溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章給大家分享的是有關Hive如何實現查詢的內容。小編覺得挺實用的,因此分享給大家做個參考,一起跟隨小編過來看看吧。
官方演示案例:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+Select
SELECT [ALL | DISTINCT] 字段1,字段2,字段3... --all 是默認的 表是全部查出來,distinct 表示去重查詢(可以精確某個列) FROM table_reference --從哪個表查 [WHERE where_condition] --過濾條件 [GROUP BY col_list] --以某某字段分組(可以有多個字段) [HAVING col_list] --給分組過后一些數據進行過濾 [ORDER BY col_list] --全局排序 [DISTRIBUTE BY col_list] [SORT BY col_list] --分區、及排序 [CLUSTER BY col_list] --分區排序 [LIMIT number] --限制輸出的行數(翻頁)
SQL執行順序:from < join < where < group by < count(*) < having < select < order by < limit
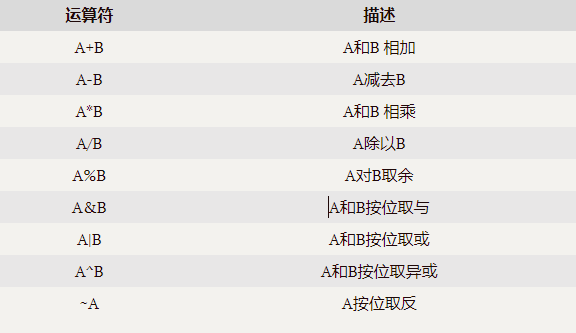

GROUP BY語句通常會和聚合函數一起使用,按照一個或者多個列隊結果進行分組,然后對每個組執行聚合操作。 select t.deptno, t.job, max(t.sal) max_sal from emp t group by t.deptno, t.job; 注意:在使用了group by后,select后面接的字段只能是group by后面有的。
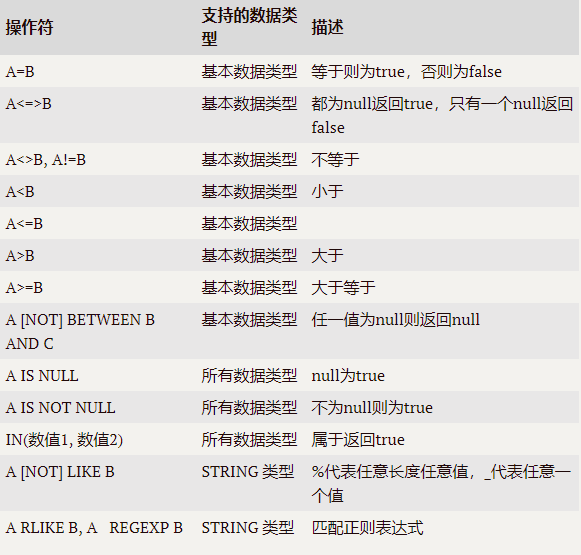
--having與where不同點 --(1)where后面不能寫分組聚合函數,而having后面可以使用分組聚合函數。 --(2)having只用于group by分組統計語句。 select deptno, avg(sal) avg_sal from emp group by deptno having avg_sal > 2000;
--只有進行連接的兩個表中都存在與連接條件相匹配的數據才會被保留下來 select e.empno, e.ename, d.deptno from emp e (inner)join dept d on e.deptno = d.deptno;
--JOIN操作符左邊表中符合WHERE子句的所有記錄將會被返回 select e.*, d.dname, d.loc from emp e left join dept d on e.deptno=d.deptno;
--JOIN操作符右邊表中符合WHERE子句的所有記錄將會被返回 select e.*, d.* from emp e right join dept d on e.deptno=d.deptno
--將會返回所有表中符合WHERE語句條件的所有記錄 --方式一: select e.*, d.* from dept d full join emp e on d.deptno=e.deptno --方式二: select e.empno, e.ename, d.dname from dept d left join emp e on d.deptno=e.deptno union all select e.empno, e.ename, d.dname from dept d right join emp e on d.deptno=e.deptno --union 豎向拼接兩張表 可以將相同數據去重 --union all 豎向拼接兩張表 直接拼接不去重
--全局排序,只有一個Reducer --asc 升序 (默認) --desc 倒序 select * from emp order by sal desc
--distribute by (分區) and sort by(區內排序) 按照部門編號分區,再按照員工編號降序排序。 //設置reduce數量 set mapreduce.job.reduces=3; --默認-1 insert overwrite local directory '/opt/module/hive/datas/distribute-result' select * from emp distribute by deptno sort by empno desc; 注意: --distribute by的分區規則是根據分區字段的hash碼與reduce的個數進行模除后,余數相同的分-到一個區。 --Hive要求DISTRIBUTE BY語句要寫在SORT BY語句之前。
--當distribute by和sort by字段相同時,可以使用cluster by方式 select * from emp cluster by deptno; select * from emp distribute by deptno sort by deptno; 注意: --cluster by除了具有distribute by的功能外還兼具sort by的功能。但是排序只能是升序排序,不能指定排序規則 為ASC或者DESC
--group by a,b,c grouping sets((a,b),c) --相當于(group by a,b) union (group by c) select region,school,class,count(1) from school group by region,school,class grouping sets(region,school,class); +---------+---------+----------+------+ | region | school | class | _c3 | +---------+---------+----------+------+ | NULL | NULL | 三年一班 | 5 | | NULL | NULL | 坦克一班 | 6 | | NULL | NULL | 大數據一班 | 4 | | NULL | NULL | 小學生一班 | 4 | | NULL | NULL | 法師一班 | 4 | | NULL | 寶安中學 | NULL | 4 | | NULL | 王者峽谷 | NULL | 10 | | NULL | 黃田小學 | NULL | 4 | | NULL | 龍華小學 | NULL | 5 | | 寶安區 | NULL | NULL | 8 | | 王者區 | NULL | NULL | 10 | | 龍華區 | NULL | NULL | 5 | +---------+---------+----------+------+
--group by a,b,c with cube 相當于對a,b,c各種組合group by之后union --相當于union -- group by null,a,b,c,ab,ac,bc,abc select region,class, school,count(1) from school group by region,class, school with cube;
--group by a,b,c with rollup --相當于union -- group by null,a,ab,abc select region,class, school,count(1) from school group by region,class, school with rollup
感謝各位的閱讀!關于“Hive如何實現查詢”這篇文章就分享到這里了,希望以上內容可以對大家有一定的幫助,讓大家可以學到更多知識,如果覺得文章不錯,可以把它分享出去讓更多的人看到吧!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





