溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關消息中間件Kafka、RocketMQ該怎么理解,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
消息中間件的應用場景
異步解耦
削峰填谷
順序收發
分布式事務一致性
Kafka:整個行業應用廣泛
RocketMQ:阿里,從 apache 孵化
Pulsar:雅虎開源,符合云原生架構的消息隊列,社區活躍
RabbitMQ 架構比較老,AMQP并沒有在主流的 MQ 得到支持
NSQ:內存型,不是最優選擇
ActiveMQ、ZeroMQ 可忽略
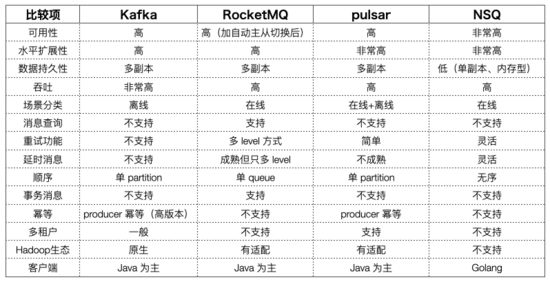
非常成熟,生態豐富,與 Hadoop 連接緊密
吞吐非常高,可用性高sharding提升 replication 速度
主要功能:pub-sub,壓縮支持良好
可按照 at least once, at most once 進行配置使用,exactly once 需要 Consumer 配合
集群部署簡單,但 controller 邏輯很復雜,實現partition 得多副本、數據一致性
controller 依賴 ZooKeeper
異步刷磁盤(除了錢的業務,很少有同步 flush 的需求)
寫入延時穩定性問題,partition 很多時Kafka 通常用機械盤,隨機寫造成吞吐下降和延時上升100ms ~ 500ms
運維的復雜性單機故障后補充副本數據遷移快手的優化:遷移 partition 時舊數據不動,新數據寫入新 partition 一定時間后直接切換
阿里根據 Kafka 改造適應電商等在線業務場景
以犧牲性能為代價增強功能安 key 對消息查詢,維護 hash 表,影響 io為了在多 shard 場景下保證寫入延遲穩定,在 broker 級別將所有 shard 當前寫入的數據放入一個文件,形成 commitlog list,放若干個 index 文件維護邏輯 topic 信息,造成更多的隨機讀
沒有中心管理節點,現在看起來并沒有什么用,元數據并不多
高精度的延遲消息(快手已支持秒級精度的延遲消息)
存儲、計算分離,方便擴容存儲:bookkeeperMQ邏輯:無狀態的 broker 處理
云原生
批流一體:跑任務時,需要先把 Kafka 數據→HDFS,資源消耗大。如果本來就存在 HDFS,能節省很大資源
Serverless
快手:Kafka所有場景均在使用特殊形態的讀寫分離數據實時消費到 HDFS在有明顯 lag 的 consumer 讀取時,broker 把請求從本地磁盤轉發的 HDFS不會因為有 lag 的 consumer 對日常讀寫造成明顯的磁盤隨機讀寫由于自己改造,社區新功能引入困難
阿里巴巴:開源 RocketMQ
字節跳動在線場景:NSQ→RocketMQ離線場景:Kafka→自研的存儲計算分類的 BMQ(協議層直接兼容Kafka,用戶可以不換 client)
百度:自研的 BigPipe,不怎么樣
美團:Kafka 架構基礎上用 Java 進行重構,內部叫 Mafka
騰訊:部分使用了自研的 PhxQueue,底層是 KV 系統
滴滴:DDMQ對 RocketMQ 和 Kafka 進行封裝多機房數據一致性可能有問題
小米:自研 Talos架構類似 pulsar,存儲是 HDFS,讀場景有優化
Kafka官網: https://kafka.apache.org/documentation/#uses
最新版本:2.7
開源的消息引擎系統(消息隊列/消息中間件)
分布式流處理平臺
發布/訂閱模型
削峰填谷
Topic:發布訂閱的主題
Producer:向Topic發布消息的客戶端
Consumer:消費者
Consumer Group:消費者組,多個消費者共同組成一個組
Broker:Kafka的服務進程
Replication:備份,相同數據拷貝到多臺機器Leader ReplicaFollower Replica,不與外界交互
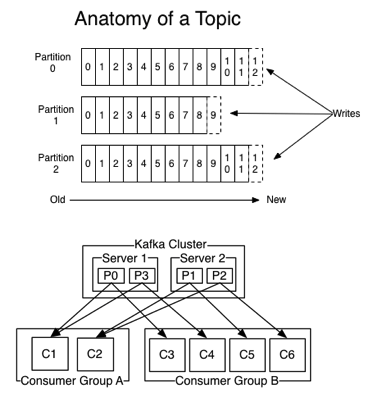
Partition:分區,解決伸縮性問題,多個Partition組成一個Topic
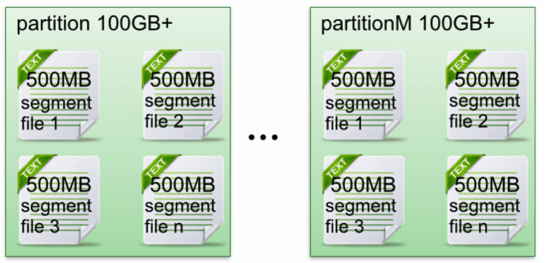
Segment:partition 有多個 segment 組成
消息日志(Log)保存數據,磁盤追加寫(Append-only)避免緩慢的隨機I/O操作高吞吐
定期刪除消息(日志段)
https://www.open-open.com/lib/view/open1421150566328.html
每個 partition 相當于一個巨型文件→多個大小相等 segment 數據文件中
每個 partition 只需要順序讀寫就行了,segment 文件生命周期由配置決定
segment file 組成:index file:索引文件data file:數據文件
segment file 文件命名規則:全局第一個 segment 是 0后序每個加上全局 partition 的最大 offset

一對 segment file

message 物理結構

Kafka的消息組織方式:主題-分區-消息
一條消息,僅存在某一個分區中
提高伸縮性,不同分區可以放到不同機器,讀寫操作也是以分區粒度
輪詢
隨機
按 key 保序,單分區有序
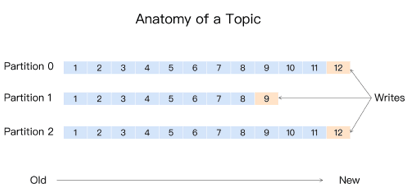
只對“已提交”的消息做有限度的持久化保證已提交的消息:消息寫入日志文件有限度的持久化保證:N個 broker 至少一個存活
生產者丟失數據producer.send(msg) 異步發送消息,不保證數據到達Kafkaproducer.send(msg, callback) 判斷回調
消費者程序丟失數據應該「先消費消息,后更新位移的順序」新問題:消息的重復處理多線程異步處理消息,Consumer不要開啟自動提交位移,應用程序手動提交位移
在 ZooKeeper幫助下管理和協調整個 Kafka 集群
運行過程中,只能有一個 Broker 成為控制器
在 ZooKeeper 創建 /controller 節點,第一個創建成功的 Broker 被指定為控制器。
主題管理(創建、刪除、增加分區)
分區重分配
領導者選舉
集群成員管理(新增 Broker、Broker 主動關閉、Broker 宕機)(ZooKeeper 臨時節點)
數據服務:最全的集群元數據信息
只有一個 Broker 當控制器,單點失效,立即啟用備用控制器


團隊內部,某些操作要同時更新多個數據源
業務團隊 A 完成某個操作后,B 業務的某個操作也必須完成,A 業務并不能直接訪問 B 的數據庫
公司之間,用戶付款后,支付系統(支付寶/微信)必須通知商家的系統更新訂單狀態
先完成數據源 A 的事務(一階段)
成功后通過某種機制,保證數據源 B 的事務(二階段)也一定最終完成不成功,會不斷重試直到成功為止或達到一定重試次數后停止(配合對賬、人工處理)
為了保證最終一致,消息系統和業務程序需要保證:
消息發送的一致性:消息發送時,一階段事務和消息發送必須同時成功或失敗
消息存儲不丟失:消息發送成功后,到消息被成功消費前,消息服務器(broker)必須存儲好消息,保證發生故障時,消息不丟失
消費者不丟失消息:處理失敗不丟棄,重試直到成功為止
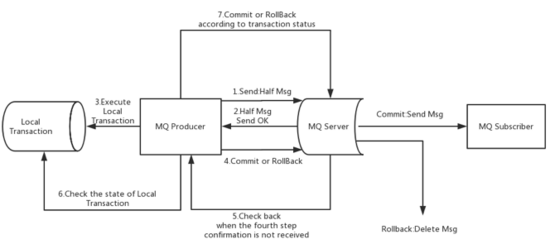
目標 :本地事務、消息發送必須同時成功/失敗
問題
先執行本地事務,再發送消息,消息可能發送失敗
可把失敗的消息放入內存,稍后重試,但成功率也無法達到 100%
解決方案`* 先發送半消息(Half Msg,類似 Prepare 操作),不會投遞給消費者
半消息發送成功,再執行 DB 操作
DB 操作執行成功后,提交半消息
1 異常,半消息發送失敗,本地 DB 沒有執行,整個操作失敗,DB/消息的狀態一致(都沒有提交)
2 異常/超市生產者以為失敗了,不執行 DBbroker 存儲半消息成功,等不到后續操作,會詢問生產者是提交還是回滾(第6步)
3 DB操作失敗:生產者在第 4 步告知 broker 回滾半消息
4 提交/回滾半消息失敗:broker 等不到這個操作,觸發回查(第 6 步)
5、6、7回查失敗:RocketMQ 最多回查 15 次
上述就是小編為大家分享的消息中間件Kafka、RocketMQ該怎么理解了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





