溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這期內容當中小編將會給大家帶來有關Python如何爬取貓咪網站交易數據,文章內容豐富且以專業的角度為大家分析和敘述,閱讀完這篇文章希望大家可以有所收獲。
看到可愛的貓咪表情包,總是會忍不住收藏,曬部分圖如下:

從這個網站里爬取了貓貓品種介紹的數據,以及 20W+ 條貓貓交易數據,以此來了解一下可愛的貓咪。
打開貓貓交易網,先爬取貓咪品種數據,打開頁面可以看到貓貓品種列表:
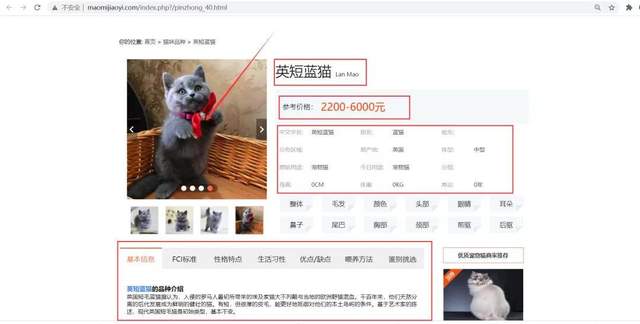
檢查網頁,可以發現網頁結構簡單,容易解析和提取數據。爬蟲代碼如下:
import requests
import re
import csv
from lxml import etree
from tqdm import tqdm
from fake_useragent import UserAgent
# 隨機產生請求頭
ua = UserAgent(verify_ssl=False, path='fake_useragent.json')
def random_ua(): # 用于隨機切換請求頭
headers = {
"Accept-Encoding": "gzip",
"Accept-Language": "zh-CN",
"Connection": "keep-alive",
"Host": "www.maomijiaoyi.com",
"User-Agent": ua.random
}
return headers
def create_csv(): # 創建保存數據的csv
with open('./data/cat_kind.csv', 'w', newline='', encoding='utf-8') as f:
wr = csv.writer(f)
wr.writerow(['品種', '參考價格', '中文學名', '別名', '祖先', '分布區域',
'原產地', '體型', '原始用途', '今日用途', '分組', '身高',
'體重', '壽命', '整體', '毛發', '顏色', '頭部', '眼睛',
'耳朵', '鼻子', '尾巴', '胸部', '頸部', '前驅', '后驅',
'基本信息', 'FCI標準', '性格特點', '生活習性', '優點/缺點',
'喂養方法', '鑒別挑選'])
def scrape_page(url1): # 獲取HTML網頁源代碼 返回文本
response = requests.get(url1, headers=random_ua())
# print(response.status_code)
response.encoding = 'utf-8'
return response.text
def get_cat_urls(html1): # 獲取每個品種貓咪詳情頁url
dom = etree.HTML(html1)
lis = dom.xpath('//div[@class="pinzhong_left"]/a')
cat_urls = []
for li in lis:
cat_url = li.xpath('./@href')[0]
cat_url = 'http://www.maomijiaoyi.com' + cat_url
cat_urls.append(cat_url)
return cat_urls
def get_info(html2): # 爬取每個品種貓咪詳情頁里的有關信息
# 品種
kind = re.findall('div class="line1">.*?<div class="name">(.*?)<span>', html2, re.S)[0]
kind = kind.replace('\r','').replace('\n','').replace('\t','')
# 參考價格
price = re.findall('<div>參考價格:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
price = price.replace('\r', '').replace('\n', '').replace('\t', '')
# 中文學名
chinese_name = re.findall('<div>中文學名:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
chinese_name = chinese_name.replace('\r', '').replace('\n', '').replace('\t', '')
# 別名
other_name = re.findall('<div>別名:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
other_name = other_name.replace('\r', '').replace('\n', '').replace('\t', '')
# 祖先
ancestor = re.findall('<div>祖先:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
ancestor = ancestor.replace('\r', '').replace('\n', '').replace('\t', '')
# 分布區域
area = re.findall('<div>分布區域:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
area = area.replace('\r', '').replace('\n', '').replace('\t', '')
# 原產地
source_area = re.findall('<div>原產地:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
source_area = source_area.replace('\r', '').replace('\n', '').replace('\t', '')
# 體型
body_size = re.findall('<div>體型:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
body_size = body_size.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 原始用途
source_use = re.findall('<div>原始用途:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
source_use = source_use.replace('\r', '').replace('\n', '').replace('\t', '')
# 今日用途
today_use = re.findall('<div>今日用途:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
today_use = today_use.replace('\r', '').replace('\n', '').replace('\t', '')
# 分組
group = re.findall('<div>分組:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
group = group.replace('\r', '').replace('\n', '').replace('\t', '')
# 身高
height = re.findall('<div>身高:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
height = height.replace('\r', '').replace('\n', '').replace('\t', '')
# 體重
weight = re.findall('<div>體重:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
weight = weight.replace('\r', '').replace('\n', '').replace('\t', '')
# 壽命
lifetime = re.findall('<div>壽命:</div>.*?<div>(.*?)</div>', html2, re.S)[0]
lifetime = lifetime.replace('\r', '').replace('\n', '').replace('\t', '')
# 整體
entirety = re.findall('<div>整體</div>.*?<!-- 頁面小折角 -->.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
entirety = entirety.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 毛發
hair = re.findall('<div>毛發</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
hair = hair.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 顏色
color = re.findall('<div>顏色</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
color = color.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 頭部
head = re.findall('<div>頭部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
head = head.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 眼睛
eye = re.findall('<div>眼睛</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
eye = eye.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 耳朵
ear = re.findall('<div>耳朵</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
ear = ear.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 鼻子
nose = re.findall('<div>鼻子</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
nose = nose.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 尾巴
tail = re.findall('<div>尾巴</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
tail = tail.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 胸部
chest = re.findall('<div>胸部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
chest = chest.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 頸部
neck = re.findall('<div>頸部</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
neck = neck.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 前驅
font_foot = re.findall('<div>前驅</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
font_foot = font_foot.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 后驅
rear_foot = re.findall('<div>前驅</div>.*?<div></div>.*?<div>(.*?)</div>', html2, re.S)[0]
rear_foot = rear_foot.replace('\r', '').replace('\n', '').replace('\t', '').strip()
# 保存前面貓貓的各種有關信息
cat = [kind, price, chinese_name, other_name, ancestor, area, source_area,
body_size, source_use, today_use, group, height, weight, lifetime,
entirety, hair, color, head, eye, ear, nose, tail, chest, neck, font_foot, rear_foot]
# 提取標簽欄信息(基本信息-FCI標準-性格特點-生活習性-優缺點-喂養方法-鑒別挑選)
html2 = etree.HTML(html2)
labs = html2.xpath('//div[@class="property_list"]/div')
for lab in labs:
text1 = lab.xpath('string(.)')
text1 = text1.replace('\n','').replace('\t','').replace('\r','').replace(' ','')
cat.append(text1)
return cat
def write_to_csv(data): # 保存數據 追加寫入
with open('./data/cat_kind.csv', 'a+', newline='', encoding='utf-8') as fn:
wr = csv.writer(fn)
wr.writerow(data)
if __name__ == '__main__':
# 創建保存數據的csv
create_csv()
# 貓咪品種頁面url
base_url = 'http://www.maomijiaoyi.com/index.php?/pinzhongdaquan_5.html'
# 獲取品種頁面中的所有url
html = scrape_page(base_url)
urls = get_cat_urls(html)
# 進度條可視化運行情況 就不打印東西來看了
pbar = tqdm(urls)
# 開始爬取
for url in pbar:
text = scrape_page(url)
info = get_info(text)
write_to_csv(info)運行效果如下:
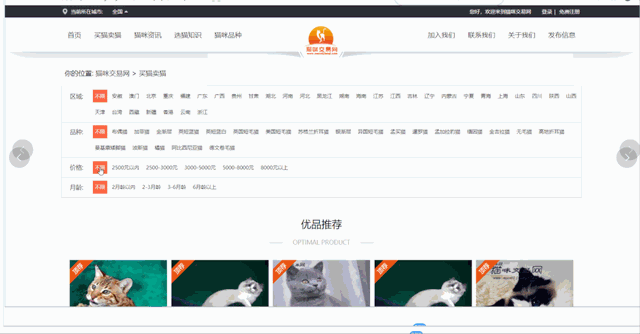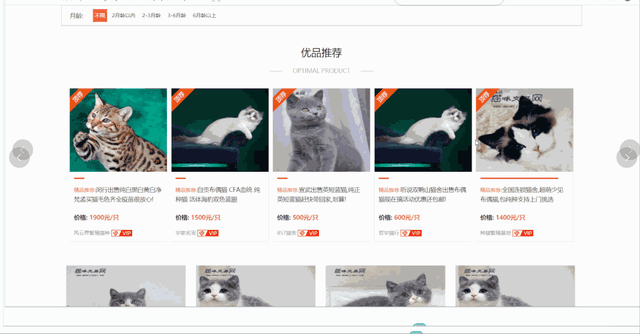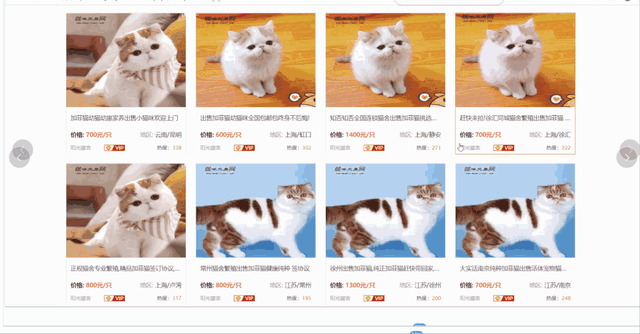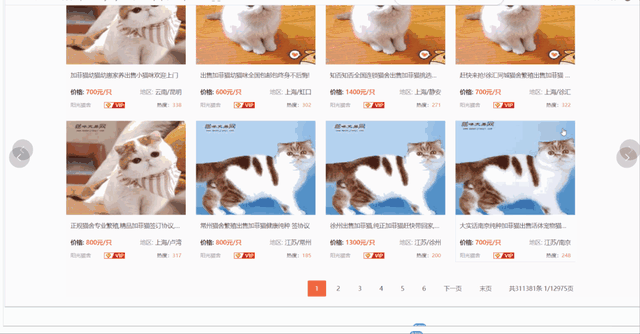
爬取更詳細的數據需要進入詳情頁,包含商家信息、貓咪品種、貓齡、價格、標題、在售只數、預防等信息。

看各種貓咪的體型分布

橘貓是世界各地都有的,不愧是我大橘貓。俗話說 "十個橘貓九個胖還有一個壓塌炕"。橘貓比起其他花色的貓咪更喜歡吃東西,它們的食欲很好,能更好地生存,可能這也是橘貓在世界范圍都有的原因吧。可它卻是小型貓,橘貓小時候顏值一般挺高,看起來小小的一只,又嫩又可愛的,但等橘貓長大以后,才真正地意識到什么是 "橘足輕重"。

橘貓的交易數量最多呀,之前也提到橘貓世界各地都有,從這里也可以看到橘貓數量最多。其次是咖啡貓,布偶貓,英短藍白貓等。
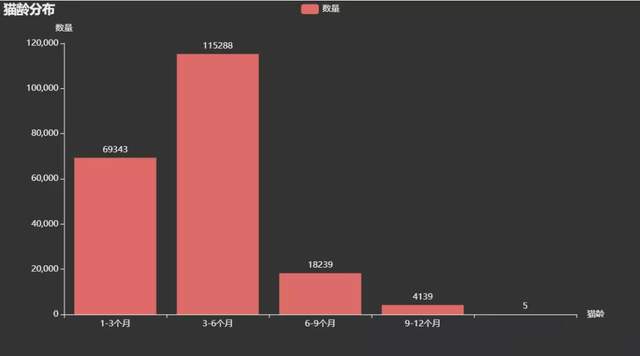
售賣的貓咪貓齡主要在1-6個月,都是剛出生還未滿半歲的小貓咪呀。這時候的小貓咪應該很可愛吧,等待有緣的主人把它帶回家。
最后來看一下網站里價格最貴的貓咪和瀏覽次數最多的貓咪
import pandas as pd
df = pd.read_excel('處理后數據.xlsx')
print(df.info())
df1 = df.sort_values(by='瀏覽次數', ascending=False)
print(df1.iloc[:3, ::].values)
print('----------------------------------------------------------')
df2 = df.sort_values(by='價格', ascending=False)
print(df2.iloc[:3, ::].values)# 瀏覽次數最多的 http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_441879.html http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_462431.html http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_455366.html
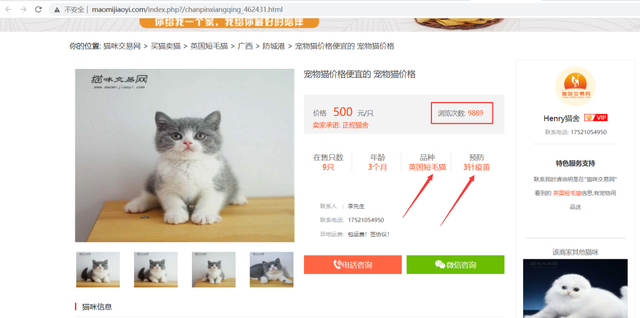
反觀瀏覽次數排第二、第三的,價格便宜不少,預防都打了3針疫苗,在售只數還比較充裕,還比第一可愛好多(個人感覺)。
# 價格最貴的如下 http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_265770.html http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_281910.html http://www.maomijiaoyi.com/index.php?/chanpinxiangqing_230417.html
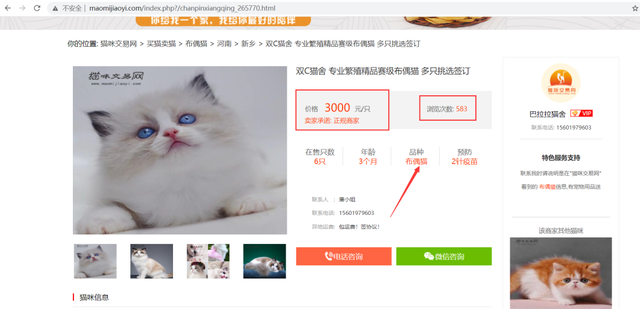

價格最貴的發現均為 3000 元的布偶貓。查閱資料發現,布偶貓,大型貓咪,不僅購買的時候價格高昂,飼養成本也比較高,因為食量和運動量都比較大,而且美容等相關費用也會高一些。
上述就是小編為大家分享的Python如何爬取貓咪網站交易數據了,如果剛好有類似的疑惑,不妨參照上述分析進行理解。如果想知道更多相關知識,歡迎關注億速云行業資訊頻道。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





