溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Kudu如何使用布隆過濾器優化聯接和過濾,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
在數據庫系統中,提高性能的最有效方法之一是避免執行不必要的工作,例如網絡傳輸和從磁盤讀取數據。Apache Kudu實現此目的的方法之一是通過使用掃描器支持列謂詞。將列謂詞過濾器下推到Kudu可以通過跳過讀取已過濾行的列值并減少客戶端(例如分布式查詢引擎Apache Impala和Kudu)之間的網絡IO來優化執行。有關詳細信息,請參見Impala中有關運行時篩選的文檔。
CDP Runtime 7.1.5和CDP公共云在Kudu中增加了對布隆過濾器列謂詞下推的支持,在Impala中增加了相關的集成。
布隆過濾器是一種節省空間的概率數據結構,用于測試可能存在假陽性匹配的集合成員資格。在數據庫系統中,這些僅用于確定僅需要記錄的子集時是否可以忽略一組數據。有關更多詳細信息,請參見Wikipedia頁面。
Kudu中使用的實現是Putze等人的“高速,散列和空間高效的布隆過濾器”中的一種基于空間,哈希和高速緩存的基于塊的布隆過濾器。此布隆過濾器來自Impala的實現,并得到了進一步增強。基于塊的布隆過濾器設計為適合CPU緩存,并且允許使用AVX2(如果可用)進行SIMD操作,以進行有效的查找和插入。
考慮在謂詞下推不可用的小表和大表之間進行廣播哈希聯接的情況。這通常涉及以下步驟:
讀取整個小表并從中構造一個哈希表。
將生成的哈希表廣播到所有工作節點。
在工作節點上,開始對大表的切片進行獲取和迭代,檢查哈希表中是否存在大表中的鍵,并僅返回匹配的行。
步驟3任務最重,因為它涉及讀取整個大表,并且如果工作程序和承載大表的節點不在同一服務器上,則可能涉及繁重的網絡IO。
在7.1.5之前,Impala支持僅將“最小/最大(MIN_MAX)”運行時過濾器下推至Kudu,從而過濾掉不在指定范圍內的值。除了MIN_MAX運行時過濾器之外,CDP 7.1.5+中的Impala現在還支持將運行時布隆過濾器下推到Kudu。借助Kudu中新引入的布隆過濾謂詞支持,Impala可以使用此功能對存儲在Kudu中的數據執行更加高效的聯接。
與上述情況一樣,我們運行了一個Impala查詢,該查詢將存儲在Kudu上的一個大表和存儲在HDFS上Parquet格式的一個小表連接在一起。該小表是使用HDFS上的Parquet創建的,以隔離新功能,但也可以將其存儲在Kudu中。我們首先僅使用MIN_MAX過濾器,然后使用MIN_MAX和布隆過濾器(所有運行時過濾器)運行查詢。為了進行比較,我們在HDFS的Parquet中創建了相同的大表。在HDFS上使用Parquet是比較的不錯的基準,因為Impala已經支持HDFS上Parquet的MIN_MAX和布隆過濾器。
在具有CDP運行時7.1.5的6節點集群上執行了以下測試。
硬件配置:
Dell PowerEdge R430、2.2chz @ 20c / 40t Xeon e5-2630 v4、128GB Ram,4塊2TB的硬盤用于WAL,3個磁盤用于數據目錄。
Schema:
大表由2.6億行組成,其中隨機生成的數據哈希由主鍵跨Kudu上的20個分區進行分區。Kudu表已明確進行了重新平衡,以確保加載后保持平衡的布局。
小表由存儲在HDFS上的Parquet的大表中的前1000個鍵和后1000個鍵的2000行組成。這將阻止MIN_MAX過濾器對大表進行任何過濾,因為所有行都將落在MIN_MAX過濾器的范圍內。
在所有表上都運行了COMPUTE STATS,以幫助收集有關表元數據的信息并幫助Impala優化查詢計劃。
所有查詢都運行了10次,平均查詢運行時間如下所示。
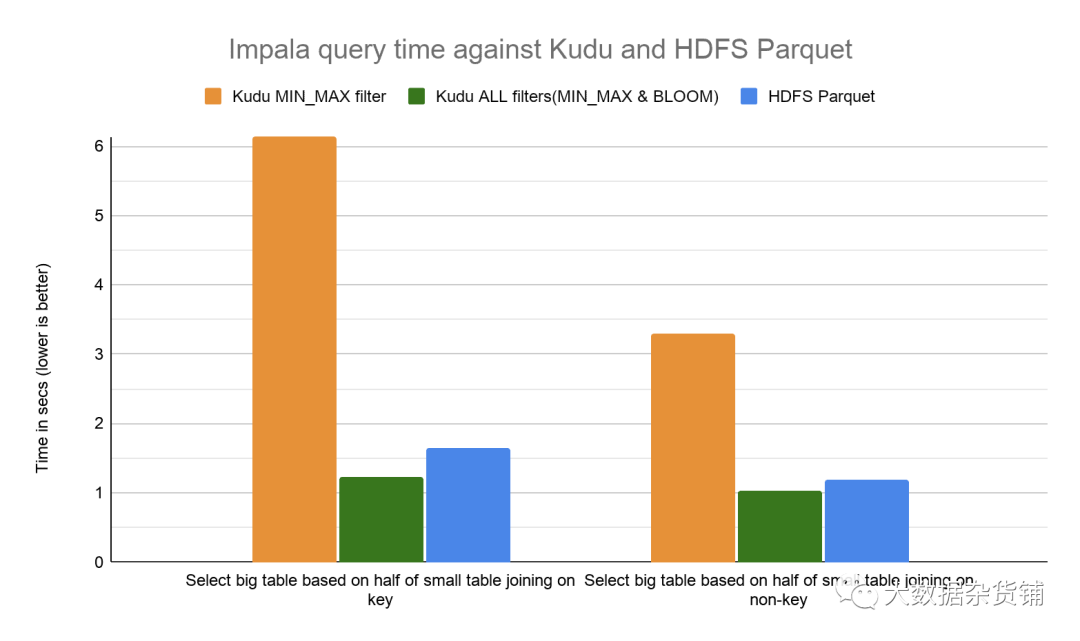
對于聯接查詢,通過使用布隆過濾器謂詞下推,我們發現Kudu的性能提高了3倍至5倍。我們期望通過更大的數據大小和更多的選擇性查詢,看到更好的性能倍數。
與HDFS上的Parquet相比,Kudu的性能現在提高了約17-33%。
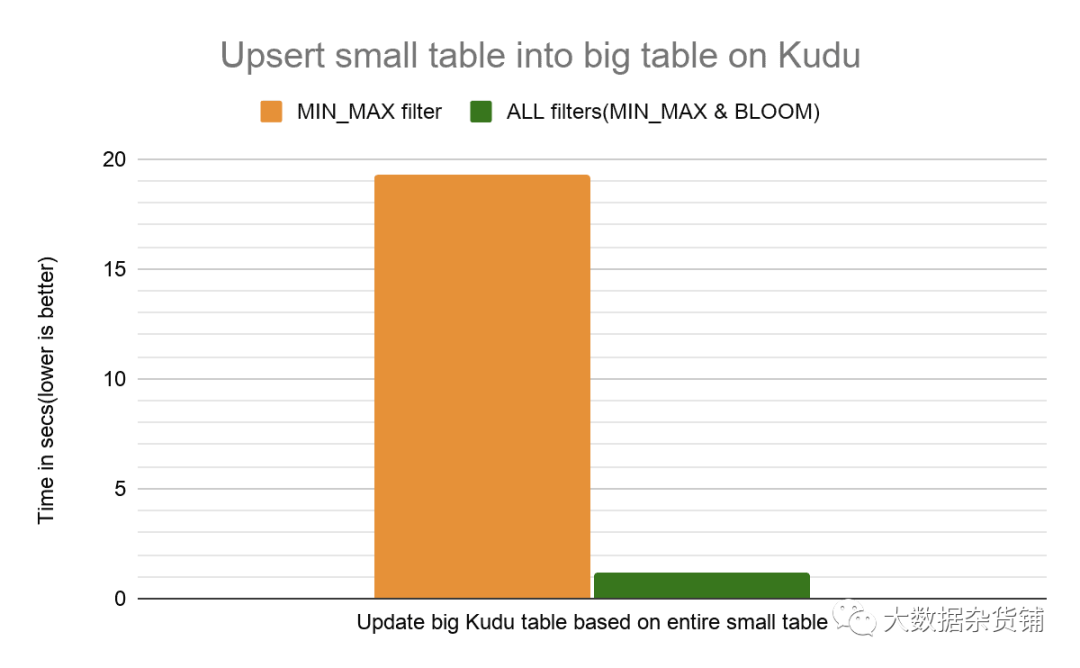
對于基本上將整個小表插入現有大表的更新查詢,我們看到了15倍的改進。這主要是由于在選擇要更新的行時提高了查詢性能。
有關表的模式、加載過程和運行的查詢的詳細信息,請參見下面的參考部分。
我們還在具有比例因子為30的單節點集群上運行了TPC-H基準測試,并且在不同的塊緩存容量設置下,性能提高了19%到31%。
Kudu會自動禁用無法有效過濾數據的布隆過濾謂詞,以避免新功能對性能造成的損失。在功能開發過程中,TPCH基準(TPCH-Q9)中的查詢9表現出50-96%的回歸。在進一步調查中,掃描來自Kudu的行所需的時間最多增加了2倍。在調查此回歸時,我們發現被下推的布隆過濾器謂詞篩選出的行數不到10%,從而導致Kudu中CPU使用率的增加,其價值超過了過濾器的優勢。為了解決回歸問題,我們在Kudu中添加了一種啟發式方法,其中,如果布隆過濾器謂詞未篩選出足夠百分比的行,則在其余掃描期間將自動禁用它。
使用Impala查詢Kudu的用戶將默認從CDP 7.1.5起和CDP公共云啟用此功能。我們強烈建議用戶升級以在版本中獲得此性能增強和許多其他性能增強。對于直接使用Kudu客戶端API的自定義應用程序,Kudu C ++客戶端還具有從CDP 7.1.5開始可用的布隆過濾器謂詞。Kudu Java客戶端尚未提供布隆過濾器謂詞KUDU-3221。
看完上述內容,你們對Kudu如何使用布隆過濾器優化聯接和過濾有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





