溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要講解了“Redis字典知識點有哪些”,文中的講解內容簡單清晰,易于學習與理解,下面請大家跟著小編的思路慢慢深入,一起來研究和學習“Redis字典知識點有哪些”吧!
說起字典,也許大家比較陌生,但是我們都知道 Redis 本身提供 KV 查詢的方式,這個 KV 就是其實通過底層就是通過字典保存。
另外,Redis 支持多種數據類型,其中一種類型為 Hash 鍵,也可以用來存儲 KV 數據。
阿粉剛開始了解的這個數據結構的時候,本來以為這個就是使用字典實現。其實并不是這樣的,初始創建 Hash 鍵,默認使用另外一種數據結構-「ZIPLIST」(壓縮列表),以此節省內存空間。
不過一旦以下任何條件被滿足,Hash 鍵的數據結構將會變為字典,加快查詢速度。
server.hash_max_ziplist_value (默認值為 64 )。server.hash_max_ziplist_entries (默認值為 512 )。Redis 字典新建時默認將會創建一個哈希表數組,保存兩個哈希表。
其中 ht[0] 哈希表在第一次往字典中添加鍵值時分配內存空間,而另一個 ht[1] 將會在下文中擴容/縮容才會進行空間分配。
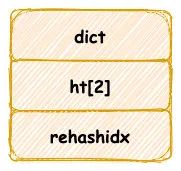
字典中哈希表其實就等同于Java HashMap,我們知道 Java 采用數組加鏈表/紅黑樹的實現方式,其實哈希表也是使用類似的數據結構。
哈希表結構如下所示:
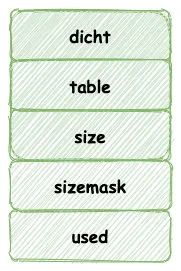
其中 table 屬性是個數組, 其中數組元素保存一種 dictEntry 的結構,這個結構完全類似與 HashMap 中的 Entry 類型,這個結構存儲一個 KV 鍵值對。
同時,為了解決 hash 碰撞的問題,dictEntry 存在一個 next 指針,指向下一個dictEntry ,這樣就形成 dictEntry 的鏈表。
現在,我們回頭對比 Java 中 HashMap,可以發現兩者數據結構基本一致。
只不過 HashMap 為了解決鏈表過長問題導致查詢變慢,JDK1.8 時在鏈表元素過多時采用紅黑樹的數據結構。
下面我們開始添加新元素,了解這其中的原理。
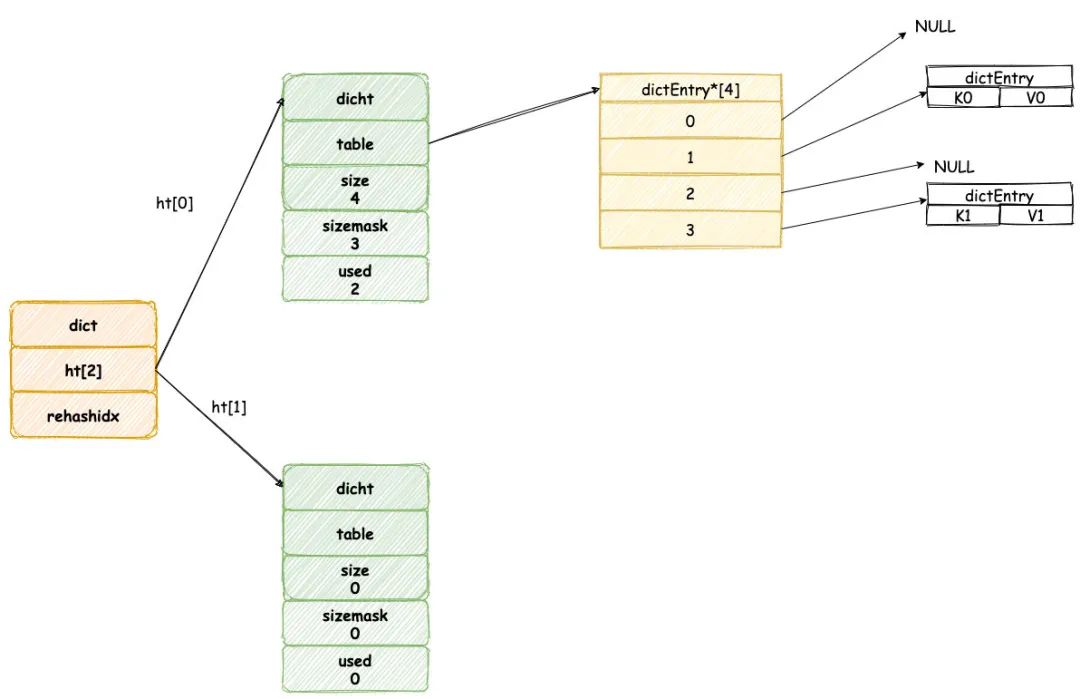
當我們往一個新字典中添加元素,默認將會為字典中 ht[0] 哈希表分配空間,默認情況下哈希表 table 數組大小為 4(「DICT_HT_INITIAL_SIZE」)。
新添加元素的鍵值將會經過哈希算法,確定哈希表數組的位置,然后添加到相應的位置,如圖所示:

繼續增加元素,此時如果兩個不同鍵經過哈希算法產生相同的哈希值,這樣就發生了哈希碰撞。
假設現在我們哈希表中擁有是三個元素,:
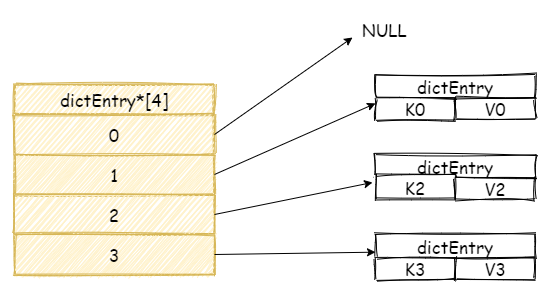
我們再增加一個新元素,如果此時剛好在數組 3 號位置上發生碰撞,此時 Redis 將會采用鏈表的方式解決哈希碰撞。
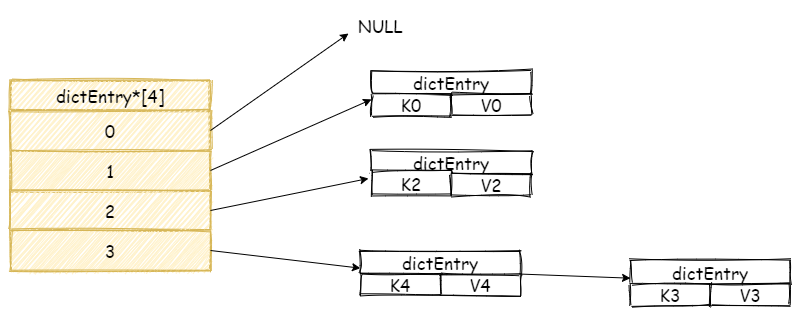
「注意,新元素將會放在鏈表頭結點,這么做目的是因為新增加的元素,很大概率上會被再次訪問,放在頭結點增加訪問速度。」
這里我們在對比一下元素添加過程,可以發現 Redis 流程其實與 JDK 1.7 版本的 HashMap 類似。
當我們元素增加越來越多時,哈希碰撞情況將會越來越頻繁,這就會導致鏈表長度過長,極端情況下 O(1) 查詢效率退化成 O(N) 的查詢效率。
為此,字典必須進行擴容,這樣就會使觸發字典 rehash 操作。
當 Redis 進行 Rehash 擴容操作,首先將會為字典沒有用到 ht[1] 哈希表分配更大空間。
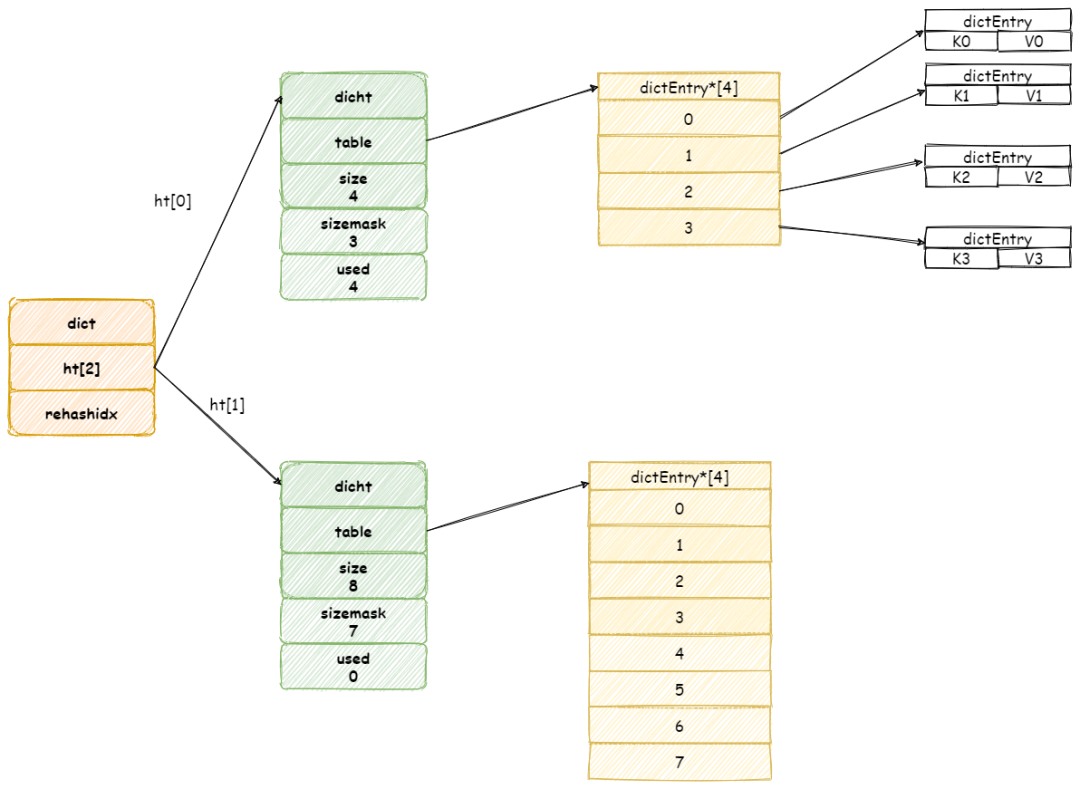
?畫外音:
?ht[1]哈希表大小為第一個大于等于ht[0].used*2的 2^2(2的n 次方冪)
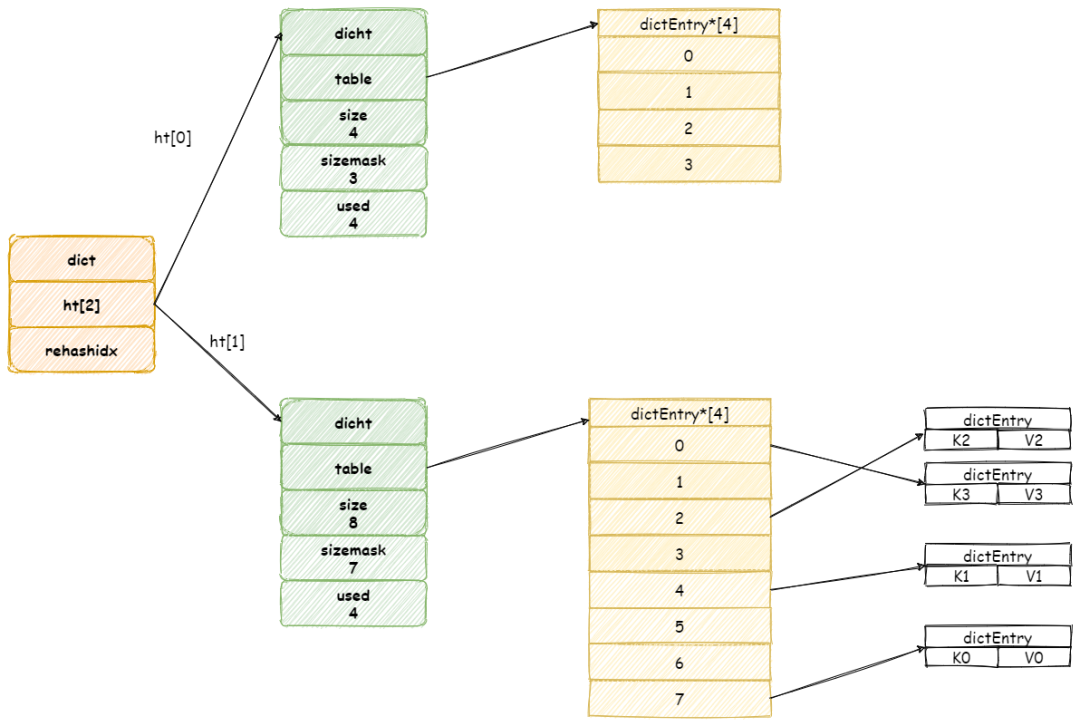
然后再將 ht[0] 中所有鍵值對都遷移到 ht[1] 中。
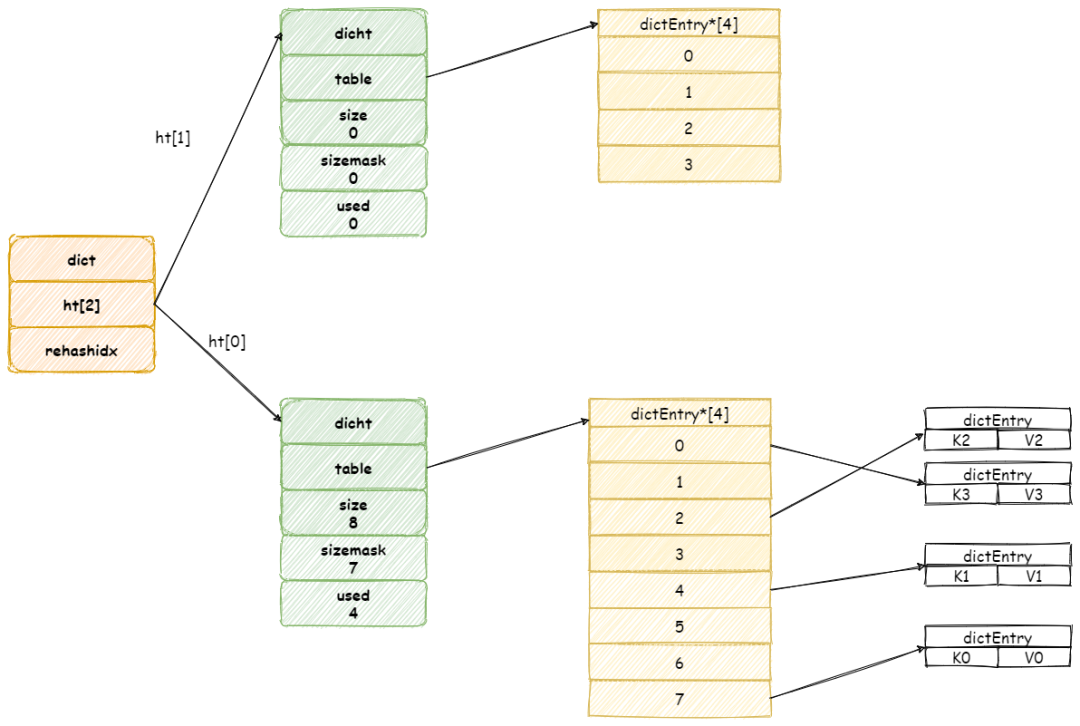
當節點全部遷移完畢,將會釋放 ht[0]占用空間,并將 ht[1] 設置為 ht[0]。
擴容 操作需要將 ht[0]所有鍵值對都 Rehash 到 ht[1] 中,如果鍵值過多,假設存在十億個鍵值對,這樣一次性的遷移,勢必導致服務器會在一段時間內停止服務。
另外如果每次 rehash 都會阻塞當前操作,這樣對于客戶端處理非常不友好。
為了避免 rehash對服務器的影響,Redis 采用漸進式的遷移方式,慢慢將數據遷移分散到多個操作步驟。
這個操作依賴字典中一個屬性 rehashidx,這是一個索引位置計數器,記錄下一個哈希表 table 數組上元素,默認情況為值為 「-1」。
假設此時擴容前字典如圖所示:
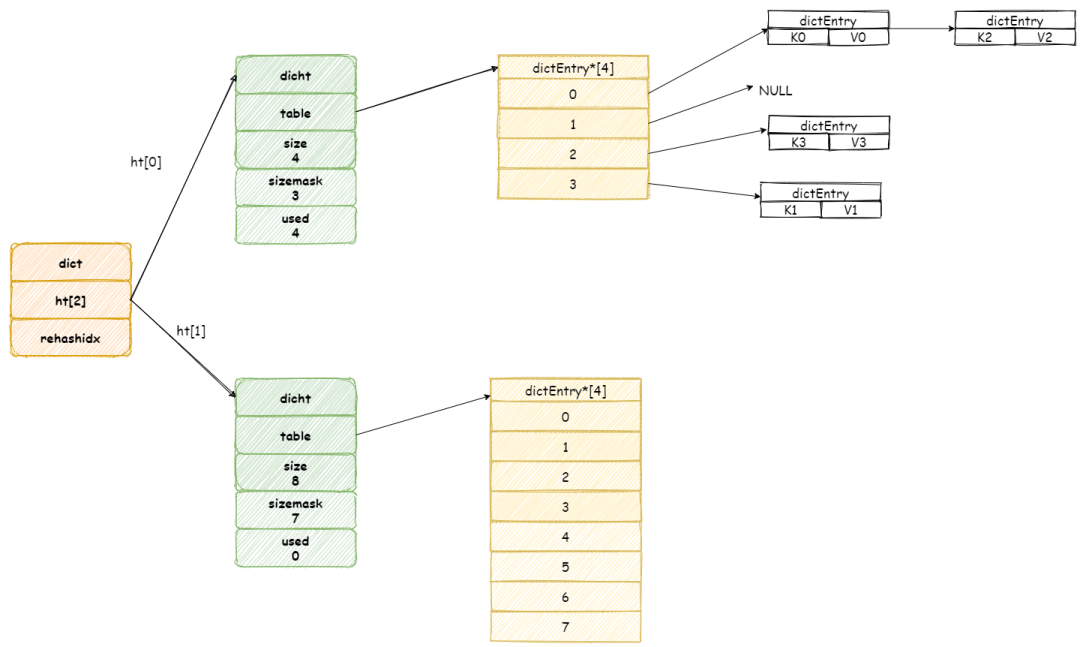
當開始 rehash 操作,rehashidx將會被設置為 「0」 。
這個期間每次收到增加,刪除,查找,更新命令,除了這些命令將會被執行以外,還會順帶將 ht[0]哈希表在 rehashidx 位置的元素 rehash 到 ht[1] 中。
假設此時收到一個 「K3」 鍵的查詢操作,Redis 首先執行查詢操作,接著 Redis 將會為 ht[0]哈希表上table 數組第 rehashidx索引上所有節點都遷移到 ht[1] 中。
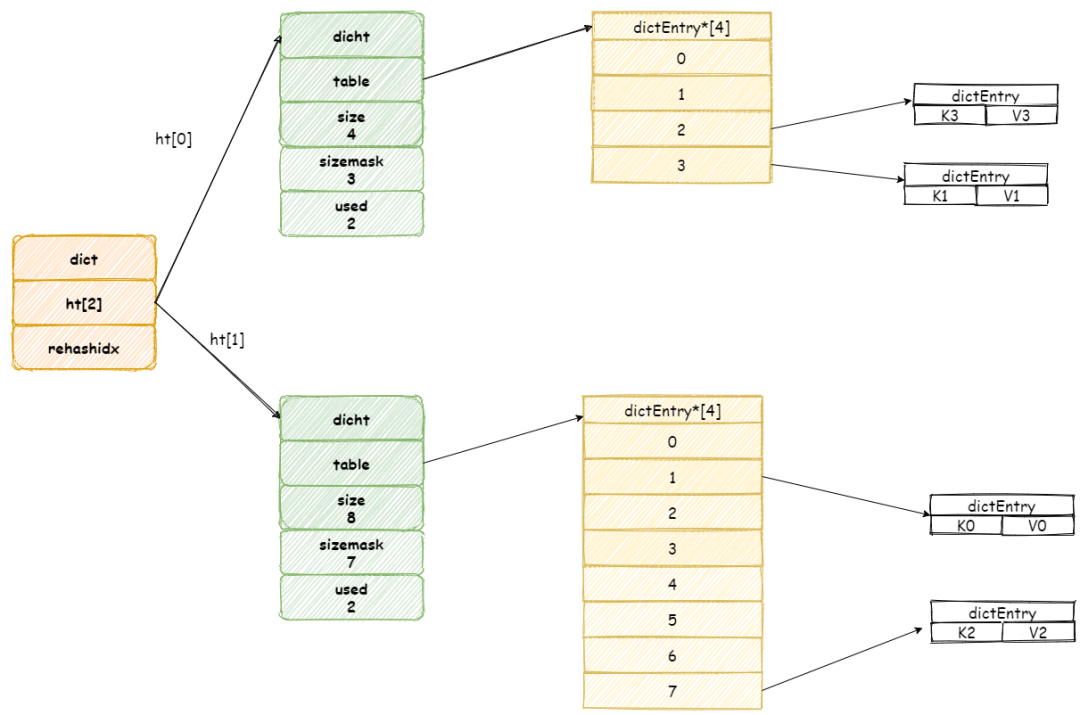
當操作完成之后,再將 rehashidx 屬性值加 1。
最后當所有鍵值對都 rehash 到 ht[1]中時,rehashidx將會被重新設置為 -1。
雖然漸進式的 rehash 操作減少了工作量,但是卻帶來鍵值操作的復雜度。
這是因為在漸進式 rehash 操作期間,Redis 無法明確知道鍵到底在 ht[0]中,還是在 ht[1] 中,所以這個時候 Redis 不得不查找兩個哈希表。
以查找為例,Redis 首先查詢 ht[0] ,如果沒找到將會繼續查找 ht[1],除了查詢以外,更新,刪除也會執行如上的操作。
添加操作其實就沒這么麻煩,因為ht[0]不會在使用,那就統一都添加到 ht[1] 中就好了。
最后我們再對比一下 Java HashMap 擴容操作,它是一個一次性操作,每次擴容需要將所有鍵值對都遷移到新的數組中,所以如果數據量很大,消耗時間就會久。
感謝各位的閱讀,以上就是“Redis字典知識點有哪些”的內容了,經過本文的學習后,相信大家對Redis字典知識點有哪些這一問題有了更深刻的體會,具體使用情況還需要大家實踐驗證。這里是億速云,小編將為大家推送更多相關知識點的文章,歡迎關注!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





