溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章將為大家詳細講解有關怎么看懂Spark的基本原理,文章內容質量較高,因此小編分享給大家做個參考,希望大家閱讀完這篇文章后對相關知識有一定的了解。
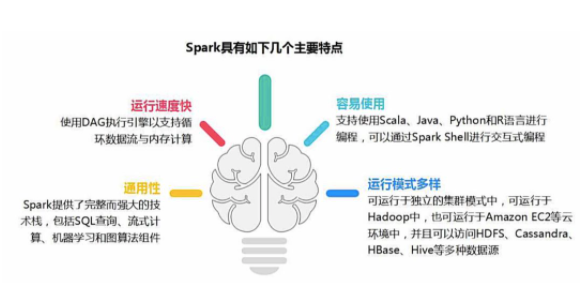
作為大數據計算框架MapReduce的繼任者,Spark具備以下優勢特性。
1,高效性
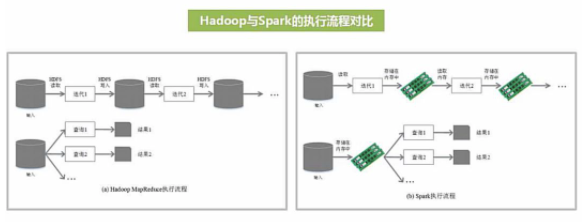
不同于MapReduce將中間計算結果放入磁盤中,Spark采用內存存儲中間計算結果,減少了迭代運算的磁盤IO,并通過并行計算DAG圖的優化,減少了不同任務之間的依賴,降低了延遲等待時間。內存計算下,Spark 比 MapReduce 快100倍。
2,易用性
不同于MapReduce僅支持Map和Reduce兩種編程算子,Spark提供了超過80種不同的Transformation和Action算子,如map,reduce,filter,groupByKey,sortByKey,foreach等,并且采用函數式編程風格,實現相同的功能需要的代碼量極大縮小。

3,通用性
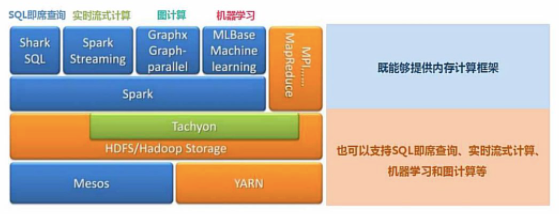
Spark提供了統一的解決方案。Spark可以用于批處理、交互式查詢(Spark SQL)、實時流處理(Spark Streaming)、機器學習(Spark MLlib)和圖計算(GraphX)。
這些不同類型的處理都可以在同一個應用中無縫使用。這對于企業應用來說,就可使用一個平臺來進行不同的工程實現,減少了人力開發和平臺部署成本。
4,兼容性
Spark能夠跟很多開源工程兼容使用。如Spark可以使用Hadoop的YARN和Apache Mesos作為它的資源管理和調度器,并且Spark可以讀取多種數據源,如HDFS、HBase、MySQL等。
RDD:是彈性分布式數據集(Resilient Distributed Dataset)的簡稱,是分布式內存的一個抽象概念,提供了一種高度受限的共享內存模型。
DAG:是Directed Acyclic Graph(有向無環圖)的簡稱,反映RDD之間的依賴關系。
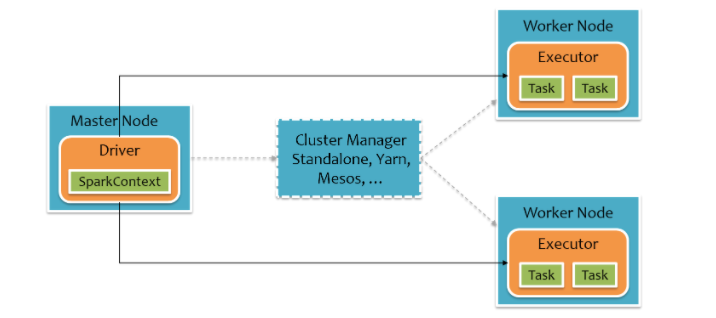
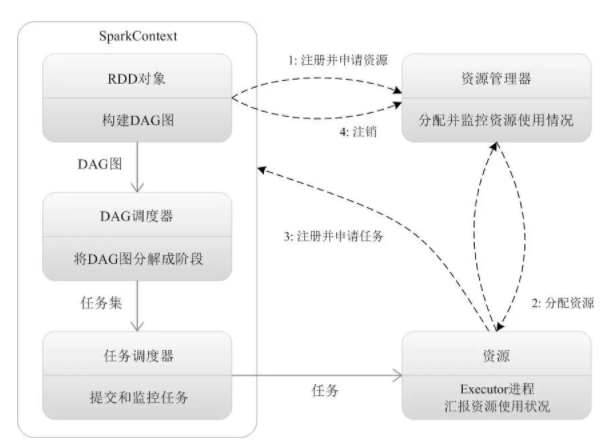
Driver Program:控制程序,負責為Application構建DAG圖。
Cluster Manager:集群資源管理中心,負責分配計算資源。
Worker Node:工作節點,負責完成具體計算。
Executor:是運行在工作節點(Worker Node)上的一個進程,負責運行Task,并為應用程序存儲數據。
Application:用戶編寫的Spark應用程序,一個Application包含多個Job。
Job:作業,一個Job包含多個RDD及作用于相應RDD上的各種操作。
Stage:階段,是作業的基本調度單位,一個作業會分為多組任務,每組任務被稱為“階段”。
Task:任務,運行在Executor上的工作單元,是Executor中的一個線程。
總結:Application由多個Job組成,Job由多個Stage組成,Stage由多個Task組成。Stage是作業調度的基本單位。

Spark集群由Driver, Cluster Manager(Standalone,Yarn 或 Mesos),以及Worker Node組成。對于每個Spark應用程序,Worker Node上存在一個Executor進程,Executor進程中包括多個Task線程。
對于pyspark,為了不破壞Spark已有的運行時架構,Spark在外圍包裝一層Python API。在Driver端,借助Py4j實現Python和Java的交互,進而實現通過Python編寫Spark應用程序。在Executor端,則不需要借助Py4j,因為Executor端運行的Task邏輯是由Driver發過來的,那是序列化后的字節碼。
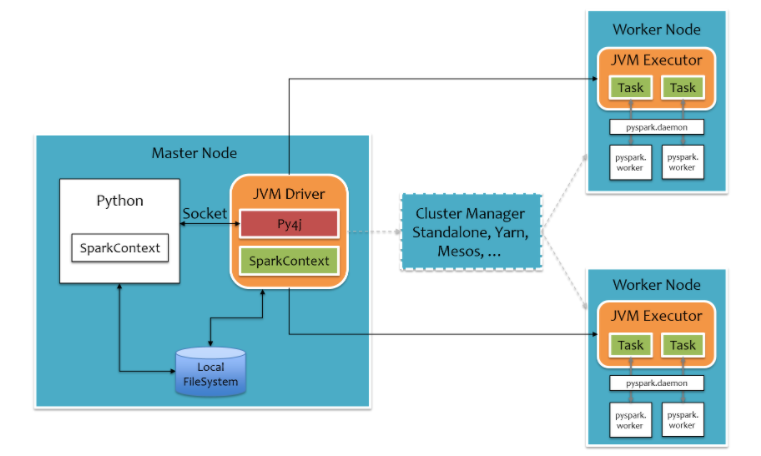
1,Application首先被Driver構建DAG圖并分解成Stage。
2,然后Driver向Cluster Manager申請資源。
3,Cluster Manager向某些Work Node發送征召信號。
4,被征召的Work Node啟動Executor進程響應征召,并向Driver申請任務。
5,Driver分配Task給Work Node。
6,Executor以Stage為單位執行Task,期間Driver進行監控。
7,Driver收到Executor任務完成的信號后向Cluster Manager發送注銷信號。
8,Cluster Manager向Work Node發送釋放資源信號。
9,Work Node對應Executor停止運行。

Local:本地運行模式,非分布式。
Standalone:使用Spark自帶集群管理器,部署后只能運行Spark任務。
Yarn:Haoop集群管理器,部署后可以同時運行MapReduce,Spark,Storm,Hbase等各種任務。
Mesos:與Yarn最大的不同是Mesos 的資源分配是二次的,Mesos負責分配一次,計算框架可以選擇接受或者拒絕。
RDD全稱Resilient Distributed Dataset,彈性分布式數據集,它是記錄的只讀分區集合,是Spark的基本數據結構。
RDD代表一個不可變、可分區、里面的元素可并行計算的集合。
一般有兩種方式創建RDD,第一種是讀取文件中的數據生成RDD,第二種則是通過將內存中的對象并行化得到RDD。
#通過讀取文件生成RDD
rdd = sc.textFile("hdfs://hans/data_warehouse/test/data")
#通過將內存中的對象并行化得到RDD
arr = [1,2,3,4,5]
rdd = sc.parallelize(arr)
創建RDD之后,可以使用各種操作對RDD進行編程。
RDD的操作有兩種類型,即Transformation操作和Action操作。轉換操作是從已經存在的RDD創建一個新的RDD,而行動操作是在RDD上進行計算后返回結果到 Driver。
Transformation操作都具有 Lazy 特性,即 Spark 不會立刻進行實際的計算,只會記錄執行的軌跡,只有觸發Action操作的時候,它才會根據 DAG 圖真正執行。
操作確定了RDD之間的依賴關系。
RDD之間的依賴關系有兩種類型,即窄依賴和寬依賴。窄依賴時,父RDD的分區和子RDD的分區的關系是一對一或者多對一的關系。而寬依賴時,父RDD的分區和自RDD的分區是一對多或者多對多的關系。
寬依賴關系相關的操作一般具有shuffle過程,即通過一個Patitioner函數將父RDD中每個分區上key不同的記錄分發到不同的子RDD分區。
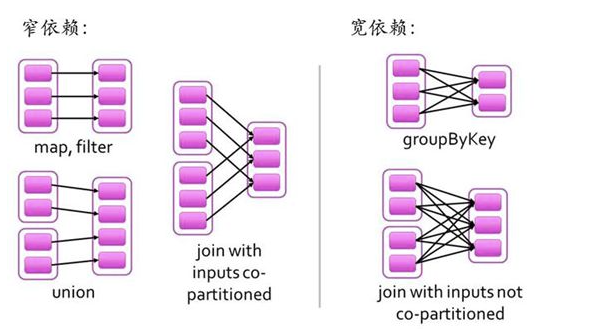
依賴關系確定了DAG切分成Stage的方式。
切割規則:從后往前,遇到寬依賴就切割Stage。
RDD之間的依賴關系形成一個DAG有向無環圖,DAG會提交給DAGScheduler,DAGScheduler會把DAG劃分成相互依賴的多個stage,劃分stage的依據就是RDD之間的寬窄依賴。遇到寬依賴就劃分stage,每個stage包含一個或多個task任務。然后將這些task以taskSet的形式提交給TaskScheduler運行。

import findspark
#指定spark_home為剛才的解壓路徑,指定python路徑
spark_home = "/Users/liangyun/ProgramFiles/spark-3.0.1-bin-hadoop3.2"
python_path = "/Users/liangyun/anaconda3/bin/python"
findspark.init(spark_home,python_path)
import pyspark
from pyspark import SparkContext, SparkConf
conf = SparkConf().setAppName("test").setMaster("local[4]")
sc = SparkContext(conf=conf)
只需要5行代碼就可以完成WordCount詞頻統計。
rdd_line = sc.textFile("./data/hello.txt")
rdd_word = rdd_line.flatMap(lambda x:x.split(" "))
rdd_one = rdd_word.map(lambda t:(t,1))
rdd_count = rdd_one.reduceByKey(lambda x,y:x+y)
rdd_count.collect()
[('world', 1),
('love', 3),
('jupyter', 1),
('pandas', 1),
('hello', 2),
('spark', 4),
('sql', 1)]關于怎么看懂Spark的基本原理就分享到這里了,希望以上內容可以對大家有一定的幫助,可以學到更多知識。如果覺得文章不錯,可以把它分享出去讓更多的人看到。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





