溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇文章給大家分享的是有關然后用隧道協議實現不同dubbo集群間的透明通信,小編覺得挺實用的,因此分享給大家學習,希望大家閱讀完這篇文章后可以有所收獲,話不多說,跟著小編一起來看看吧。
筆者最近完成了一個非常有意思的隧道機制(已在產線運行),可以讓注冊到不同zookeeper之間的dubbo集群之間能夠正常進行通信。如下圖所示: 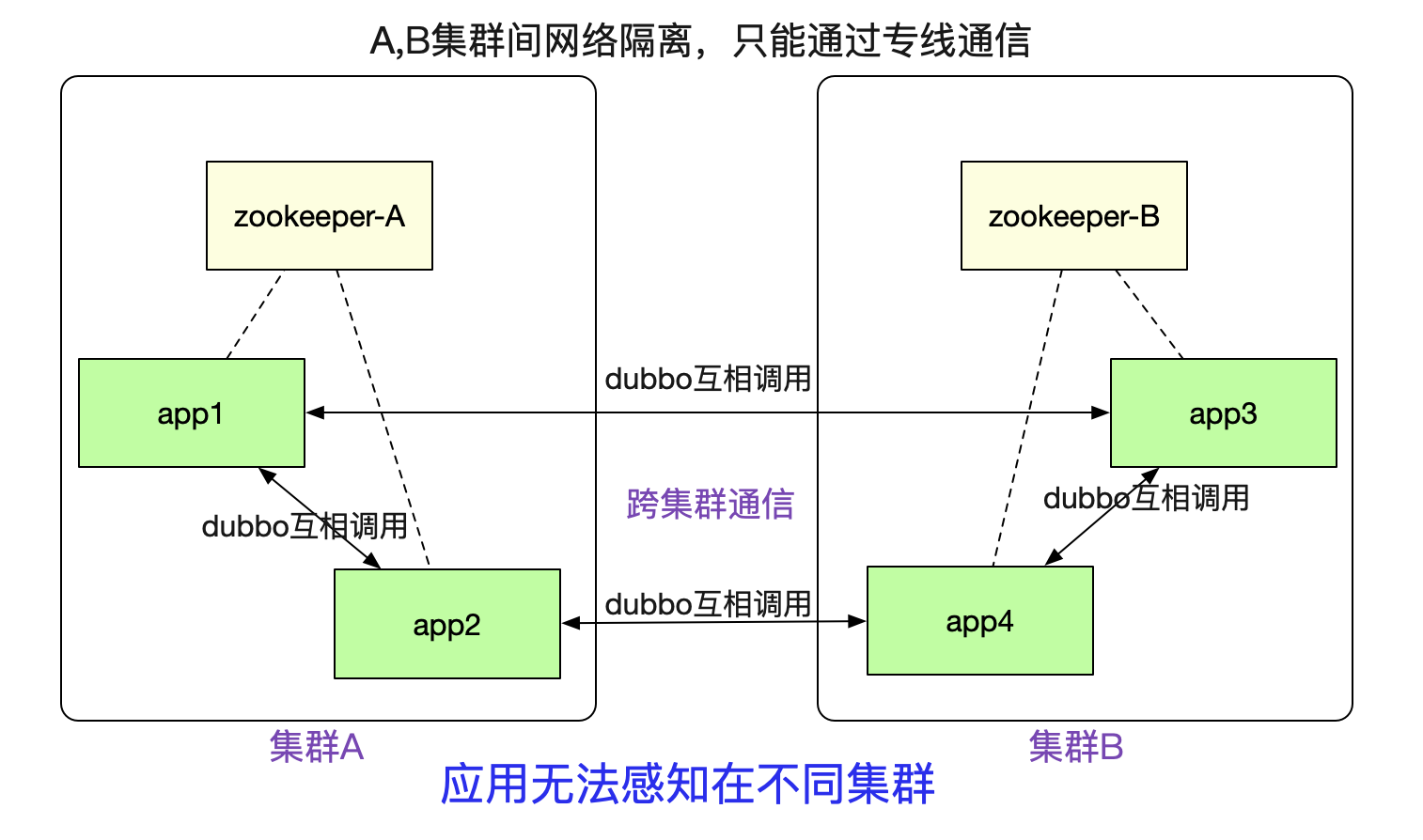
例如圖中A/B兩個網絡隔離的集群,兩者只能通過專線進行通信。但是對于在里面的應用來說,調用另外一個集群的dubbo服務(例如app1調用app3)依舊和原來的方式一模一樣,無需做任何修改。這個特性對于新建單元(機房),業務網絡隔離等場景非常有用。
這個dubbo集群通信機制,可被用在下面的場景中。
在我們新建一個機房的過程中。正常情況下,需要將一整條鏈路的所有應用以及相關設施全部部署到新的機房中。如下圖所示: 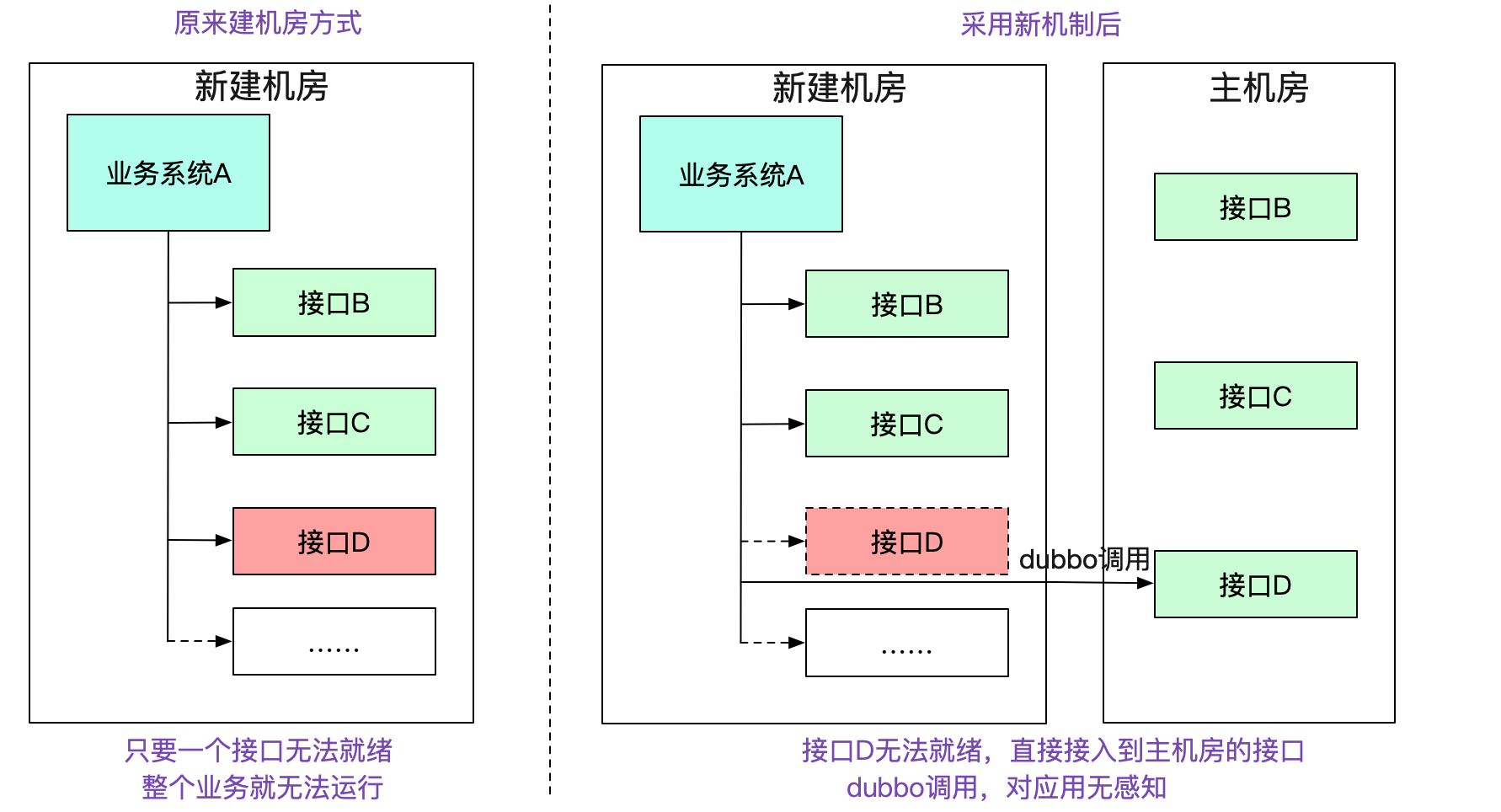
而在筆者新的機制中,如果本集群沒有對應的接口,會去尋找有對應接口的集群,就算其中缺失了一些系統,整個機房依舊能夠work,將新建機房變為可迭代式的。大幅度減少了新建機房的復雜性。
由于單機房機架位的限制或者一些其它原因,有一些業務希望剝離到一個單獨的單元(機房里面)。但是業務確需要一大堆原來單元的基礎服務。而不同單元之間的網絡又無法打通(安全性要求)。 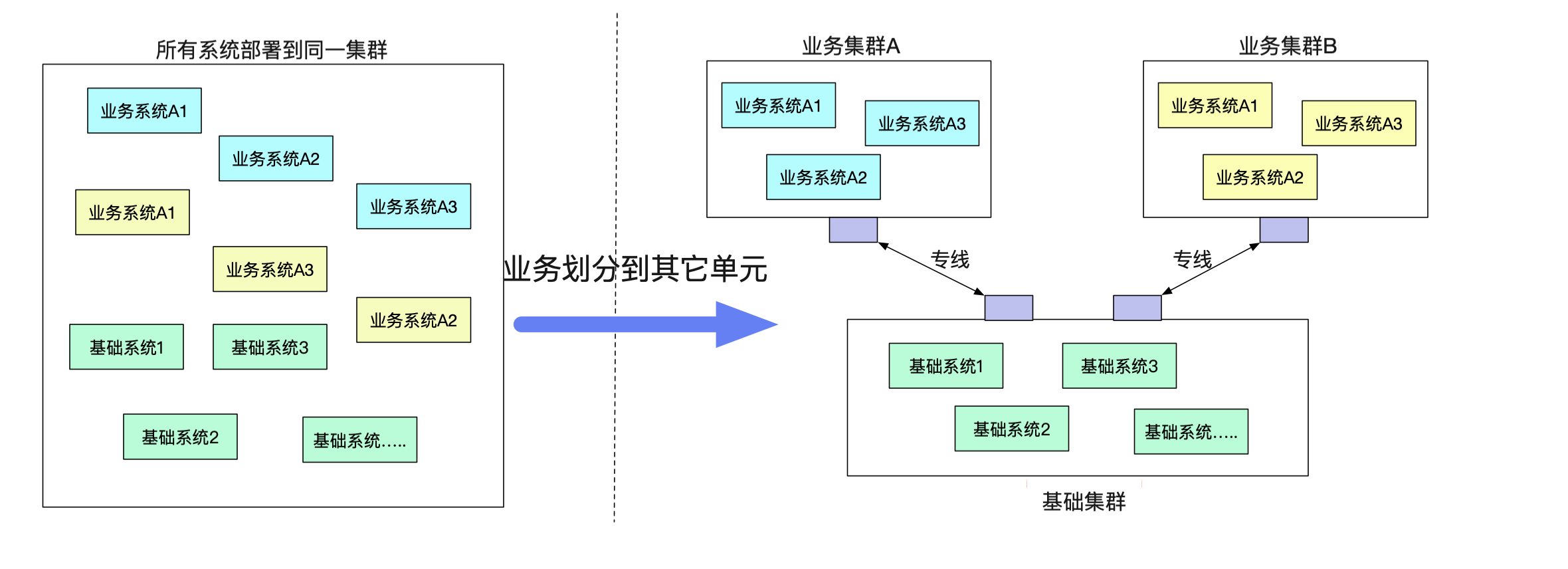
如果按照傳統的模式,勢必要對業務系統做改造,例如建立一個業務網關來負責和基礎系統的通信,這個網關明顯費時費力而且沒什么技術含量,例如在業務代碼中將dubbo調用強行轉換為對業務網關的http調用,如下圖所示: 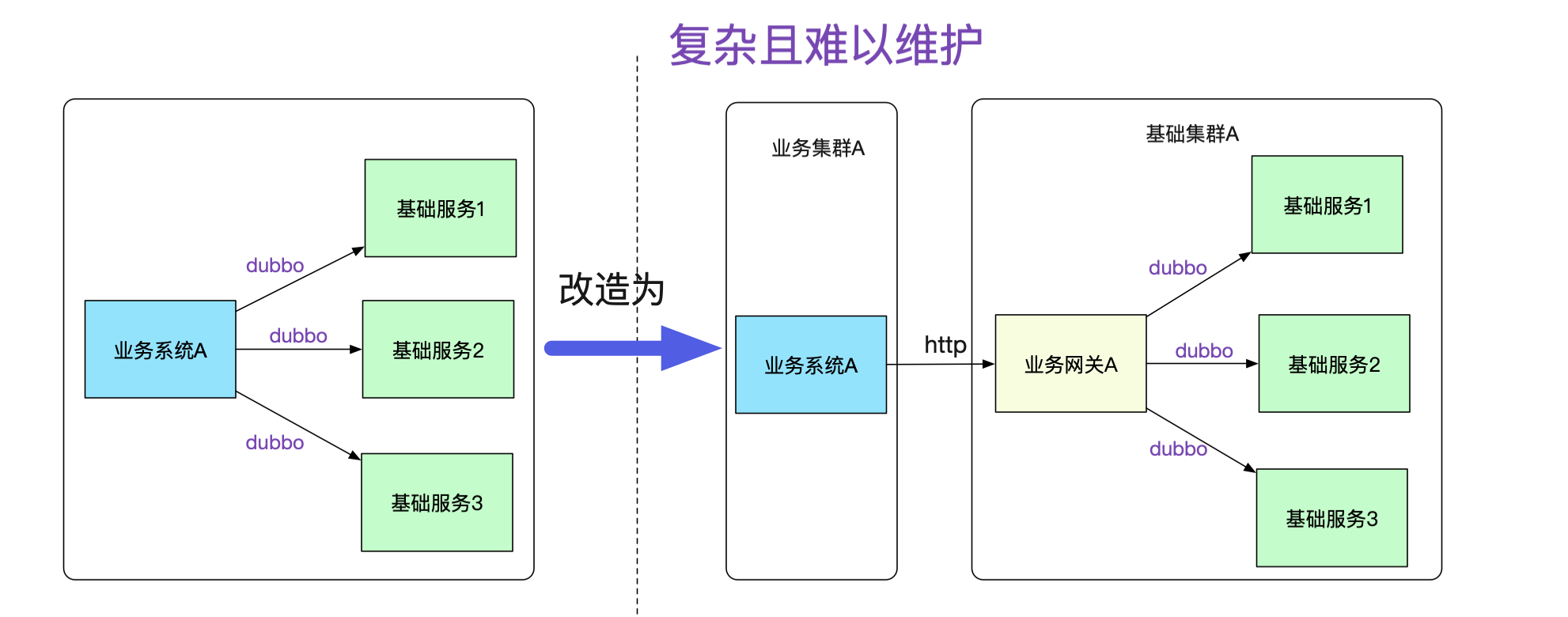
而且,每增加一個接口調用,都得在業務網關中轉換一把,添加對應的接口包,然后發布。這樣的網關維護起來肯定是個天坑!隨著日益嚴格的安全性要求,不同業務間的網絡隔離要求會與日俱增。
筆者是搞中間件的,堅信做的基礎服務能夠對業務透明,讓其感知不到才是一個好的設計。一旦需要業務大量配合這種由基礎架構變更而引起的改造,無疑是非常的不友好,甚至是個失敗的設計。
事實上,筆者搞這一套隧道機制的初衷還有很大一部分原因是故障隔離。例如,筆者遇到數次由于業務系統使用zookeeper不當,往zookeeper寫了一大堆數據,從而讓整個集群陷入不可用的風險。而新的機制,可以讓不同的業務注冊到不同的zookeeper,zookeeper掛了,也只是這個業務宕了,其它業務則不受影響。 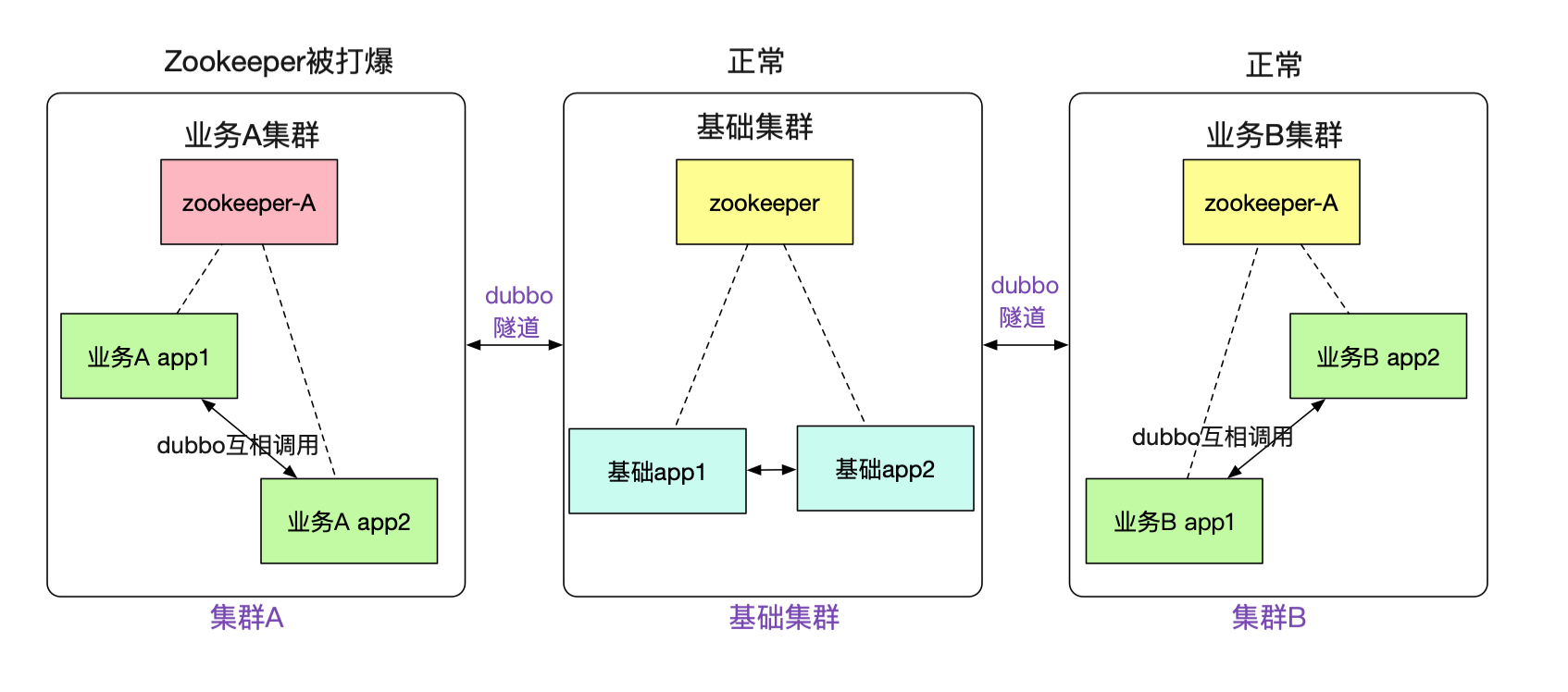
事實上不僅為zookeeper,由于筆者對消息(例如activemq)也做了這一套類似的隧道機制。使得我們的整個業務能夠更好的進行故障隔離!
筆者這個機制的最大便利性在于對業務的侵入性很少。對于基礎集群的應用甚至完全不需要做修改。為了達成這個需求,筆者引入了在網絡上非常常用的隧道概念(Tunnel),這個大家可能平時都接觸過,VPN/Vxlan這些網絡協議都用了隧道。
我們先來看一下最基本的原理,在系統A通過Dubbo調用系統B的時候,在同一個集群中走的是dubbo協議。而跨集群的時候,筆者將dubbo原始比特流承載在http協議上,在專線上發出去。 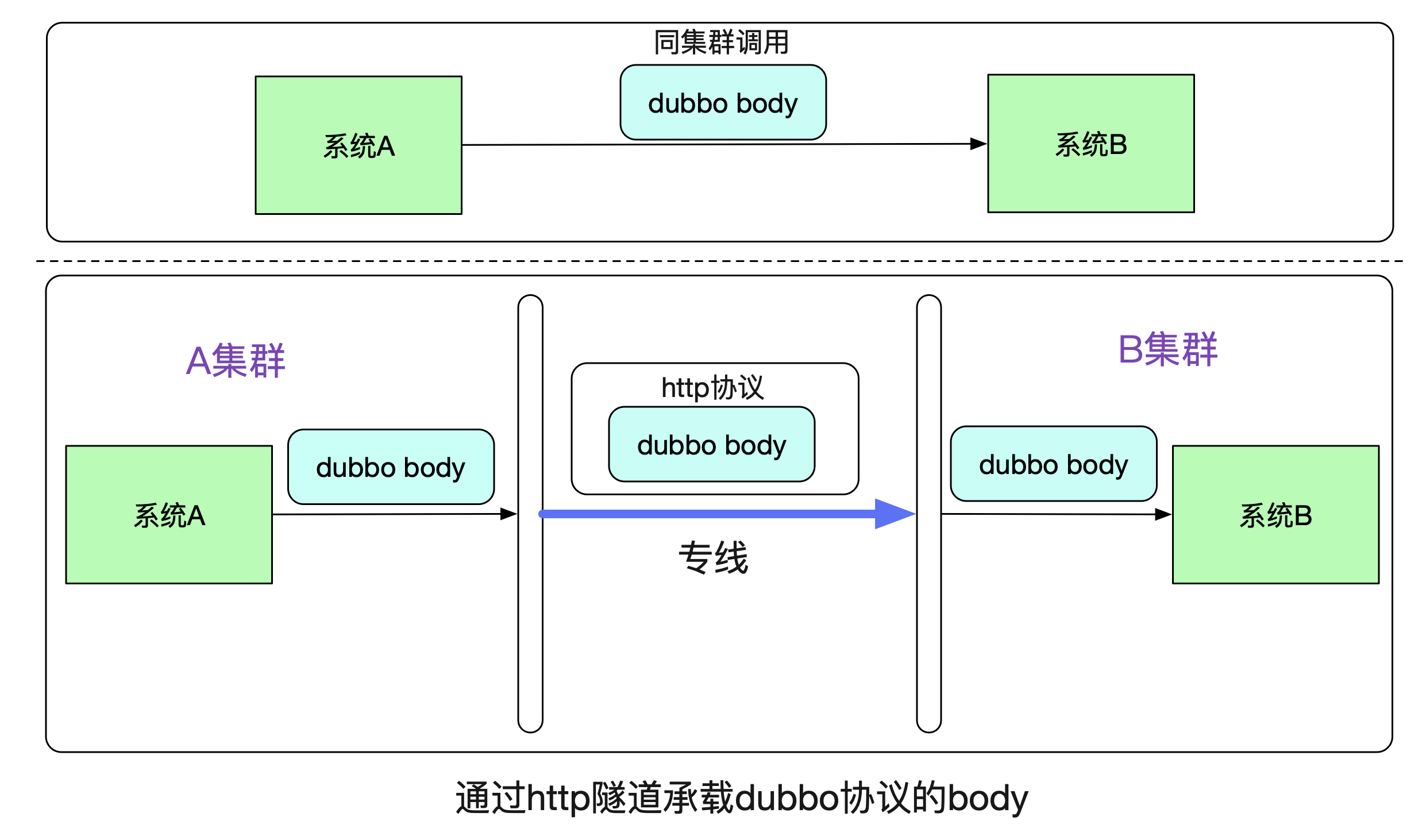
由于在B系統看來,接收到的都是相同的byte流,其無法(也不用)區分到底是走了一層專線還是直接調用。所以B系統無需更改任何代碼。
那么,這個隧道具體是如何實現,系統A又是如何知道需要本集群沒有對應的接口,需要通過http隧道調用到另一個集群的呢?這就引入了我們的隧道網關。
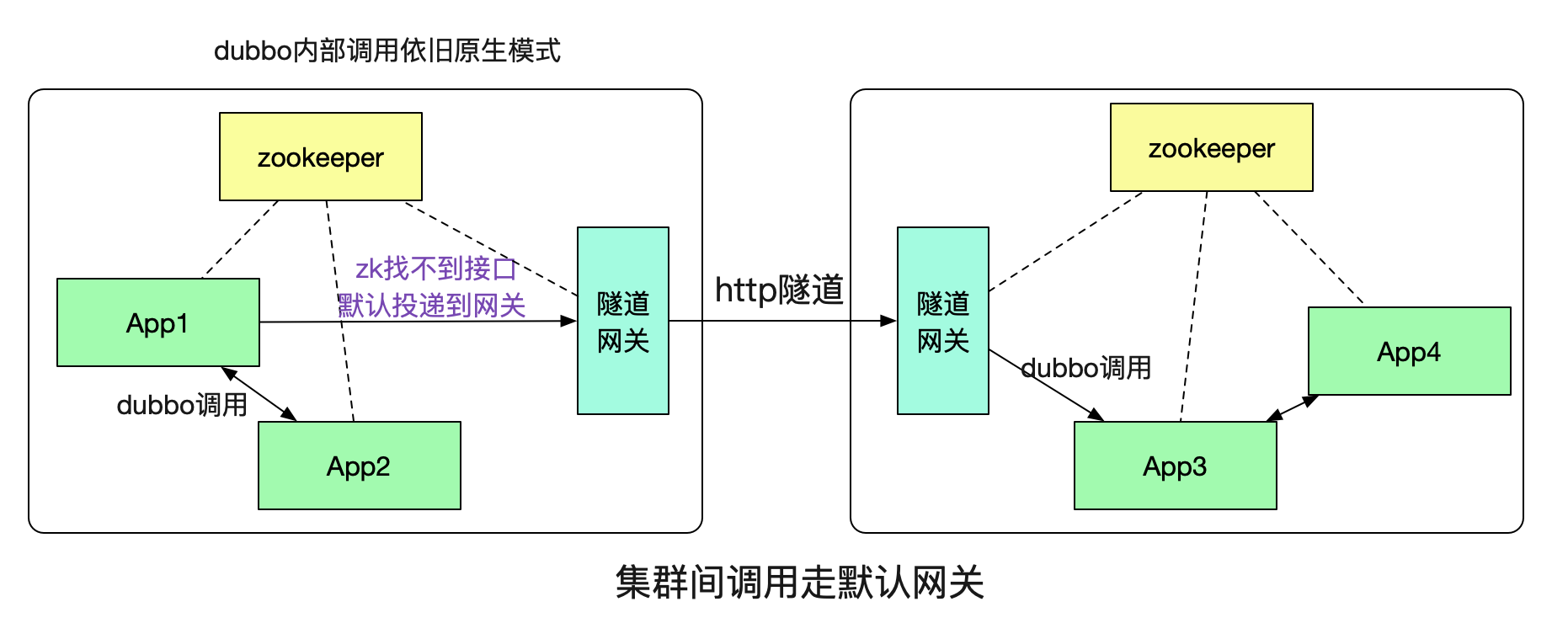
這里的概念也是和網絡上的默認網關類似,如果本集群內找不到對應的接受者就投遞到一個默認的網關,由這個隧道網關來替我們傳遞調用。
為了充分利用dubbo接口的注冊發現機制,筆者將隧道網關也暴露為一個dubbo接口,其輸入和輸出分別如下所示:
// 隧道網關接口請求體
class TunnelInterfaceReq {
// dubbo元信息,例如具體調用接口信息
MetaData dubbo
// 原始請求A調用序列化后的比特流
byte[] body;
}
// 隧道網關接口返回體
class TunnelInterfaceResp{
// dubbo元信息
MetaData dubbo
// 返回值調用序列化后的比特流,由另一個集群的對應系統返回
byte[] resp;
}有了這個dubbo接口,我們就可以很容易的將數據傳送給默認網關了。 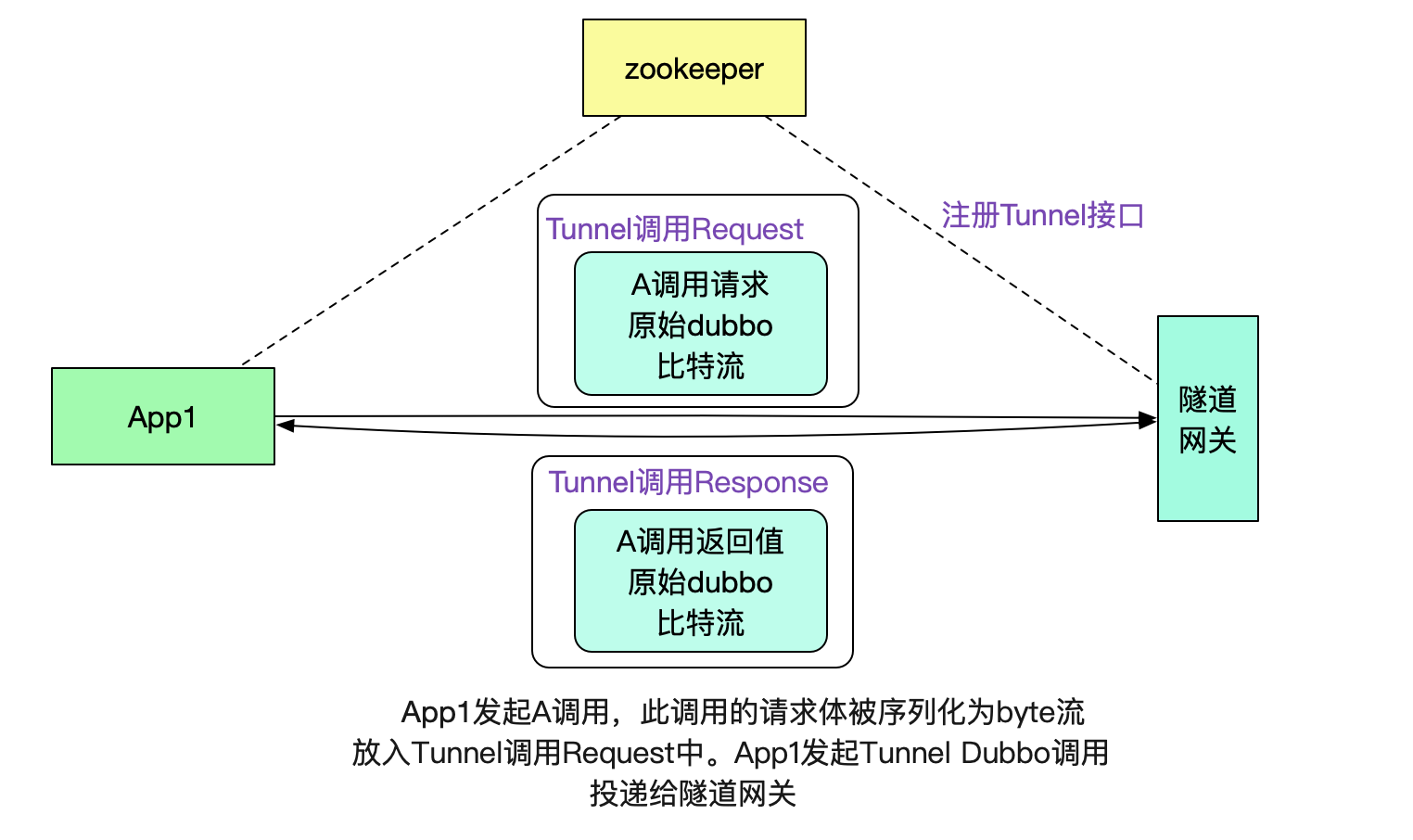
注意,這里其實也是做了一層隧道協議,即用dubbo協議承載dubbo協議,用這種類似套娃的方法有效的利用了dubbo本身的注冊發現機制。
由于不同集群之間通過專線進行通信,所以筆者采用了http通信來進行。在App1的請求到達隧道網關后,網關會將原始body比特流從TunnelInterfaceRequest中取出。然后放到一個http的請求中進行傳遞。如下圖所示: 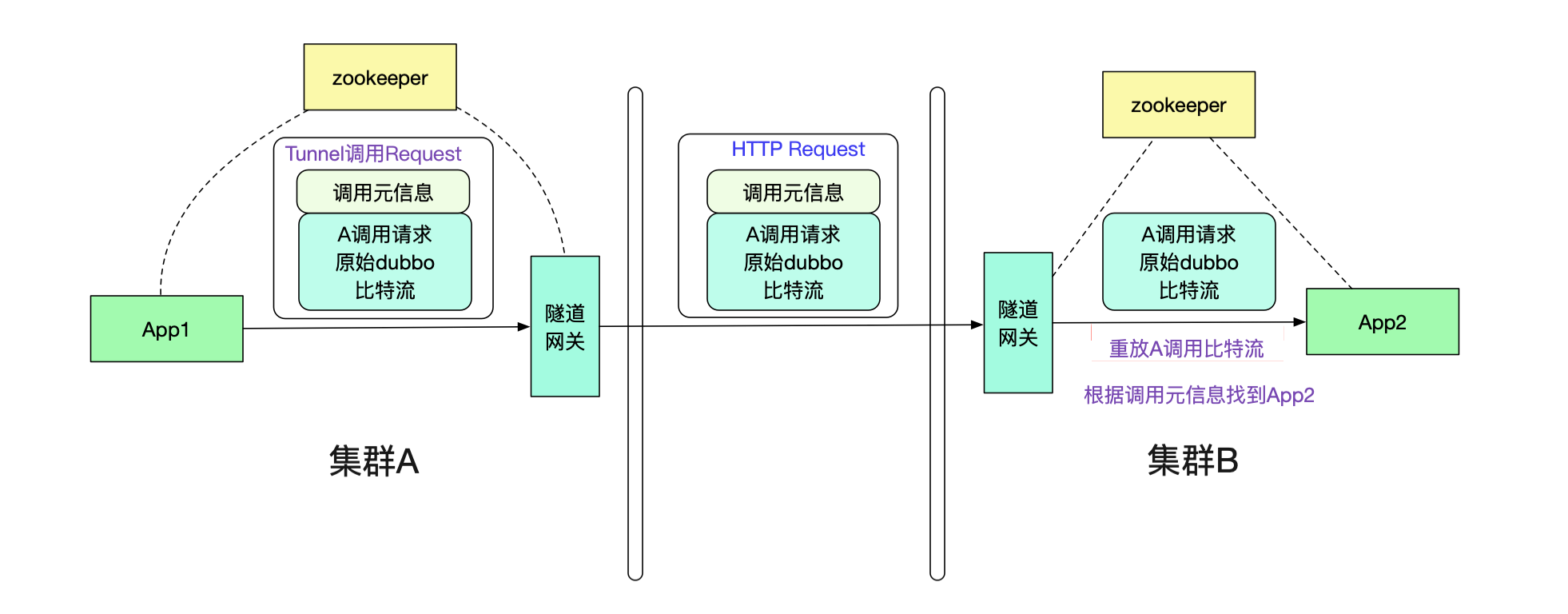
值得注意的是,由于傳遞的是byte流,沒有攜帶任何業務信息(例如類型信息等),所以我們的隧道網關可以對任意dubbo請求進行隧道傳輸,而不像傳統的網關那樣需要添加各種業務對應的jar包并不停發布-_-!
在圖中,投遞到另一端的隧道網關后,其從http協議中取出調用元信息和原始調用byte流,通過調用元信息找到App2。然后給App2重放byte流,這樣就可以進行dubbo調用了。事實上,App2從隧道網關看到的byte流和從集群內其它機器調用的byte流完全一致。如下圖所示: 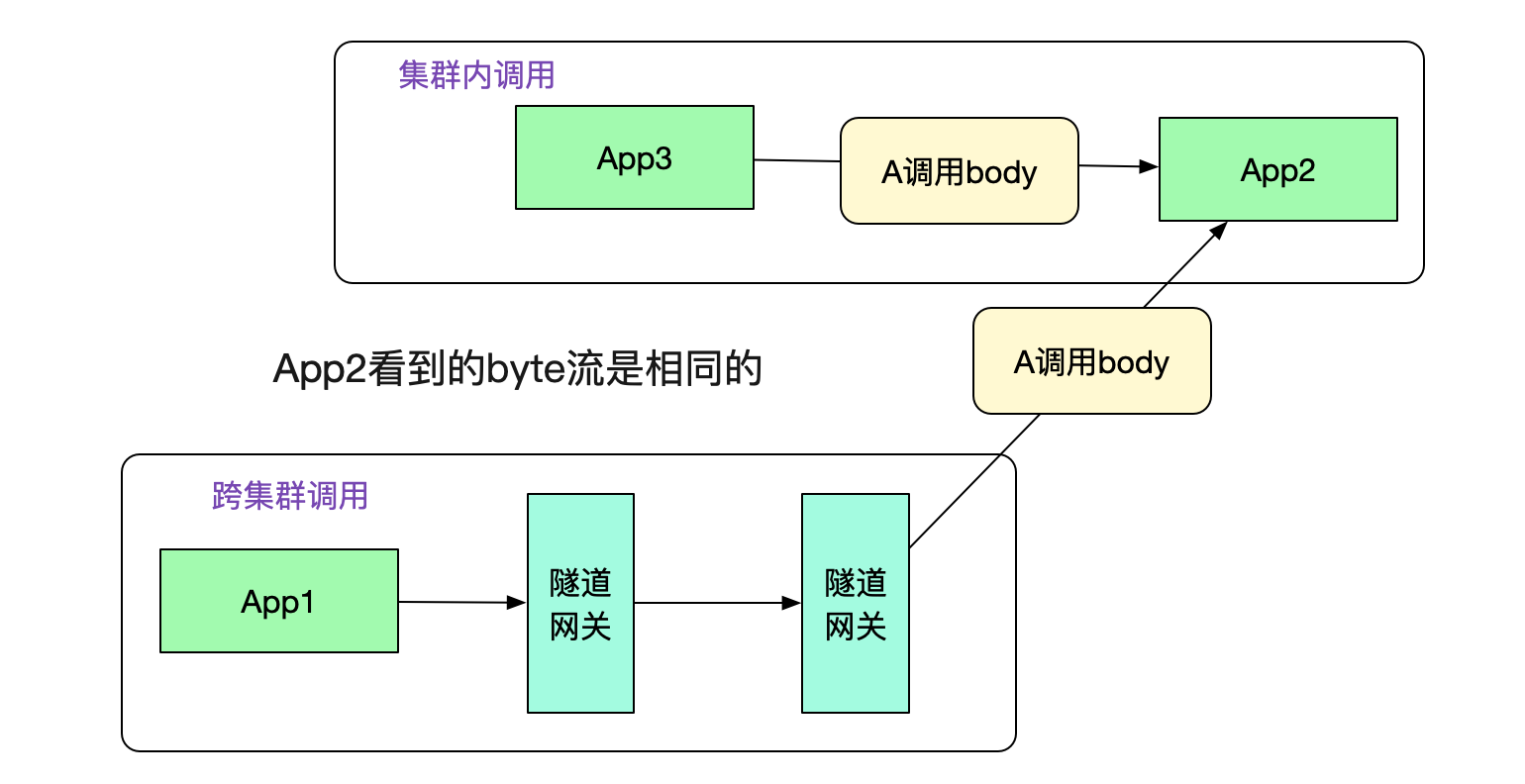
很明顯的,我們的返回值也需要通過隧道機制。和Request一樣,其也會走兩次隧道協議,如下圖所示: 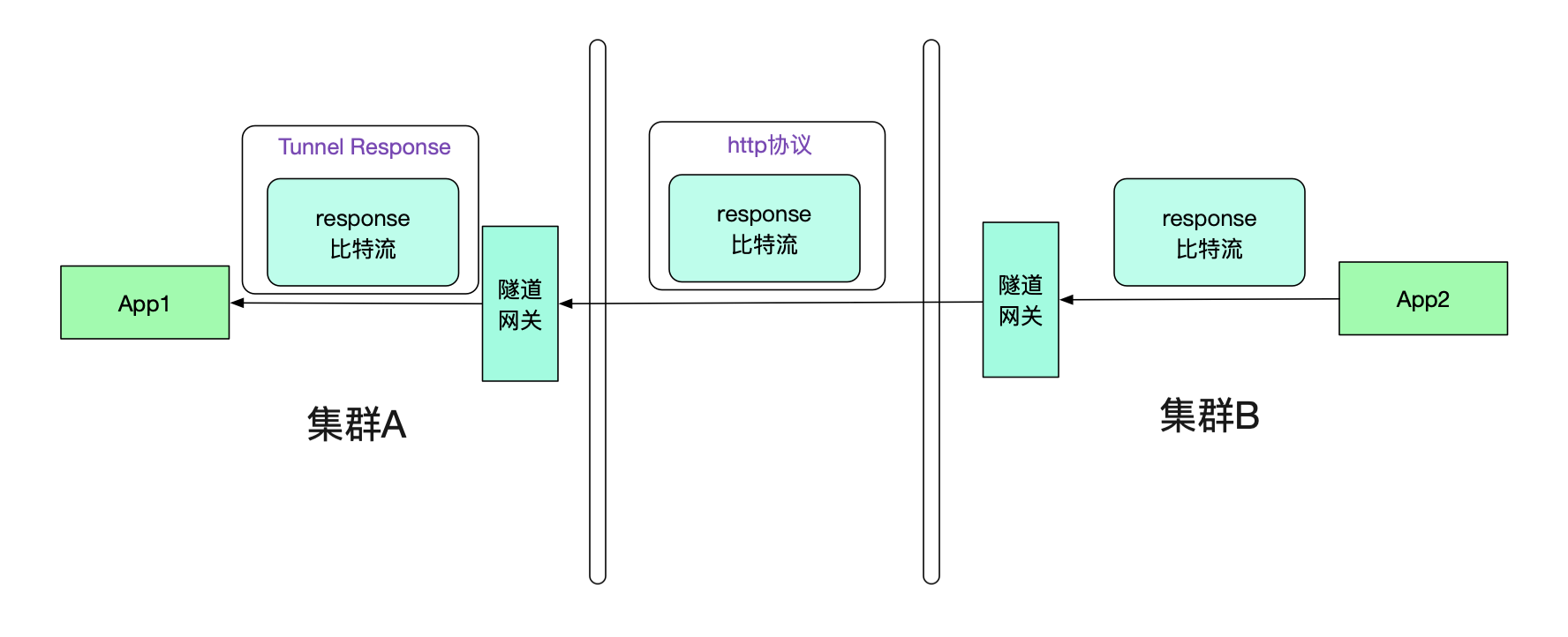
那么App1真正接收到的其實是Tunnel Response,怎么讓其透明的接收原始response比特流呢?這就需要調用方接入筆者研發的輕量級jar包(其實,一開始的request的隧道也需要這樣的jar包)
由于dubbo有非常優秀的filter機制,可以在各種地方可以擴展。為了這個隧道機制,筆者就擴展了其中的invoke調用邏輯。如下圖所示:
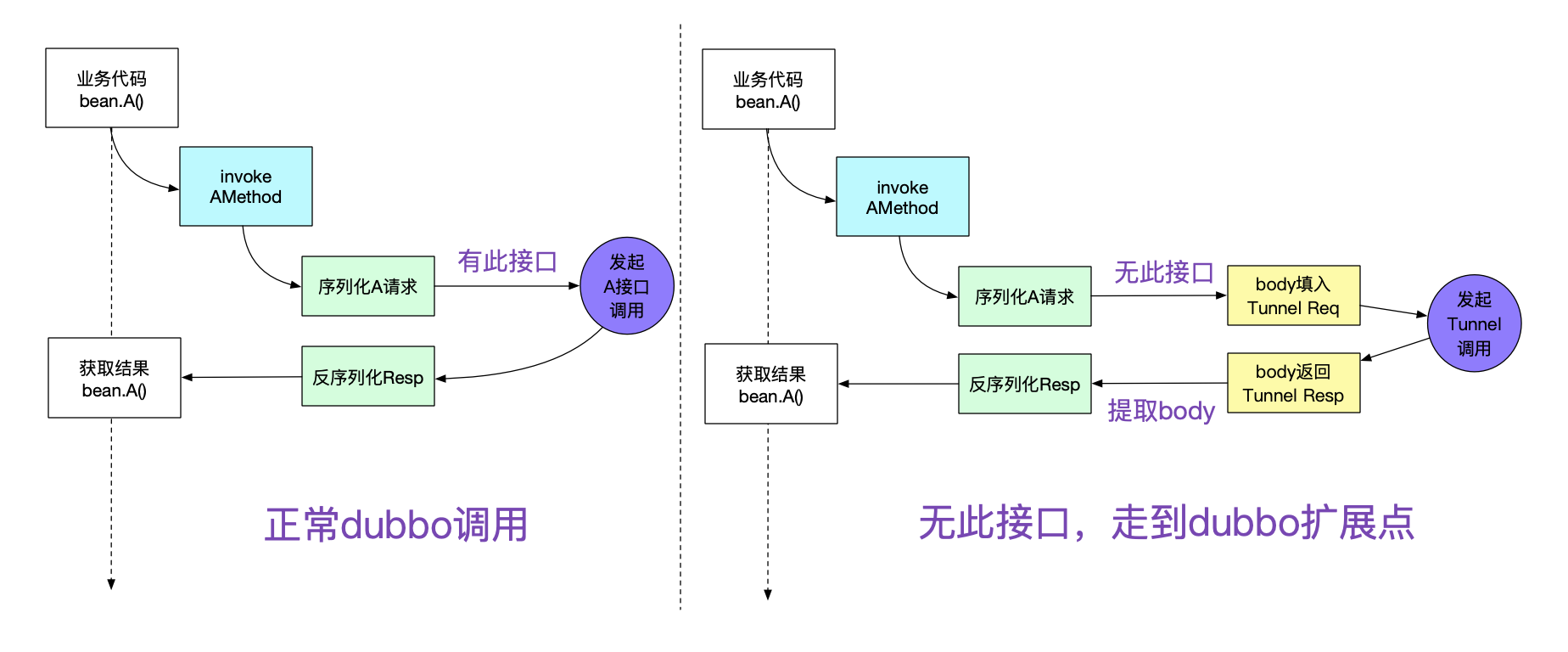
只要引入筆者寫的jar包,就能夠非常輕松的進行自動擴展,除了pom.xml加兩行,其它業務代碼完全無需修改。
那么隧道網關A是怎么知道接口在集群B,從而投遞給隧道網關B的呢?很明顯的,我們需要隧道網關間的集群通信機制。 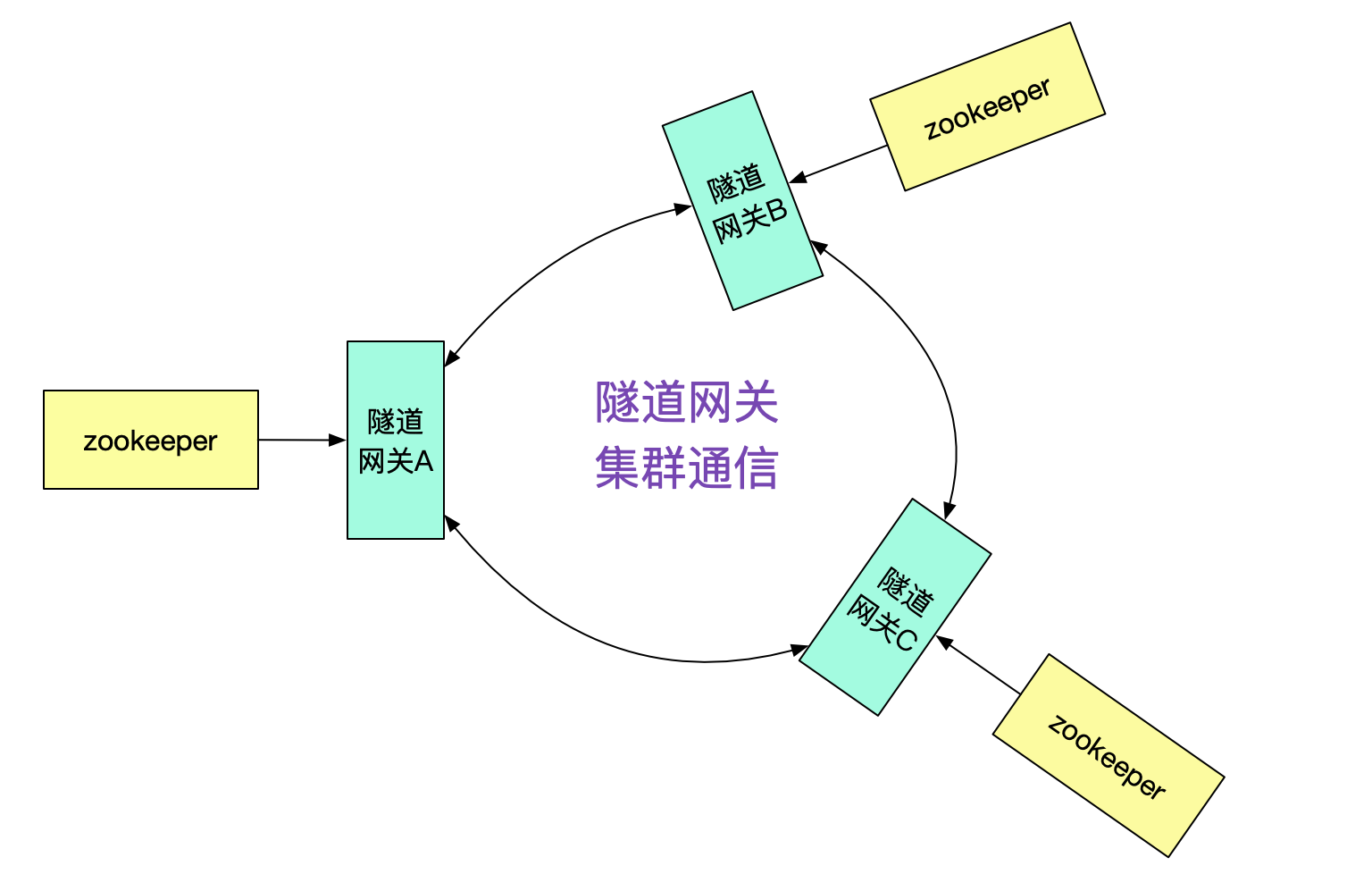
例如,由隧道網關向其它不同的隧道網關詢問是否有此接口,并按一定策略做緩存即可。 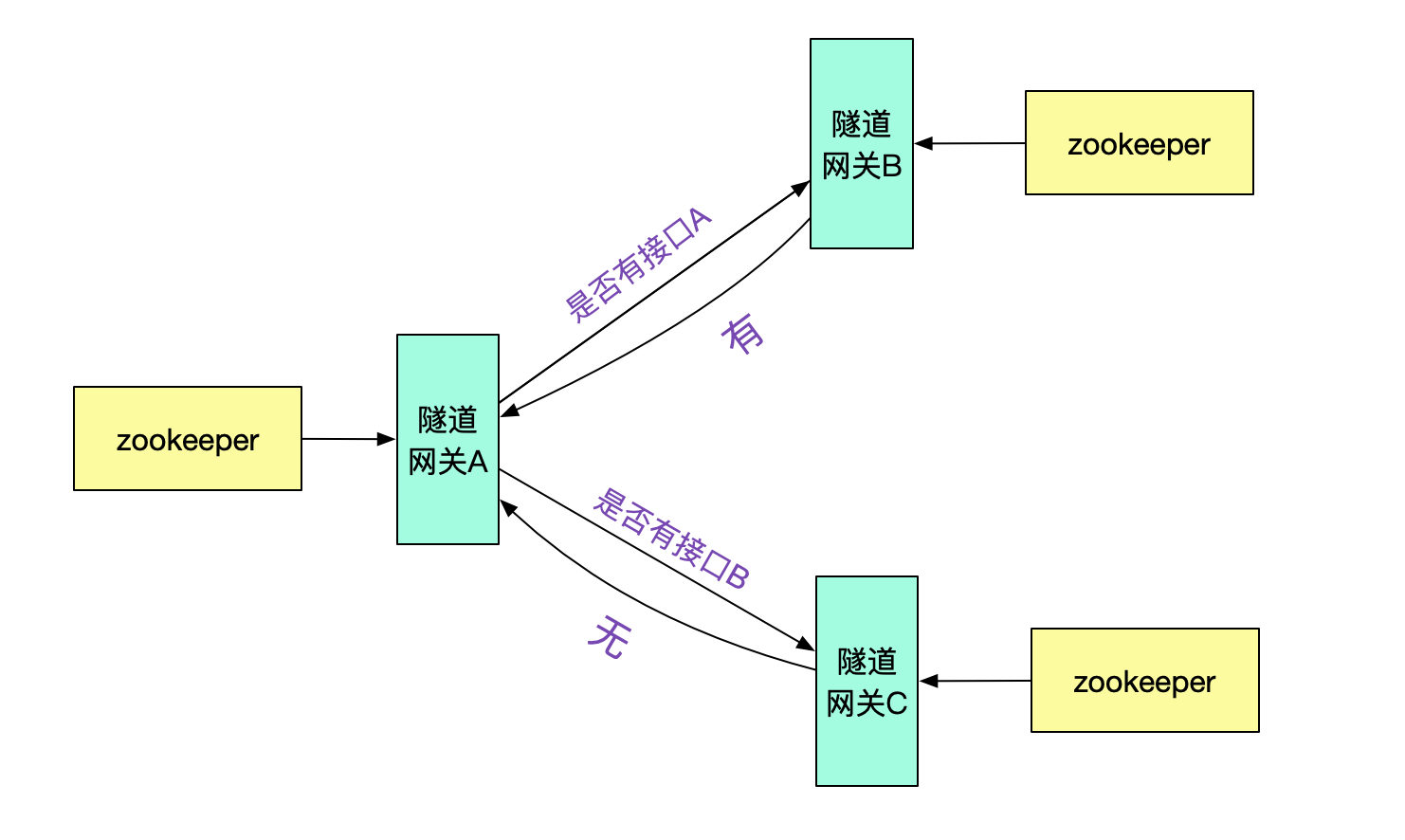
最后的問題就是隧道網關怎么知道其它的dubbo集群的了,由于相對于dubbo接口數量,集群的數量是很少且不經常改變。我們只需要找個地方簡單的記錄下即可,例如放到數據庫里面。然后由于是http調用,直接通過DNS解析域名即可做負載均衡。 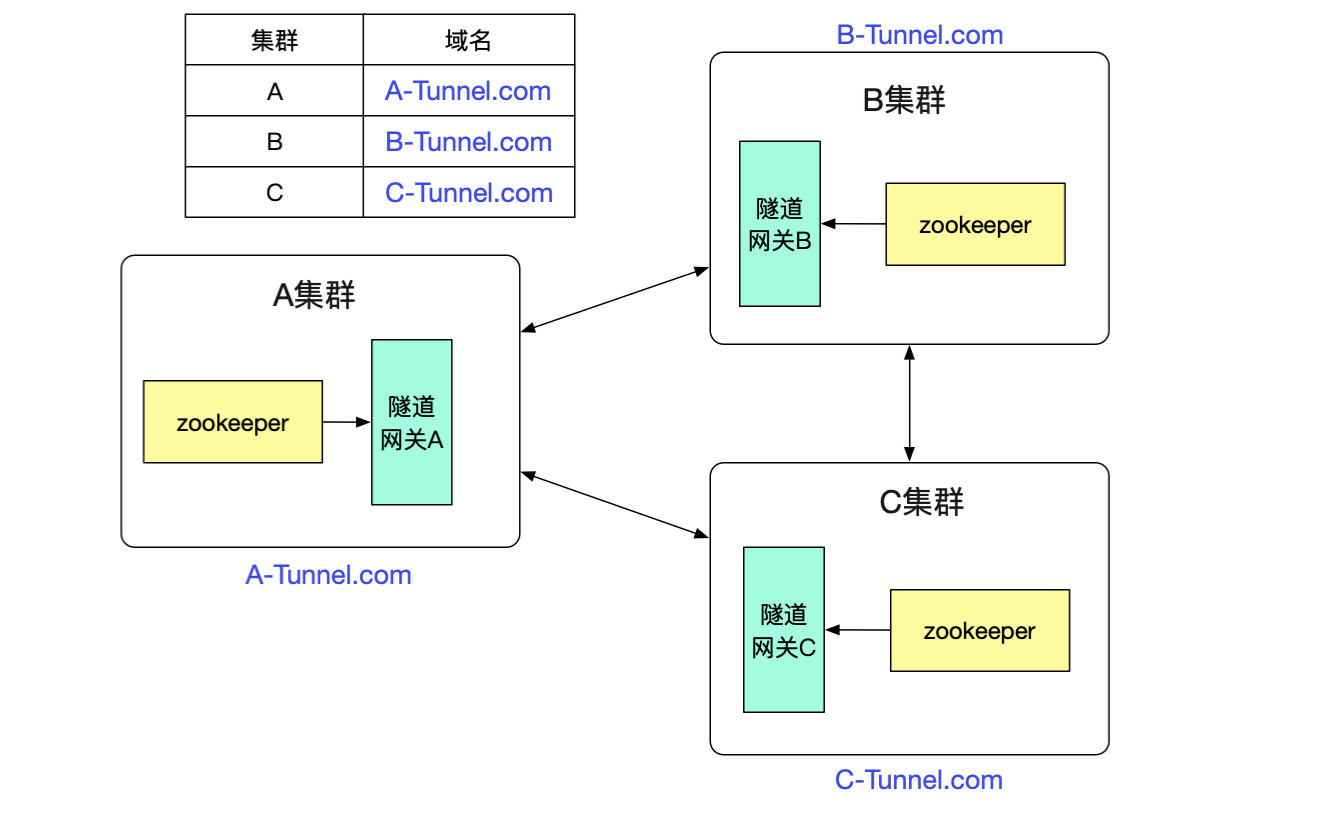
由于筆者的這套機制序列化和反序列化完全在Provider/Consumer端,完全沒有對網關形成任何壓力,所以網關的CPU消耗很低。在單個調用延遲上,由于多了兩跳,不可避免的有所損耗,大概每個接口多了2ms左右。
以上就是然后用隧道協議實現不同dubbo集群間的透明通信,小編相信有部分知識點可能是我們日常工作會見到或用到的。希望你能通過這篇文章學到更多知識。更多詳情敬請關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





