溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Apache Flink on K8s的四種運行模式分別是什么,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
Apache Flink 是一個分布式流處理引擎,它提供了豐富且易用的API來處理有狀態的流處理應用,并且在支持容錯的前提下,高效、大規模的運行此類應用。通過支持事件時間(event-time)、計算狀態(state)以及恰好一次(exactly-once)的容錯保證,Flink迅速被很多公司采納,成為了新一代的流計算處理引擎。
Kubernetes 項目源自 Google 內部 Borg 項目,基于 Borg 多年來的優秀實踐和其超前的設計理念,并憑借眾多豪門、大廠的背書,時至今日,Kubernetes 已經成長為容器管理領域的事實標準。在大數據及相關領域,包括 Spark,Hive,Airflow,Kafka 等眾多知名產品正在遷往 Kubernetes,Apache Flink 也是其中一員。
Flink 選擇 Kubernetes 作為其底層資源管理平臺,原因包括兩個方面:
1)Flink 特性:流式服務一般是常駐進程,經常用于電信網質量監控、商業數據即席分析、實時風控和實時推薦等對穩定性要求比較高的場景;
2)Kubernetes 優勢:為在線業務提供了更好的發布、管理機制,并保證其穩定運行,同時 Kubernetes 具有很好的生態優勢,能很方便的和各種運維工具集成,如 prometheus 監控,主流的日志采集工具等;同時 K8S 在資源彈性方面提供了很好的擴縮容機制,很大程度上提高了資源利用率。
在 Flink 的早期發行版 1.2 中,已經引入了 Flink Session 集群模式,用戶得以將 Flink 集群部署在 Kubernetes 集群之上。
隨著 Flink 的逐漸普及,越來越多的 Flink 任務被提交在用戶的集群中,用戶發現在 session 模式下,任務之間會互相影響,隔離性比較差,因此在 Flink 1.6 版本中,推出了 Per Job 模式,單個任務獨占一個 Flink 集群,很大的程度上提高了任務的穩定性。
在滿足了穩定性之后,用戶覺得這兩種模式,沒有做到資源按需創建,往往需要憑用戶經驗來事先指定 Flink 集群的規格,在這樣的背景之下,native session 模式應用而生,在 Flink 1.10 版本進入 Beta 階段,我們增加了 native per job 模式,在資源按需申請的基礎上,提高了應用之間的隔離性。
根據 Flink 在 Kubernetes 集群上的運行模式的趨勢,依次分析了這些模式的特點,并在最后介紹了 Flink operator 方案及其優勢。
首先分析了 Apache Flink 1.10 在 Kubernetes 集群上已經GA(生產可用)的兩種部署模式,然后分析了處于 Beta 版本的 native session 部署模式和即將在 Flink 1.11 發布的 native per-job 部署模式,最后根據這些部署模式的利弊,介紹了當前比較 native kubernetes 的部署方式,flink-operator。
我們正在使用的 Flink 版本已經很好的支持了 native session 和 native per-job 兩種模式,在 flink-operator 中,我們也對這兩種模式也做了支持。
接下來將按照以下順序分析了 Flink 的運行模式,讀者可以結合自身的業務場景,考量適合的 Flink 運行模式。
Flink session 模式
Flink per-job 模式
Flink native session 模式
Flink native per-job 模式
這四種部署模式的優缺點對比,可以用如下表格來概括,更多的內容,請參考接下來的詳細描述。
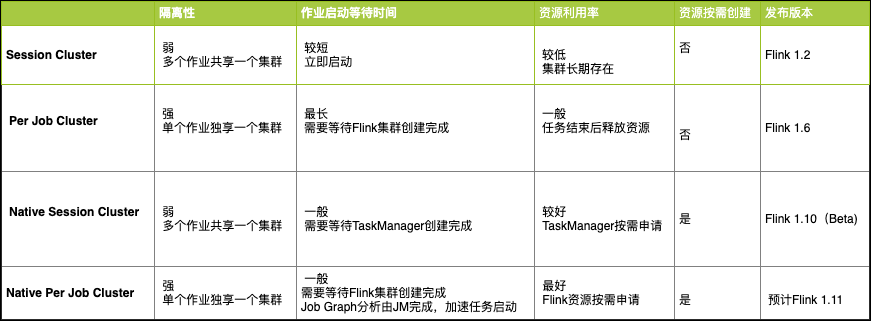
2.1.1 原理簡介
Session 模式下,Flink 集群處于長期運行狀態,當集群的Master組件接收到客戶端提交的任務后,對任務進行分析并處理。用戶將Flink集群的資源描述文件提交到 Kubernetes 之后,Flink 集群的 FlinkMaster 和 TaskManager 會被創建出來,如下圖所示,TaskManager 啟動后會向 ResourceManager 模塊注冊,這時 Flink Session 集群已經準備就緒。當用戶通過 Flink Clint 端提交了 Job 任務時,Dispatcher 收到該任務請求,將請求轉發給 JobMaster,由 JobMaster 將任務分配給具體的 TaskManager。
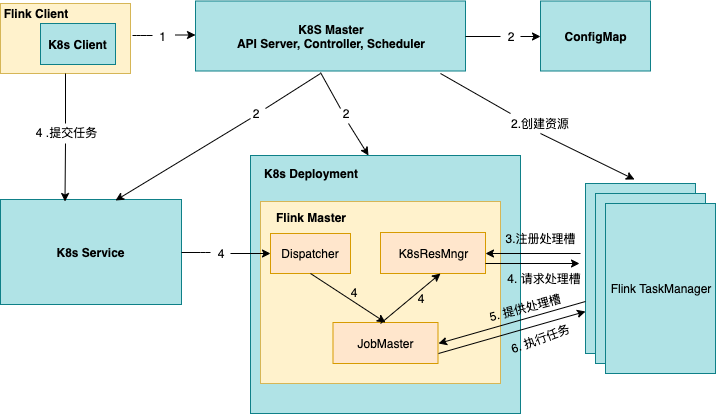
2.1.2 特點分析
這種類型的 Flink 集群,FlinkMaster 和 TaskManager 是以Kubernetes deployment的形式長期運行在 Kubernetes 集群中。在提交作業之前,必須先創建好 Flink session 集群。多個任務可以同時運行在同一個集群內,任務之間共享 K8sResourceManager 和 Dispatcher,但是 JobMaster 是單獨的。這種方式比較適合運行短時作業、即席查詢、任務提交頻繁、或者對任務啟動時長比較敏感的場景。
**優點:**作業提交的時候,FlinkMaster 和 TaskManager已經準備好了,當資源充足時,作業能夠立即被分配到 TaskManager 執行,無需等待 FlinkMaster,TaskManager,Service 等資源的創建;
缺點:1)需要在提交 Job 任務之前先創建 Flink 集群,需要提前指定 TaskManager 的數量,但是在提交任務前,是難以精準把握具體資源需求的,指定的多了,會有大量 TaskManager 處于閑置狀態,資源利用率就比較低,指定的少了,則會有任務分配不到資源,只能等集群中其他作業執行完成后,釋放了資源,下一個作業才會被正常執行。
隔離性比較差,多個 Job 任務之間存在資源競爭,互相影響;如果一個 Job 異常導致 TaskManager crash 了,那么所有運行在這個 TaskManager 上的 Job 任務都會被重啟;進而,更壞的情況是,多個 Jobs 任務的重啟,大量并發的訪問文件系統,會導致其他服務的不可用;最后一點是,在 Rest interface 上是可以看到同一個 session 集群里其他人的 Job 任務。
顧名思義,這種方式會專門為每個 Job 任務創建一個單獨的 Flink 集群,當資源描述文件被提交到 Kubernetes 集群, Kubernetes 會依次創建 FlinkMaster Deployment、TaskManagerDeployment 并運行任務,任務完成后,這些 Deployment 會被自動清理。
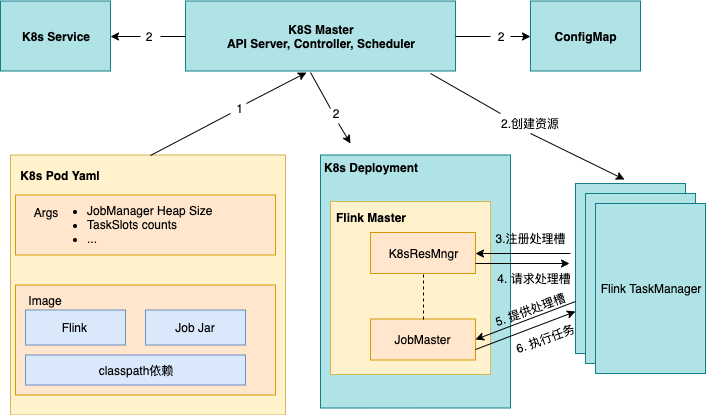
2.2.1 特點分析
優點:隔離性比較好,任務之間資源不沖突,一個任務單獨使用一個 Flink 集群;相對于 Flink session 集群而且,資源隨用隨建,任務執行完成后立刻銷毀資源,資源利用率會高一些;
缺點:需要提前指定 TaskManager 的數量,如果 TaskManager 指定的少了會導致作業運行失敗,指定的多了仍會降低資源利用率;資源是實時創建的,用戶的作業在被運行前,需要先等待以下過程:
· Kubernetes scheduler為FlinkMaster和 TaskManager 申請資源并調度到宿主機上進行創建;
· Kubernetes kubelet拉取FlinkMaster、TaskManager 鏡像,并創建出FlinkMaster、TaskManager容器;
· TaskManager啟動后,向Flink ResourceManager 注冊。
這種模式比較適合對啟動時間不敏感、且長時間運行的作業。不適合對任務啟動時間比較敏感的場景。
2.3.1 原理分析
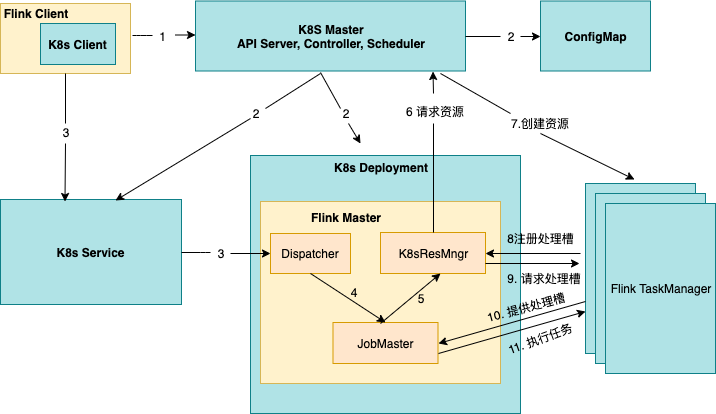
Flink提供了Kubernetes模式的入口腳本 kubernetes-session.sh,當用戶執行了該腳本之后,Flink 客戶端會生成 Kubernets 資源描述文件,包括 FlinkMaster Service,FlinkMasterDeloyment,Configmap,Service并設置了owner reference,在 Flink 1.10 版本中,是將 FlinkMaster Service 作為其他資源的 Owner,也就意味著在刪除 Flink 集群的時候,只需要刪除 FlinkMaster service,其他資源則會被以及聯的方式自動刪除;
Kubernetes 收到來自 Flink 的資源描述請求后,開始創建FlinkMaster Service,FlinkMaster Deloyment,以及 Configmap 資源,從圖中可以看到,伴隨著 FlinkMaster 的創建,Dispatch 和K8sResMngr 組件也同時被創建了,這里的 K8sResMngr 就是 Native 方式的核心組件,正是這個組件去和 Kubernetes API server 進行通信,申請 TaskManager 資源;當前,用戶已經可以向Flink 集群提交任務請求了;
用戶通過 Flink client 向 Flink 集群提交任務,flink client 會生成 Job graph,然后和 jar 包一起上傳;當任務提交成功后,JobSubmitHandler 收到了請求并提交給 Dispatcher并生成 JobMaster, JobMaster 用于向 KubernetesResourceManager 申請 task 資源;
Kubernetes-Resource-Manager 會為 taskmanager 生成一個新的配置文件,包含了 service 的地址,這樣當 Flink Master 異常重建后,能保證 taskmanager 通過 Service 仍然能連接到新的 Flink Master;
TaskManager 創建成功后注冊到 slotManager,這時 slotManager向TaskManager 申請 slots,TaskManager 提供自己的空閑 slots,任務被部署并運行;
2.3.2. 特點分析
之前我們提到的兩種部署模式,在 Kubernetes 上運行 Flink 任務是需要事先指定好 TaskManager 的數量,但是大部分情況下,用戶在任務啟動前是無法準確的預知該任務所需的 TaskManager 數量和規格。
指定的多了會資源浪費,指定的少了會導致任務的執行失敗。最根本的原因,就是沒有 Native 的使用 Kubernetes 資源,這里的 Native,可以理解為 Flink 直接與 Kuberneter 通信來申請資源。
這種類型的集群,也是在提交任務之前就創建好了,不過只包含了 FlinkMaster 及其 Entrypoint(Service),當任務提交的時候,Flink client 會根據任務計算出并行度,進而確定出所需 TaskManager 的數量,然后 Flink 內核會直接向 Kubernetes API server 申請 taskmanager,達到資源動態創建的目的。
優點:相對于前兩種集群而言,taskManager 的資源是實時的、按需進行的創建,對資源的利用率更高,所需資源更精準。
缺點:taskManager 是實時創建的,用戶的作業真正運行前, 與 Per Job集群一樣, 仍需要先等待 taskManager 的創建, 因此對任務啟動時間比較敏感的用戶,需要進行一定的權衡。
在當前的 Apache Flink 1.10 版本里,Flink native per-job 特性尚未發布,預計在后續的 Flink 1.11 版本中提供,我們可以提前一覽 native per job 的特性。
2.4.1 原理分析

當任務被提交后,同樣由 Flink 來向 kubernetes 申請資源,其過程與之前提到的 native session 模式相似,不同之處在于:
Flink Master是隨著任務的提交而動態創建的;
用戶可以將 Flink、作業 Jar 包和 classpath 依賴打包到自己的鏡像里;
作業運行圖由 Flink Master 生成,所以無需通過 RestClient 上傳 Jar 包(圖 2 步驟 3)。
2.4.2. 特點分析
native per-job cluster 也是任務提交的時候才創建 Flink 集群,不同的是,無需用戶指定 TaskManager 資源的數量,因為同樣借助了 Native 的特性,Flink 直接與 Kubernetes 進行通信并按需申請資源。
優點:資源按需申請,適合一次性任務,任務執行后立即釋放資源,保證了資源的利用率;
缺點:資源是在任務提交后開始創建,同樣意味著對于提交任務后對延時比較敏感的場景,需要一定的權衡;
分析以上四種部署模式,我們發現,對于 Flink 集群的使用,往往需要用戶自行維護部署腳本,向 Kubernetes 提交各種所需的底層資源描述文件(Flink Master,TaskManager,配置文件,Service)。
在 session cluster 下,如果集群不再使用,還需要用戶自行刪除這些的資源,因為這類集群的資源使用了 Kubernetes 的垃圾回收機制 owner reference,在刪除 Flink 集群的時候,需要通過刪除資源的 Owner 來進行及聯刪除,這對于不熟悉 Kubernetes 的 Flink 用戶來說,就顯得不是很友好了。
而通過 Flink-operator,我們可以把 Flink 集群描述成 yaml 文件,這樣,借助 Kubernetes 的聲明式特性和協調控制器,我們可以直接管理 Flink 集群及其作業,而無需關注底層資源如 Deployment,Service,ConfigMap 的創建及維護。
當前 Flink 官方還未給出 flink-operator 方案,不過 GoogleCloudPlatform 提供了一種基于 kubebuilder 構建的 flink-operator方案。接下來,將介紹 flink-operator 的安裝方式和對 Flink 集群的管理示例。
當 Fink operator 部署至 Kubernetes 集群后, FlinkCluster 資源和 Flink Controller 被創建。其中 FlinkCluster 用于描述 Flink 集群,如 JobMaster 規格、TaskManager 和 TaskSlot 數量等;Flink Controller 實時處理針對 FlinkCluster 資源的 CRUD 操作,用戶可以像管理內置 Kubernetes 資源一樣管理 Flink 集群。
例如,用戶通過 yaml 文件描述期望的 Flink 集群并向 Kubernetes 提交,Flink controller 分析用戶的 yaml,得到 FlinkCluster CR,然后調用 API server 創建底層資源,如JobMaster Service, JobMaster Deployment,TaskManager Deployment。
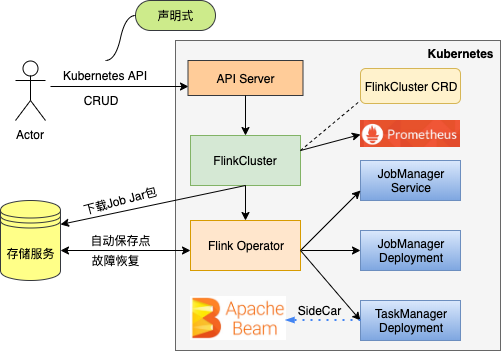
通過使用 Flink Operator,有如下優勢:
1. 管理 Flink 集群更加便捷
flink-operator 更便于我們管理 Flink 集群,我們不需要針對不同的 Flink 集群維護 Kubenretes 底層各種資源的部署腳本,唯一需要的,就是 FlinkCluster 的一個自定義資源的描述文件。創建一個 Flink session 集群,只需要一條 kubectl apply 命令即可,下圖是 Flink Session集群的 yaml 文件,用戶只需要在該文件中聲明期望的 Flink 集群配置,flink-operator 會自動完成 Flink 集群的創建和維護工作。如果創建 Per Job 集群,也只需要在該 yaml 中聲明 Job 的屬性,如 Job 名稱,Jar 包路徑即可。通過 flink-operator,上文提到的四種 Flink 運行模式,分別對應一個 yaml 文件即可,非常方便。
apiVersion: flinkoperator.k8s.io/v1beta1kind: FlinkClustermetadata: name: flinksessioncluster-samplespec: image: name: flink:1.10.0 pullPolicy: IfNotPresent jobManager: accessScope: Cluster ports: ui: 8081 resources: limits: memory: "1024Mi" cpu: "200m" taskManager: replicas: 1 resources: limits: memory: "2024Mi" cpu: "200m" volumes: - name: cache-volume emptyDir: {} volumeMounts: - mountPath: /cache name: cache-volume envVars: - name: FOO value: bar flinkProperties: taskmanager.numberOfTaskSlots: "1"2. 聲明式
通過執行腳本命令式的創建 Flink 集群各個底層資源,需要用戶保證資源是否依次創建成功,往往伴隨著輔助的檢查腳本。借助 flink operator 的控制器模式,用戶只需聲明所期望的 Flink 集群的狀態,剩下的工作全部由 Flink operator 來保證。在 Flink 集群運行的過程中,如果出現資源異常,如 JobMaster 意外停止甚至被刪除,Flink operator 都會重建這些資源,自動的修復 Flink 集群。
3. 自定義保存點
用戶可以指定 autoSavePointSeconds 和保存路徑,Flink operator 會自動為用戶定期保存快照。
4. 自動恢復
流式任務往往是長期運行的,甚至 2-3 年不停止都是常見的。在任務執行的過程中,可能會有各種各樣的原因導致任務失敗。用戶可以指定任務重啟策略,當指定為 FromSavePointOnFailure,Flink operator 自動從最近的保存點重新執行任務。
5. sidecar containers
sidecar 容器也是 Kubernetes 提供的一種設計模式,用戶可以在 TaskManager Pod 里運行 sidecar 容器,為 Job 提供輔助的自定義服務或者代理服務。
6. Ingress 集成
用戶可以定義 Ingress 資源,flink operator 將會自動創建 Ingress 資源。云廠商托管的 Kubernetes 集群一般都有 Ingress 控制器,否則需要用戶自行實現 Ingress controller。
7. Prometheus 集成
通過在 Flink 集群的 yaml 文件里指定 metric exporter 和 metric port,可以與 Kubernetes 集群中的 Prometheus 進行集成。
上述就是小編為大家分享的Apache Flink on K8s的四種運行模式分別是什么了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





