溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Rainbond怎樣實現部署Spark Standalone 集群,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
Standalone 是 Spark 自身提供的一種主從集群部署模式。本文講述一個常規1主多從的集群部署模式,該模式下master服務依靠Rainbond平臺監控保障其可用性,支持重新調度重啟。 worker服務可以根據需要伸縮多個節點。
部署效果截圖如下:
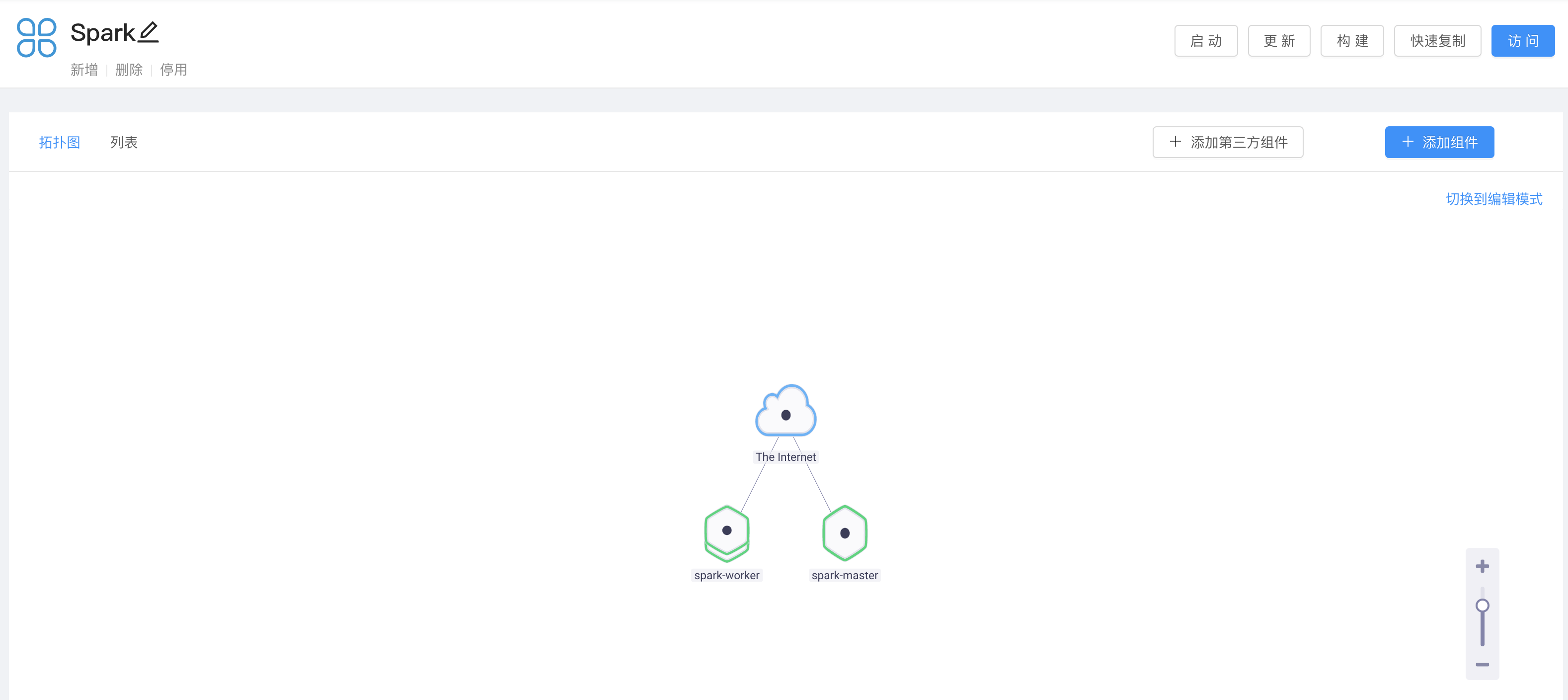
<center>Rainbond 部署效果圖</center>
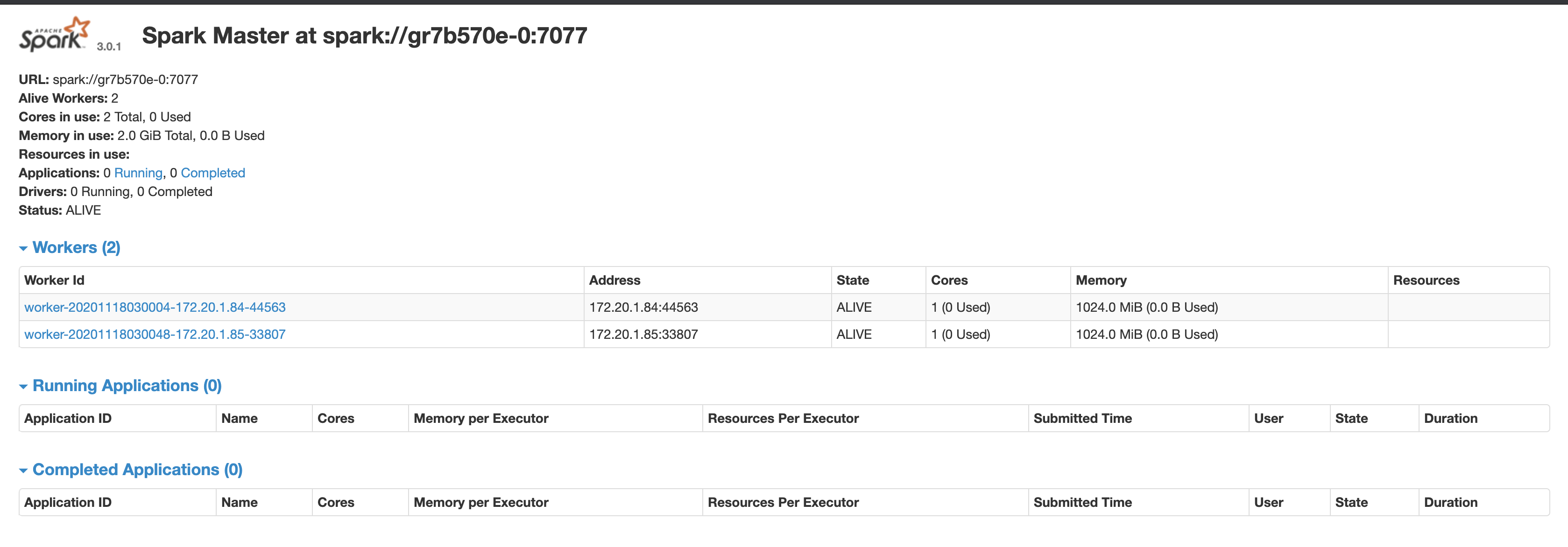
<center>Spark master UI 圖</center>
開始前,你需要完成Rainbond平臺的安裝和搭建,參考Rainbond 安裝與部署 本參考文檔適合已掌握Rainbond 基礎操作的同學,因此如果你還剛接觸Rainbond平臺,請先參考 Rainbond 快速入門指南
部署spark-master,采用Rainbond基于Docker鏡像創建組件:
bde2020/spark-master:3.0.1-hadoop3.2
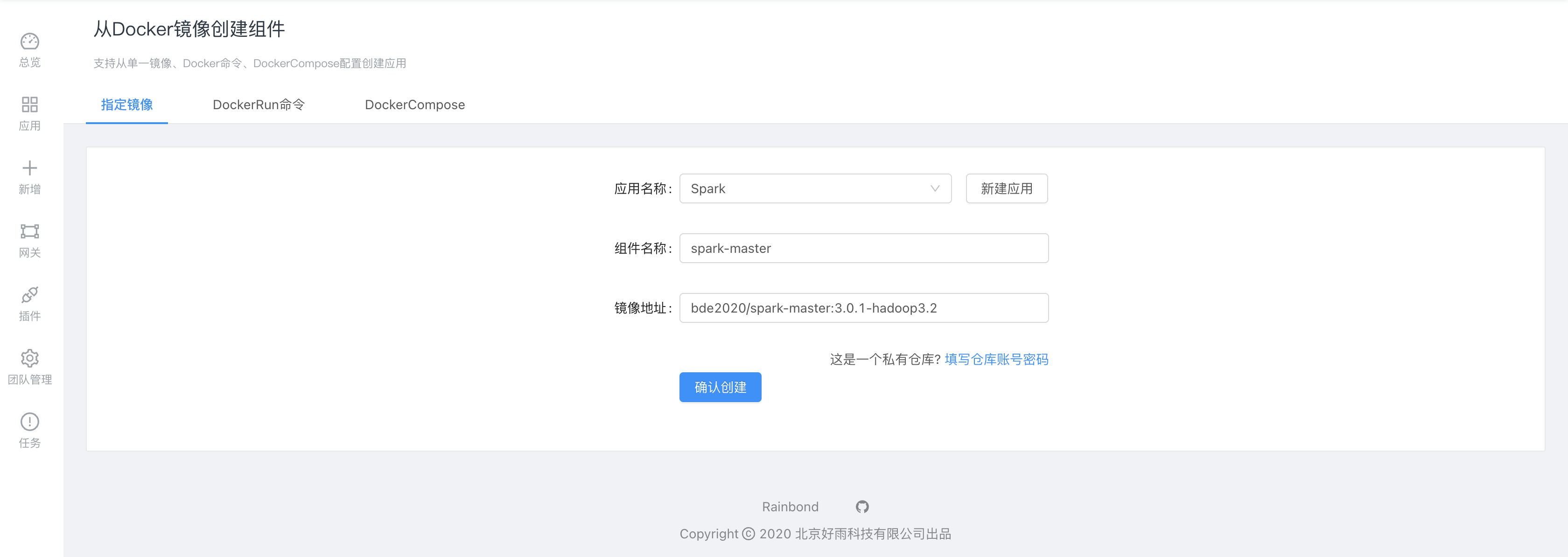
確認創建檢測成功后選擇高級設置進行三個特殊設置。
在環境變量模塊中添加環境變量
SPARK_DAEMON_JAVA_OPTS=-Dspark.deploy.recoveryMode=FILESYSTEM -Dspark.deploy.recoveryDirectory=/data
我們需要設置spark-master為“Recovery with Local File System”模式。可以在master發生重啟后從持久化文件中恢復數據,保持master服務的可用性。
在存儲設置中添加共享存儲 /data 持久化master的數據,使其可以重啟后恢復。
在端口管理中將 8080端口的對外服務打開,組件啟動成功后即可訪問master的UI。
在部署屬性中選擇組件類型為有狀態單實例
部署為有狀態組件后,其可以獲得一個穩定的內部訪問域名,供worker組件連接。有狀態服務控制權可以保障master節點不會重復啟動多個實例。
設置完成后選擇確認創建即可啟動master服務。
組件成功點擊訪問即可打開master UI。如上圖所示,我們可以在UI中獲取到master服務的訪問地址是:spark://gr7b570e:7077 ,注意UI上顯示的地址是spark://gr7b570e-0:7077 我們需要使用的是spark://gr7b570e:7077 ,復制并記錄這個地址。
注意,地址實際值請查看你的UI顯示,這里只是舉例說明。
部署spark-worker,采用基于Docker-run命令創建組件,這種創建方式可以直接設置一些必要屬性:
docker run -it -e SPARK_MASTER=spark://gr7b570e:7077 -e SPARK_WORKER_MEMORY=1g bde2020/spark-worker:3.0.1-hadoop3.2
如上創建方式指定了兩個環境變量。
SPARK_MASTER 指定的是master的地址,由上一步創建的組件獲取。
SPARK_WORKER_MEMORY 設置worker單個實例的內存量,這個根據每個實例分配的內存進行設置即可。比如每個實例分配1GB, 則設置SPARK_WORKER_MEMORY=1g 。如果不設置此變量,服務會自動讀取操作系統的內存量。由于我們是采用的容器部署方式,讀取的值會是宿主機的全部內存。將遠大于worker實例實際分配的可用內存值。
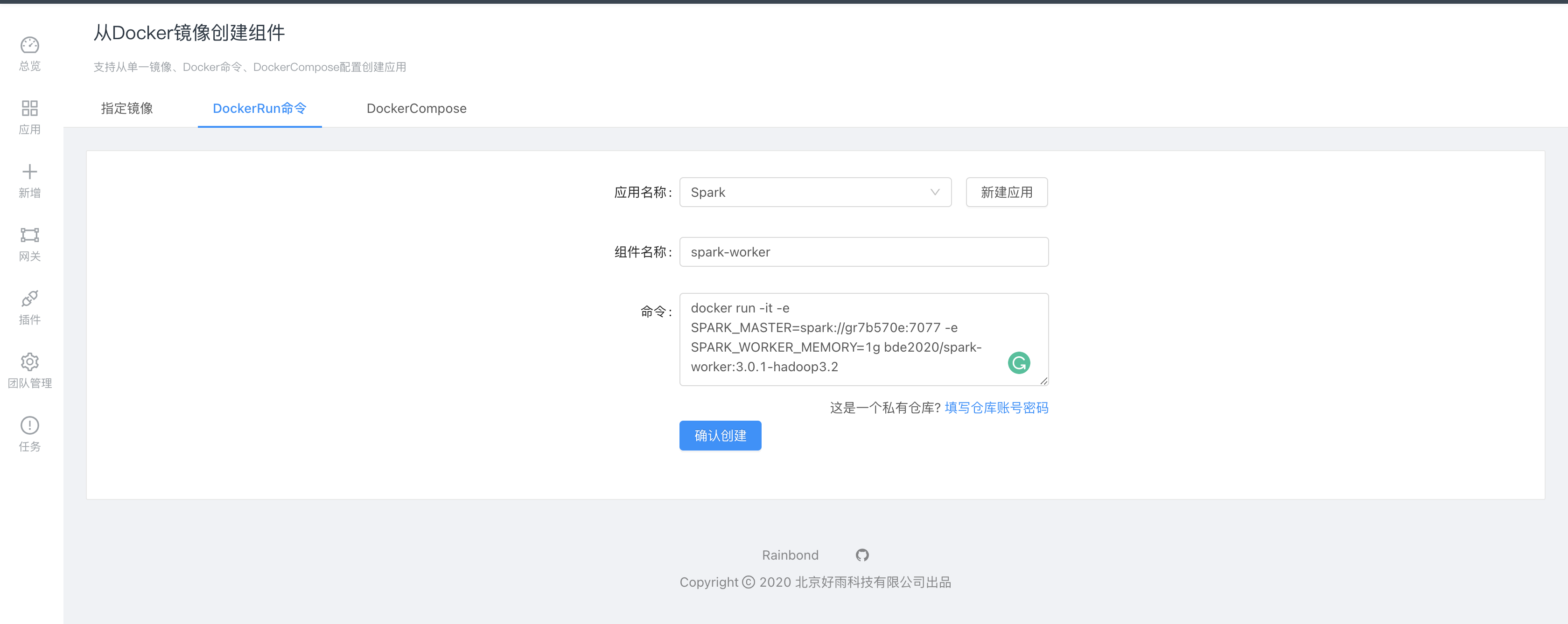
同樣進入高級設置,設置組件部署模式為 有狀態多實例。
確認創建組件,啟動成功后即可在組件的伸縮頁面中設置worker的運行實例數。
到此,我們的Spark集群已部署完成。
<b>就近數據處理原則逐步打破</b>
過去我們更偏愛于把數據處理服務(hadoop、yarn等)部署到離數據最近的地方。主要原因是hadoop計算數據的模式對IO消耗較多,如果數據與計算分類,網絡IO帶來的消耗將更大,對網絡帶寬要求較大。
但Spark機制不同,Spark計算模式是將數據盡可能緩存到內存中,也就意味著Spark消耗的資源主要是內存和CPU。然后存儲數據的設備內存和CPU配屬不一定充足。因此數據與計算分離將是更好的選擇。
<b>數據與計算分離后的更多選擇</b>
數據與計算分離是指計算服務單獨部署,存儲服務通過網絡為計算服務提供數據。通過網絡也就意味著可以有多種協議模式可選,除了傳統的HDFS,目前常用的就是對象存儲,比如兼容S3的各類服務,也可以是分布式文件系統,可以根據數據類型和實際需要合理選擇。計算服務(spark worker) 可以根據任務的需要靈活的在分布式集群中分配計算資源。
Spark 基于 ZooKeeper可以提供master服務的主備切換。 配置方式也比較簡單。
Rainbond 云原生應用管理平臺,實現微服務架構不用改代碼,管理 Kubernetes 不用學容器,幫企業實現應用上云,一站式將任何企業應用持續交付到 Kubernetes 集群、混合云、多云等基礎設施。是 Rainstore 云原生應用商店的支撐平臺。
上述就是小編為大家分享的Rainbond怎樣實現部署Spark Standalone 集群了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





