或 Facebook 家的 jemalloc [12]。除了不會有 Thread Arena 問題,內存分配性能更好,碎片更少。在實際上,Flink 1.12 的官方鏡像也將默認的內存分配器從 glibc 改為 jemelloc [17]。
JDK8 Native 內存泄漏
Oracle Jdk8u152 之前的版本存在一個 Native 內存泄漏的 bug[13],會造成 JVM 的 Internal 內存分區一直增長。
具體而言,JVM 會緩存字符串符號(Symbol)到方法(Method)、成員變量(Field)的映射對來加快查找,每對映射稱為 MemberName,整個映射關系稱為 MemeberNameTable,由 java.lang.invoke.MethodHandles 這個類負責。在 Jdk8u152 之前,MemberNameTable 是使用 Native 內存的,因此一些過時的 MemberName 不會被 GC 自動清理,造成內存泄漏。
要確認這個問題,需要通過 NMT 來查看 JVM 內存情況,比如筆者就遇到過線上一個 TaskManager 的超過 400 MB 的 MemeberNameTable。

JDK8 MemberNameTable Native 內存泄漏
在 JDK-8013267[14] 以后,MemeberNameTable 從 Native 內存被移到 Java Heap 當中,修復了這個問題。然而,JVM 的 Native 內存泄漏問題不止一個,比如 C2 編譯器的內存泄漏問題[15],所以對于跟筆者一樣沒有專門 JVM 團隊的用戶來說,升級到最新版本的 JDK 是修復問題的最好辦法。
YARN mmap 內存算法
眾所周知,YARN 會根據 /proc/${pid} 下的進程信息來計算整個 container 進程樹的總體內存,但這里面有一個比較特殊的點是 mmap 的共享內存。mmap 內存會全部被算進進程的 VIRT,這點應該沒有疑問,但關于 RSS 的計算則有不同標準。 依據 YARN 和 Linux smaps 的計算規則,內存頁(Pages)按兩種標準劃分:
Private Pages: 只有當前進程映射(mapped)的 Pages
Shared Pages: 與其他進程共享的 Pages
Clean Pages: 自從被映射后沒有被修改過的 Pages
Dirty Pages: 自從被映射后已經被修改過的 Pages 在默認的實現里,YARN 根據 /proc/${pid}/status 來計算總內存,所有的 Shared Pages 都會被算入進程的 RSS,即便這些 Pages 同時被多個進程映射[16],這會導致和實際操作系統物理內存的偏差,有可能導致 Flink 進程被誤殺(當然,前提是用戶代碼使用 mmap 且沒有預留足夠空間)。
為此,YARN 提供 yarn.nodemanager.container-monitor.procfs-tree.smaps-based-rss.enabled 配置選項,將其設置為 true 后,YARN 將根據更準確的 /proc/${pid}/smap 來計算內存占用,其中很關鍵的一個概念是 PSS。簡單來說,PSS 的不同點在于計算內存時會將 Shared Pages 均分給所有使用這個 Pages 的進程,比如一個進程持有 1000 個 Private Pages 和 1000 個會分享給另外一個進程的 Shared Pages,那么該進程的總 Page 數就是 1500。 回到 YARN 的內存計算上,進程 RSS 等于其映射的所有 Pages RSS 的總和。在默認情況下,YARN 計算一個 Page RSS 公式為: ``` Page RSS = Private_Clean + Private_Dirty + Shared_Clean + Shared_Dirty ``` 因為一個 Page 要么是 Private,要么是 Shared,且要么是 Clean 要么是 Dirty,所以其實上述公示右邊有至少三項為 0 。而在開啟 smaps 選項后,公式變為: ``` Page RSS = Min(Shared_Dirty, PSS) + Private_Clean + Private_Dirty ``` 簡單來說,新公式的結果就是去除了 Shared_Clean 部分被重復計算的影響。 雖然開啟基于 smaps 計算的選項會讓計算更加準確,但會引入遍歷 Pages 計算內存總和的開銷,不如 直接取 /proc/${pid}/status 的統計數據快,因此如果遇到 mmap 的問題,還是推薦通過提高 Flink 的 JVM Overhead 分區容量來解決。
感謝你能夠認真閱讀完這篇文章,希望小編分享的“Flink容器化環境下OOM Killed是什么”這篇文章對大家有幫助,同時也希望大家多多支持億速云,關注億速云行業資訊頻道,更多相關知識等著你來學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





