溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“Flink提交任務的方法是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“Flink提交任務的方法是什么”吧!
任務提交過程中有三個重要組件:Dispatcher、JobMaster、JobManagerRunnerImpl。通過下面調用路徑先找到MiniDispatcher:
YarnJobClusterEntrypoint的main() -> ClusterEntrypoint的runCluster() -> DefaultDispatcherResourceManagerComponentFactory的create() -> DefaultDispatcherRunnerFactory的createDispatcherRunner() -> DefaultDispatcherRunner的grantLeadership() -> JobDispatcherLeaderProcess的onStart() -> DefaultDispatcherGatewayServiceFactory的create() -> JobDispatcherFactory的createDispatcher() -> MiniDispatcher的start()
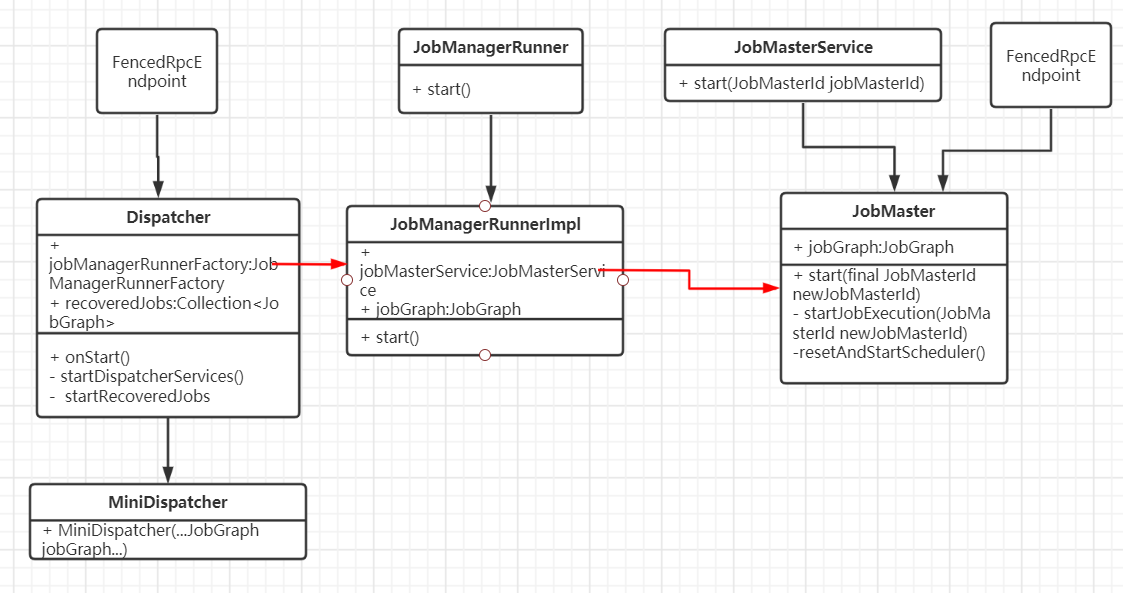
(1)Dispatcher
負責接收任務提交請求,并分給JobManager執行;
Dispatcher啟動時,會運行startRecoveredJobs()來啟動需要恢復的任務。當Flink on Yarn模式時,MiniDispatcher將當前任務傳入到需要恢復的任務中,這樣就實現了任務的提交啟動
(2)JobManagerRunner
負責運行JobMaster
(3)JobMaster
負責運行任務,對應舊版的JobManager;
一個任務對應一個JobMaster;
在JobMaster中通過Scheduler、Execution組件來執行一個任務。將任務DAG中每個節點算子分配給TaskManager中的TaskExecutor運行。
Execution的start()方法中通過rpc遠程調用TaskExecutor的submitTask()方法:
public void deploy() throws JobException {
......
try {
......
final TaskManagerGateway taskManagerGateway = slot.getTaskManagerGateway();
final ComponentMainThreadExecutor jobMasterMainThreadExecutor =
vertex.getExecutionGraph().getJobMasterMainThreadExecutor();
CompletableFuture.supplyAsync(() -> taskManagerGateway.submitTask(deployment, rpcTimeout), executor)
.thenCompose(Function.identity())
.whenCompleteAsync(
.....,
jobMasterMainThreadExecutor);
}
catch (Throwable t) {
......
}
}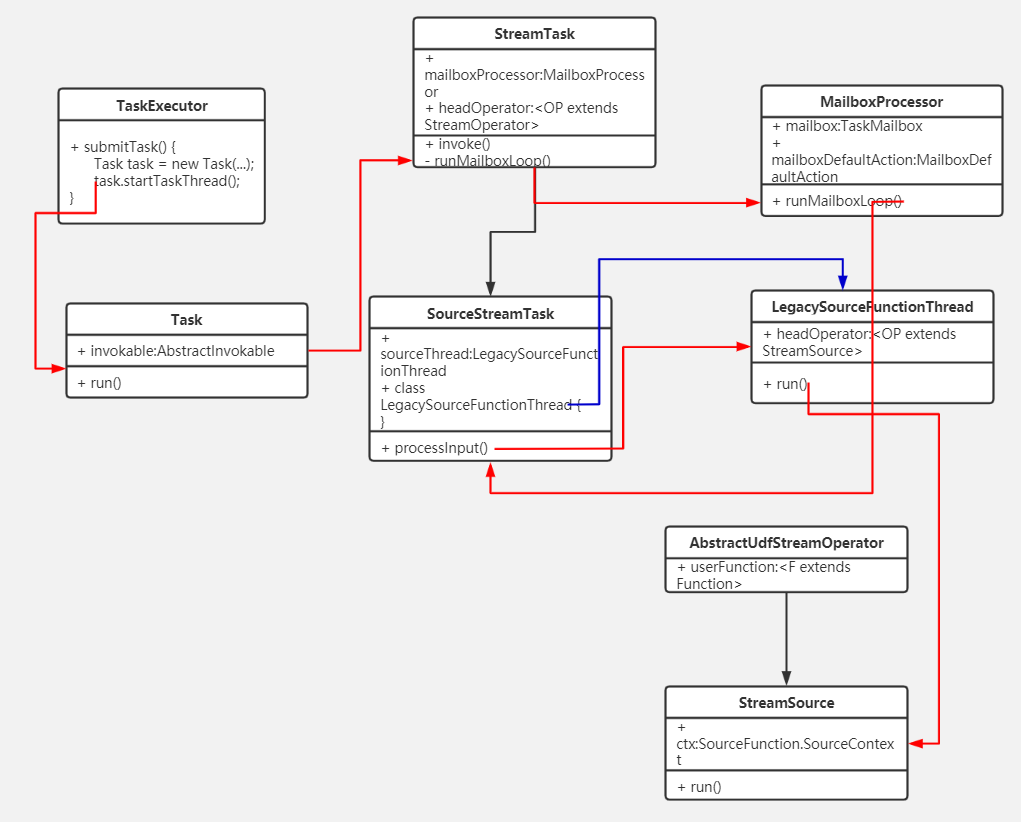
TaskExecutor的submitTask()方法中通過創建org.apache.flink.runtime.taskmanager.Task來運行算子任務。Task的doRun()方法中通過算子節點對應的執行類AbstractInvokable來運行算子的處理邏輯,每個算子對應的執行類AbstractInvokable在客戶端提交任務時確定,StreamExecutionEnvironment的addOperator():
public <IN, OUT> void addOperator(
Integer vertexID,
@Nullable String slotSharingGroup,
@Nullable String coLocationGroup,
StreamOperatorFactory<OUT> operatorFactory,
TypeInformation<IN> inTypeInfo,
TypeInformation<OUT> outTypeInfo,
String operatorName) {
Class<? extends AbstractInvokable> invokableClass =
operatorFactory.isStreamSource() ? SourceStreamTask.class : OneInputStreamTask.class;
addOperator(vertexID, slotSharingGroup, coLocationGroup, operatorFactory, inTypeInfo,
outTypeInfo, operatorName, invokableClass);
}當是流式任務時,調用StreamTask的invoke()方法。當是source節點時,通過調用鏈 StreamTask.invoke() -> StreamTask.runMailboxLoop() -> MailboxProcessor.runMailboxLoop() -> SourceStreamTask.processInput() :
protected void processInput(MailboxDefaultAction.Controller controller) throws Exception {
controller.suspendDefaultAction();
// Against the usual contract of this method, this implementation is not step-wise but blocking instead for
// compatibility reasons with the current source interface (source functions run as a loop, not in steps).
sourceThread.setTaskDescription(getName());
sourceThread.start();
sourceThread.getCompletionFuture().whenComplete((Void ignore, Throwable sourceThreadThrowable) -> {
if (isCanceled() && ExceptionUtils.findThrowable(sourceThreadThrowable, InterruptedException.class).isPresent()) {
mailboxProcessor.reportThrowable(new CancelTaskException(sourceThreadThrowable));
} else if (!isFinished && sourceThreadThrowable != null) {
mailboxProcessor.reportThrowable(sourceThreadThrowable);
} else {
mailboxProcessor.allActionsCompleted();
}
});
}創建線程LegacySourceFunctionThread實例,來開啟單獨生產數據的線程。LegacySourceFunctionThread的run()方法中調用StreamSource的run()方法:
public void run(final Object lockingObject,
final StreamStatusMaintainer streamStatusMaintainer,
final Output<StreamRecord<OUT>> collector,
final OperatorChain<?, ?> operatorChain) throws Exception {
final TimeCharacteristic timeCharacteristic = getOperatorConfig().getTimeCharacteristic();
final Configuration configuration = this.getContainingTask().getEnvironment().getTaskManagerInfo().getConfiguration();
final long latencyTrackingInterval = getExecutionConfig().isLatencyTrackingConfigured()
? getExecutionConfig().getLatencyTrackingInterval()
: configuration.getLong(MetricOptions.LATENCY_INTERVAL);
LatencyMarksEmitter<OUT> latencyEmitter = null;
if (latencyTrackingInterval > 0) {
latencyEmitter = new LatencyMarksEmitter<>(
getProcessingTimeService(),
collector,
latencyTrackingInterval,
this.getOperatorID(),
getRuntimeContext().getIndexOfThisSubtask());
}
final long watermarkInterval = getRuntimeContext().getExecutionConfig().getAutoWatermarkInterval();
this.ctx = StreamSourceContexts.getSourceContext(
timeCharacteristic,
getProcessingTimeService(),
lockingObject,
streamStatusMaintainer,
collector,
watermarkInterval,
-1);
try {
userFunction.run(ctx);
// if we get here, then the user function either exited after being done (finite source)
// or the function was canceled or stopped. For the finite source case, we should emit
// a final watermark that indicates that we reached the end of event-time, and end inputs
// of the operator chain
if (!isCanceledOrStopped()) {
// in theory, the subclasses of StreamSource may implement the BoundedOneInput interface,
// so we still need the following call to end the input
synchronized (lockingObject) {
operatorChain.endHeadOperatorInput(1);
}
}
} finally {
if (latencyEmitter != null) {
latencyEmitter.close();
}
}
}StreamSource的run()方法中調用 userFunction.run(ctx); 當數據源是kafka時,userFunction為FlinkKafkaConsumerBase
最后執行run()的headOperator和算子程序userFunction是在添加算子時確定的,比如添加kafka數據源時
environment.addSource(new FlinkKafkaConsumer<String>(......));
最后調用的addSource()方法:
public <OUT> DataStreamSource<OUT> addSource(SourceFunction<OUT> function, String sourceName, TypeInformation<OUT> typeInfo) {
TypeInformation<OUT> resolvedTypeInfo = getTypeInfo(function, sourceName, SourceFunction.class, typeInfo);
boolean isParallel = function instanceof ParallelSourceFunction;
clean(function);
final StreamSource<OUT, ?> sourceOperator = new StreamSource<>(function);
return new DataStreamSource<>(this, resolvedTypeInfo, sourceOperator, isParallel, sourceName);
}headOperator為StreamSource,StreamSource中的userFunction為FlinkKafkaConsumer
到此,相信大家對“Flink提交任務的方法是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





