溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
今天就跟大家聊聊有關Presto在軟件的探索與實踐是怎樣的,可能很多人都不太了解,為了讓大家更加了解,小編給大家總結了以下內容,希望大家根據這篇文章可以有所收獲。
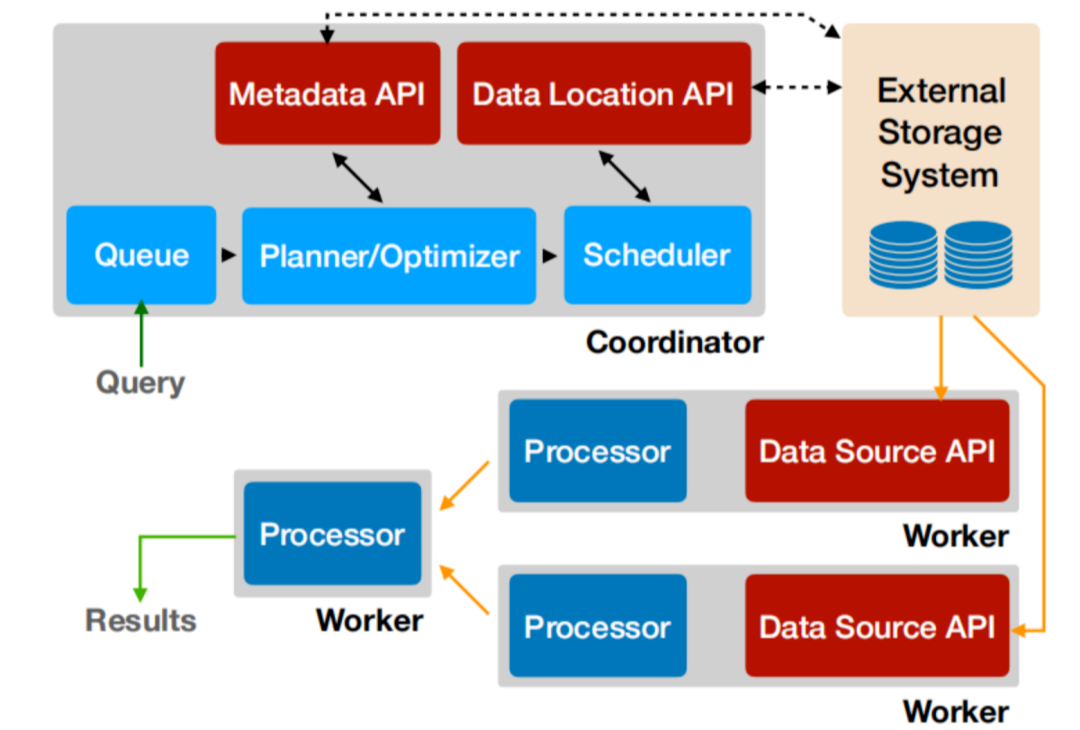

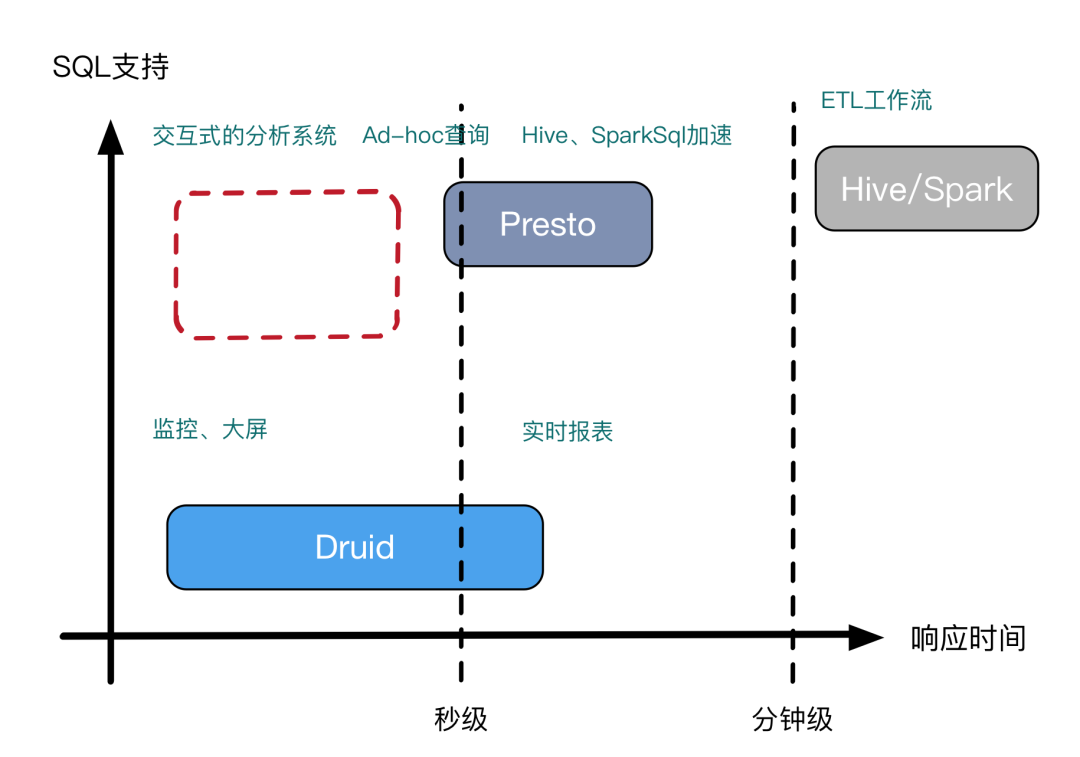

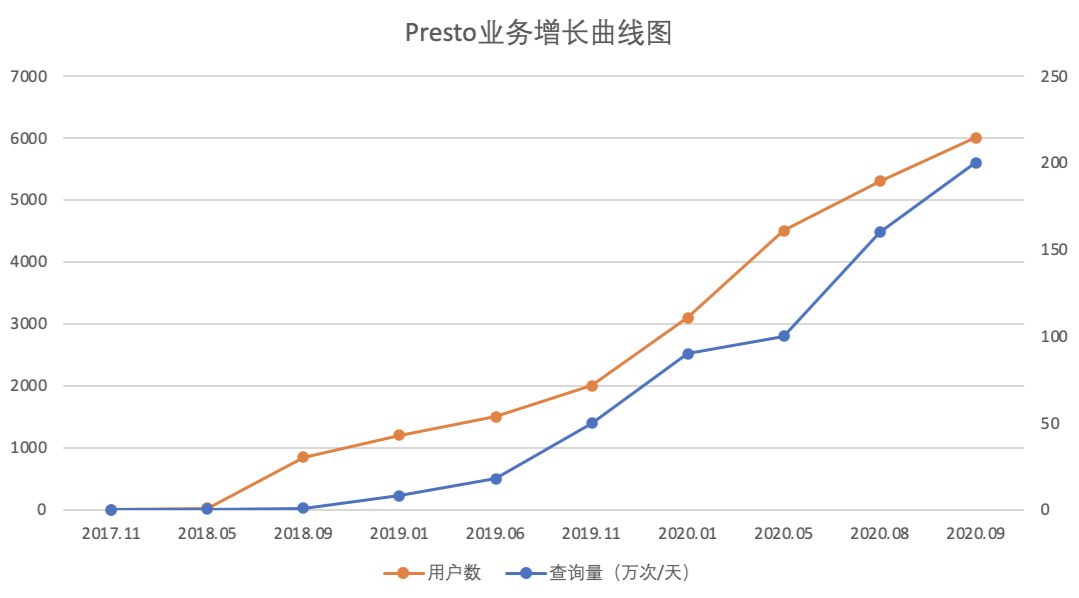
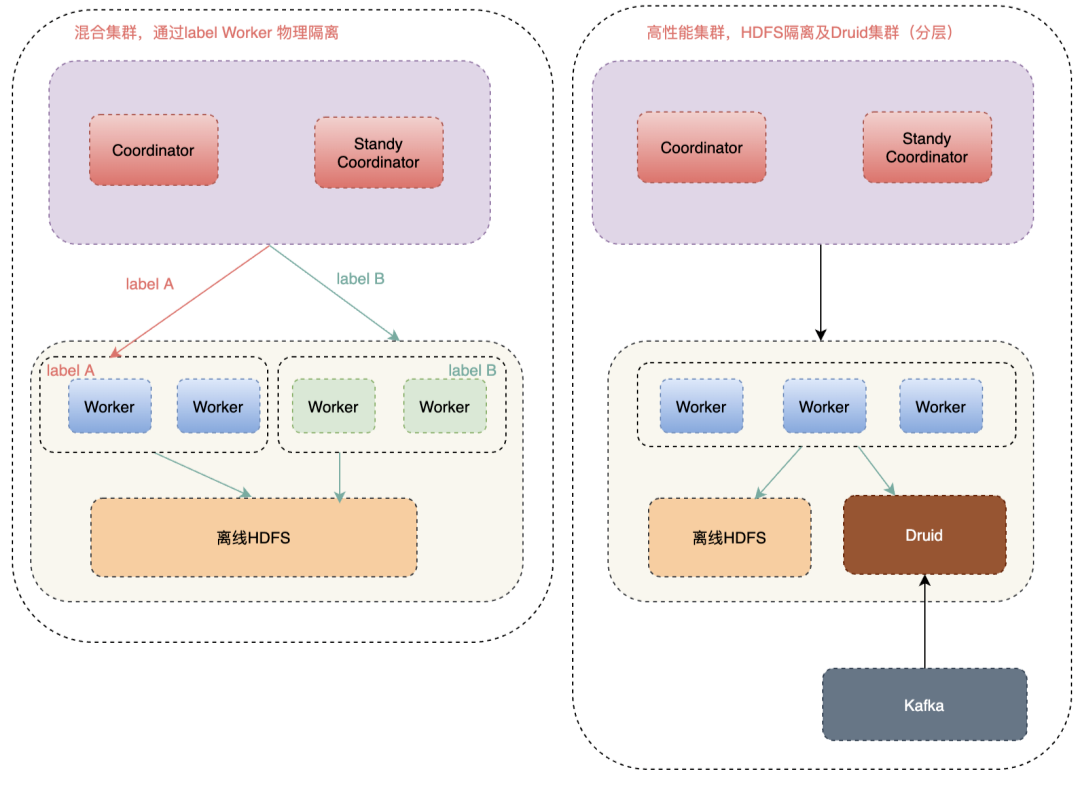
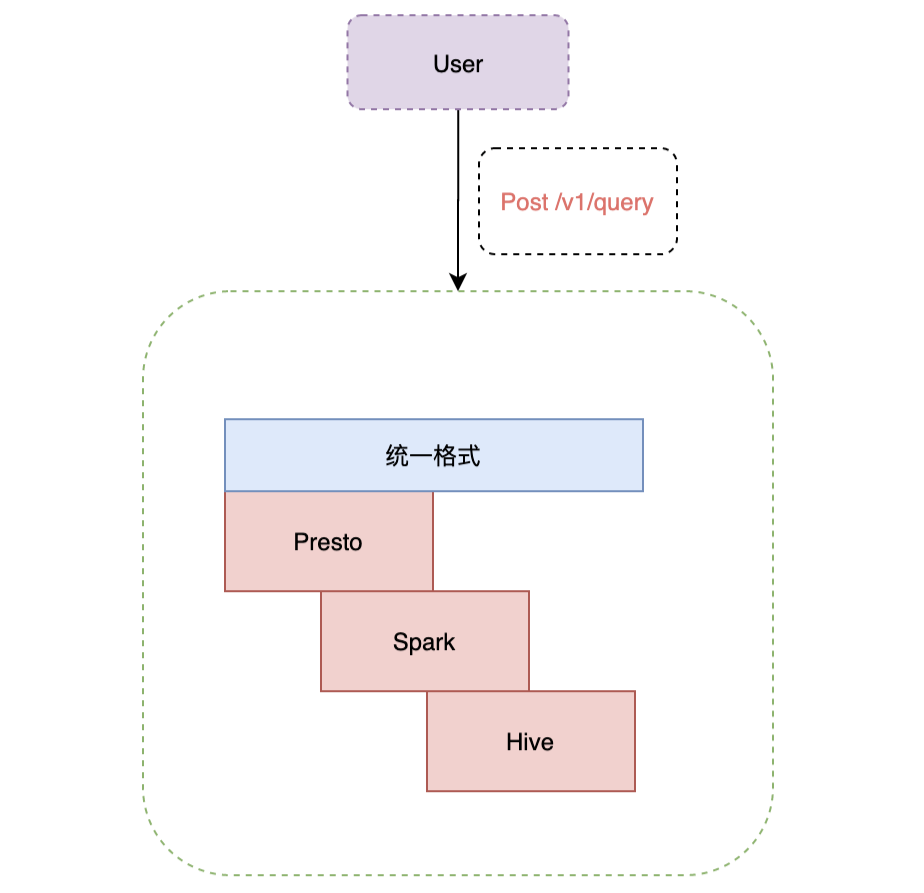
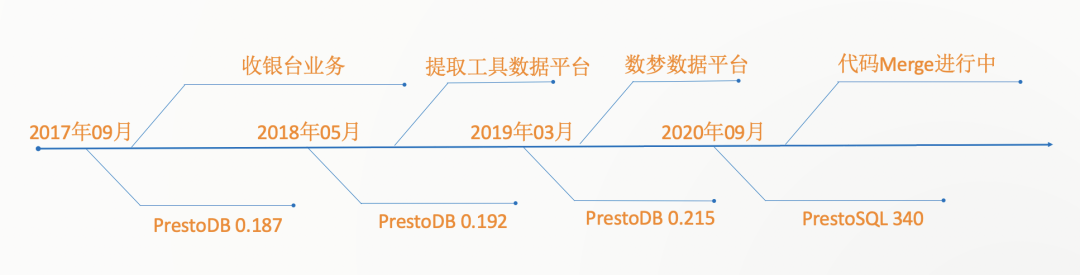
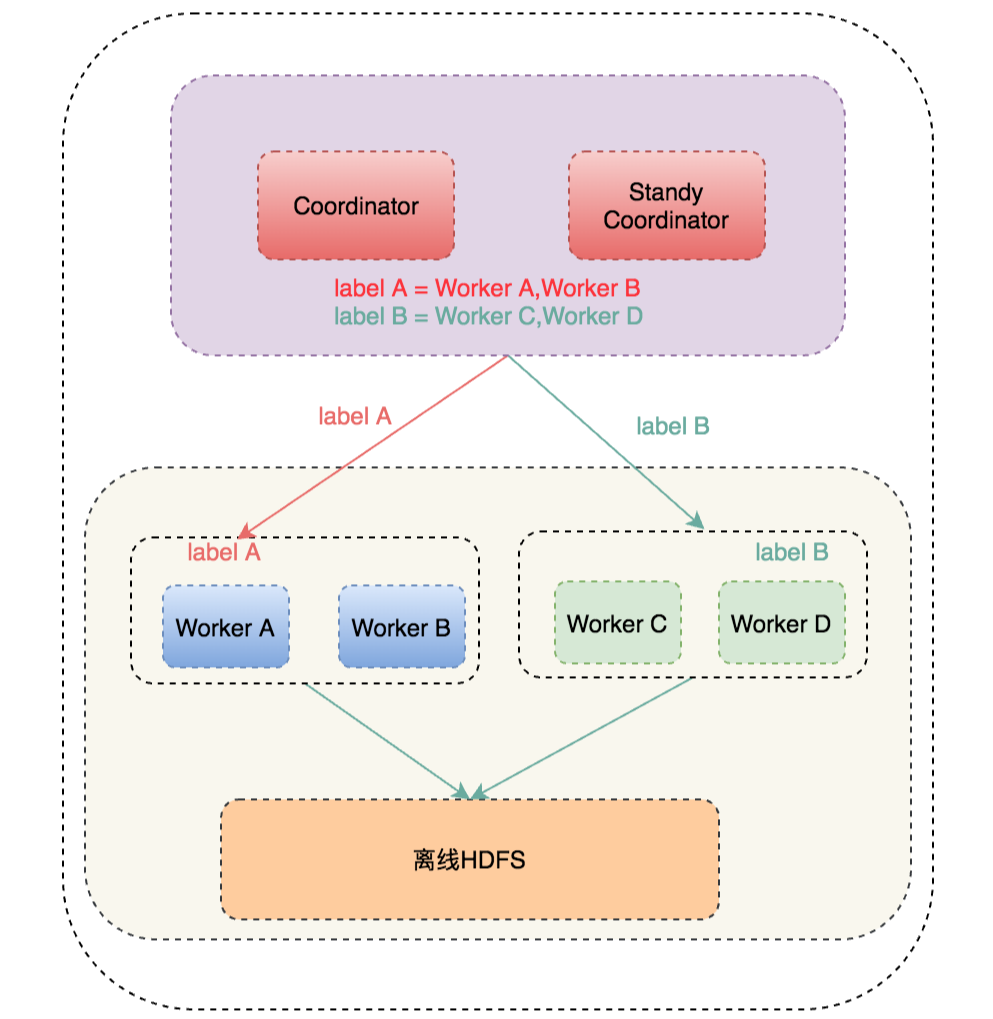

在Presto交流社區,Presto的穩定性問題困擾了很多Presto使用者,包括Coordinator和Worker掛掉,集群運行一段時間后查詢性能變慢等。我們在解決這些問題時積累了很多經驗,這里說下解決思路和方法。
根據職責劃分,Presto分為Coordinator和Worker模塊,Coordinator主要負責SQL解析、生成查詢計劃、Split調度及查詢狀態管理等,所以當Coordinator遇到OOM或者Coredump時,獲取元信息及生成Splits是重點懷疑的地方。而內存問題,推薦使用MAT分析具體原因。如下圖是通過MAT分析,得出開啟了FileSystem Cache,內存泄漏導致OOM。

通過以上工作,滴滴Presto逐漸接入公司各大數據平臺,并成為了公司首選Ad-Hoc查詢引擎及Hive SQL加速引擎,下圖可以看到某產品接入后的性能提升:
上圖可以看到大約2018年10月該平臺開始接入Presto,查詢耗時TP50性能提升了10+倍,由400S降低到31S。且在任務數逐漸增長的情況下,查詢耗時保證穩定不變。
而高性能集群,我們做了很多穩定性和性能優化工作,保證了平均查詢時間小于2S。如下圖所示:
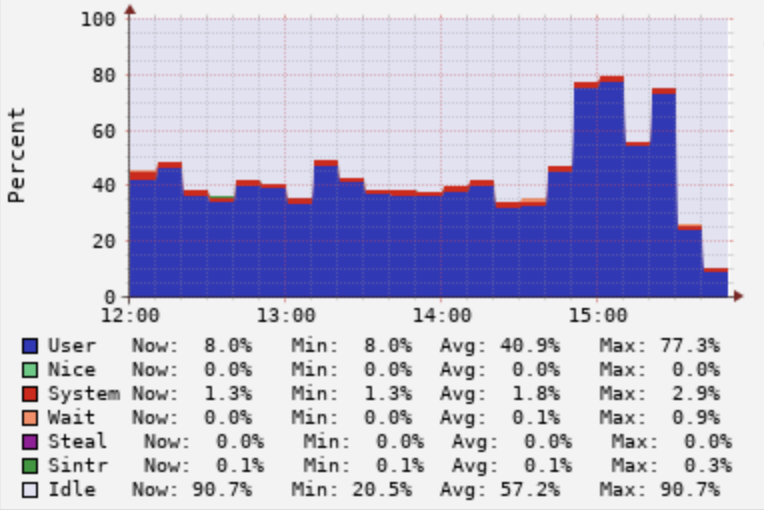
但是如果看最近一個月的CPU使用率會發現,平均CPU使用率比較低,且波峰在白天10~18點,晚上基本上沒有查詢,CPU使用率不到5%。如下圖所示:
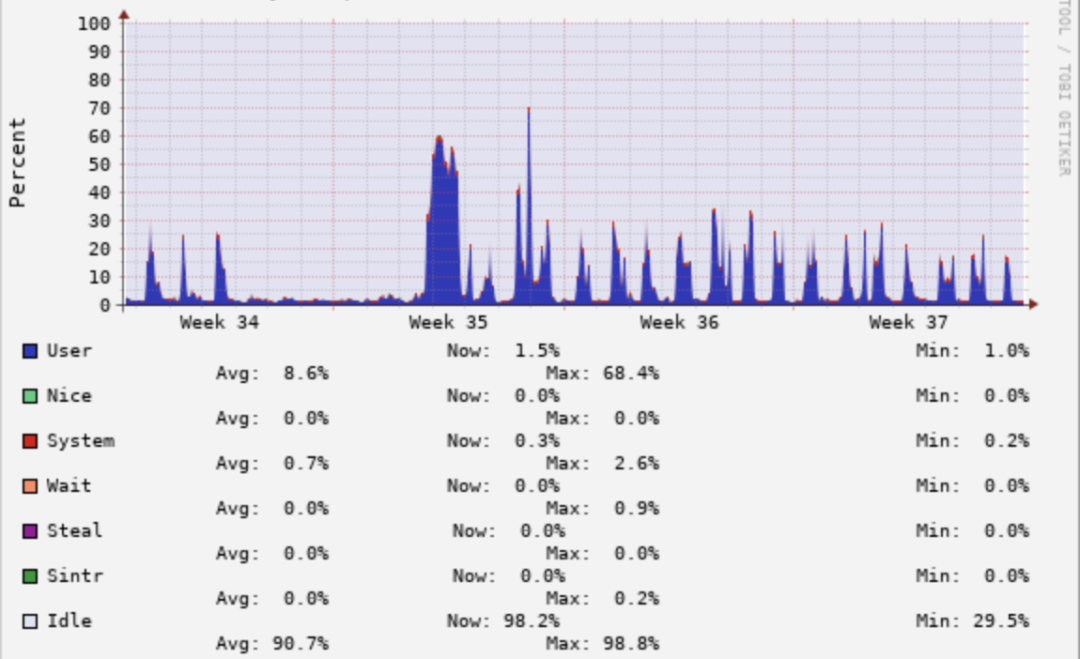
所以,解決晚上資源浪費問題是我們今后需要解決的難題。
看完上述內容,你們對Presto在軟件的探索與實踐是怎樣的有進一步的了解嗎?如果還想了解更多知識或者相關內容,請關注億速云行業資訊頻道,感謝大家的支持。
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





