溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
這篇文章主要介紹“DataFrame操作方法有哪些”,在日常操作中,相信很多人在DataFrame操作方法有哪些問題上存在疑惑,小編查閱了各式資料,整理出簡單好用的操作方法,希望對大家解答”DataFrame操作方法有哪些”的疑惑有所幫助!接下來,請跟著小編一起來學習吧!
Pandas提供了各種各樣的DataFrame操作,但是其中許多操作很復雜,而且似乎不太平易近人。ame操作方法,它們涵蓋了數據科學家需要知道的幾乎所有操作功能。每種方法都將包括說明,可視化,代碼以及記住它的技巧。
Pivot
透視表將創建一個新的“透視表”,該透視表將數據中的現有列投影為新表的元素,包括索引,列和值。初始DataFrame中將成為索引的列,并且這些列顯示為唯一值,而這兩列的組合將顯示為值。這意味著Pivot無法處理重復的值。
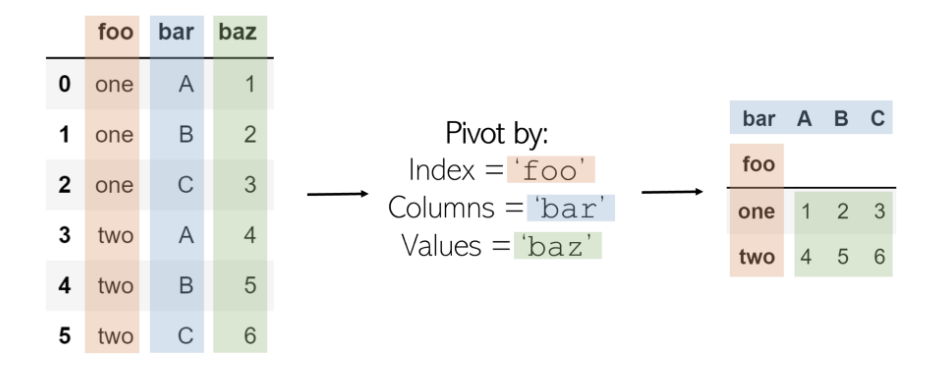
旋轉名為df 的DataFrame的代碼 如下:
記住:Pivot——是在數據處理領域之外——圍繞某種對象的轉向。在體育運動中,人們可以繞著腳“旋轉”旋轉:大熊貓的旋轉類似于。原始DataFrame的狀態圍繞DataFrame的中心元素旋轉到一個新元素。有些元素實際上是在旋轉或變換的(例如,列“ bar ”),因此很重要。
Melt
Melt可以被認為是“不可透視的”,因為它將基于矩陣的數據(具有二維)轉換為基于列表的數據(列表示值,行表示唯一的數據點),而樞軸則相反。考慮一個二維矩陣,其一維為“ B ”和“ C ”(列名),另一維為“ a”,“ b ”和“ c ”(行索引)。
我們選擇一個ID,一個維度和一個包含值的列/列。包含值的列將轉換為兩列:一列用于變量(值列的名稱),另一列用于值(變量中包含的數字)。
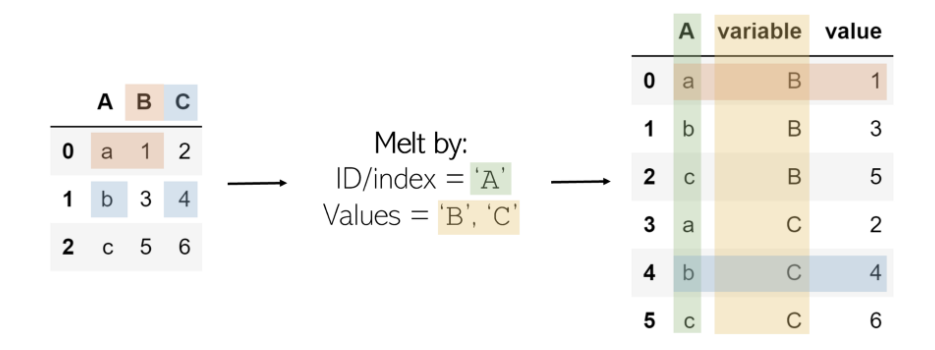
結果是ID列的值(a,b,c)和值列(B,C)及其對應值的每種組合,以列表格式組織。
可以像在DataFrame df上一樣執行Mels操作 :
記住:像蠟燭一樣融化(Melt)就是將凝固的復合物體變成幾個更小的單個元素(蠟滴)。融合二維DataFrame可以解壓縮其固化的結構并將其片段記錄為列表中的各個條目。
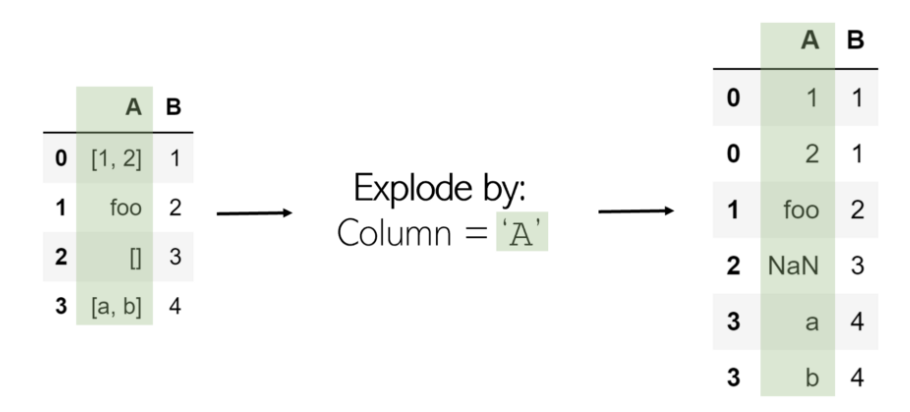
在DataFrame df中Explode列“ A ” 非常簡單:

要記住:Explode某物會釋放其所有內部內容-Explode列表會分隔其元素。
Stack
堆疊采用任意大小的DataFrame,并將列“堆疊”為現有索引的子索引。因此,所得的DataFrame僅具有一列和兩級索引。
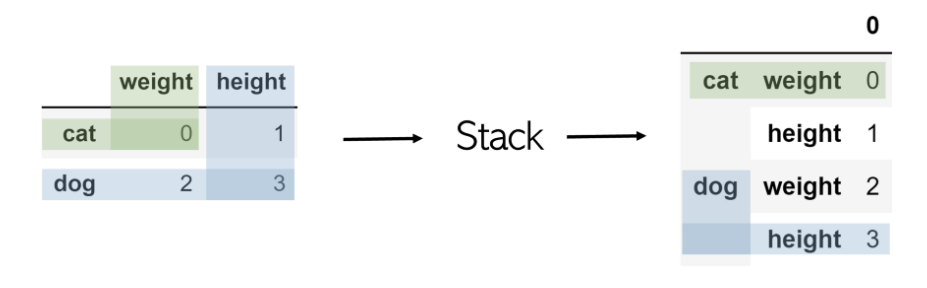
堆疊名為df的表就像df.stack()一樣簡單 。
為了訪問狗的身高值,只需兩次調用基于索引的檢索,例如 df.loc ['dog']。loc ['height']。
要記住:從外觀上看,堆棧采用表的二維性并將列堆棧為多級索引。
Unstack
取消堆疊將獲取多索引DataFrame并對其進行堆疊,將指定級別的索引轉換為具有相應值的新DataFrame的列。在表上調用堆棧后再調用堆棧不會更改該堆棧(原因是存在“ 0 ”)。
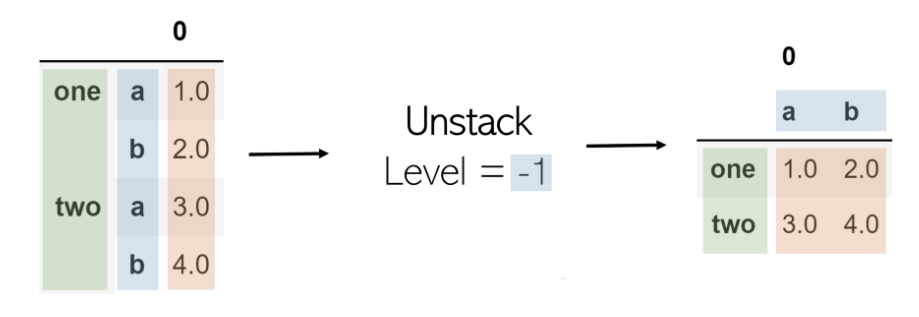
堆疊中的參數是其級別。在列表索引中,索引為-1將返回最后一個元素。這與水平相同。級別-1表示將取消堆疊最后一個索引級別(最右邊的一個)。作為另一個示例,當級別設置為0(第一個索引級別)時,其中的值將成為列,而隨后的索引級別(第二個索引級別)將成為轉換后的DataFrame的索引。
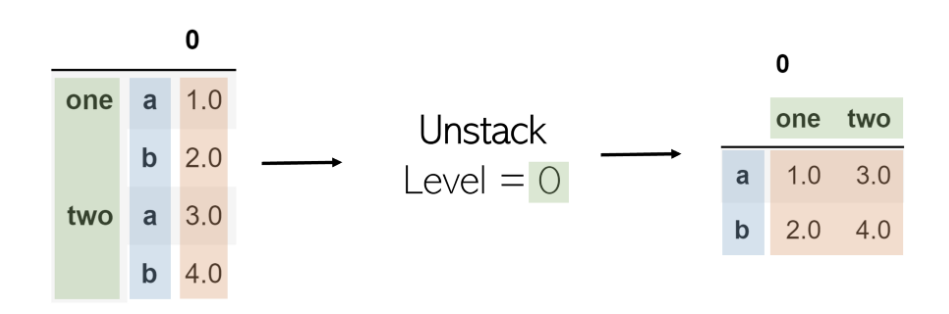
可以按照與堆疊相同的方式執行堆疊,但是要使用level參數: df.unstack(level = -1)。
Merge
合并兩個DataFrame是在共享的“鍵”之間按列(水平)組合它們。此鍵允許將表合并,即使它們的排序方式不一樣。完成的合并DataFrame 默認情況下會將后綴_x 和 _y添加 到value列。
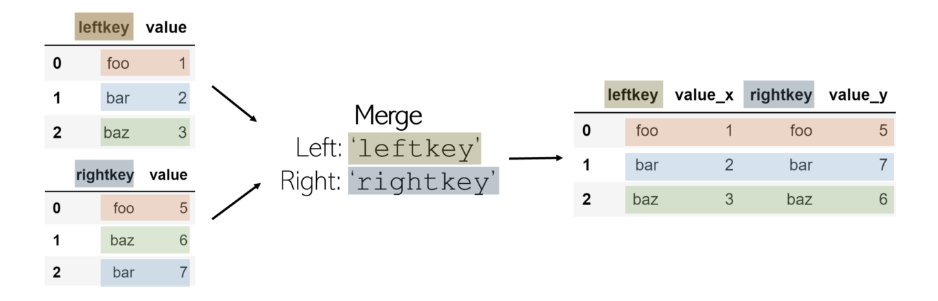
為了合并兩個DataFrame df1 和 df2 (其中 df1 包含 leftkey, 而 df2 包含 rightkey),請調用:

合并不是pandas的功能,而是附加到DataFrame。始終假定合并所在的DataFrame是“左表”,在函數中作為參數調用的DataFrame是“右表”,并帶有相應的鍵。
默認情況下,合并功能執行內部聯接:如果每個DataFrame的鍵名均未列在另一個鍵中,則該鍵不包含在合并的DataFrame中。另一方面,如果一個鍵在同一DataFrame中列出兩次,則在合并表中將列出同一鍵的每個值組合。例如,如果 df1 具有3個鍵foo 值, 而 df2 具有2個相同鍵的值,則 在最終DataFrame中將有6個條目,其中 leftkey = foo 和 rightkey = foo。
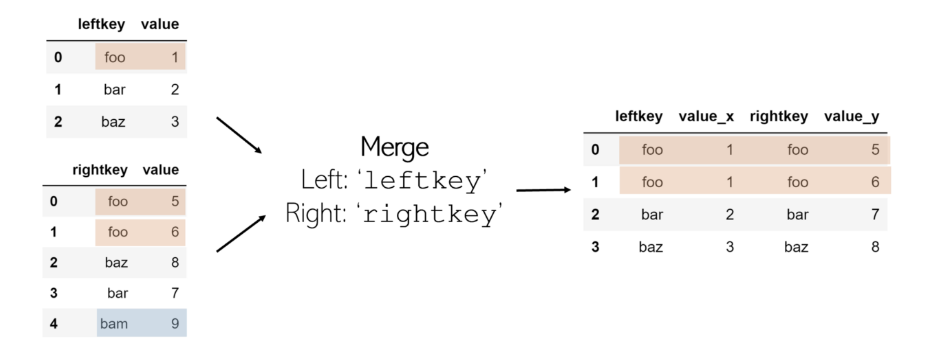
記住:合并數據幀就像在水平行駛時合并車道一樣。想象一下,每一列都是高速公路上的一條車道。為了合并,它們必須水平合并。
Join
通常,聯接比合并更可取,因為它具有更簡潔的語法,并且在水平連接兩個DataFrame時具有更大的可能性。連接的語法如下:
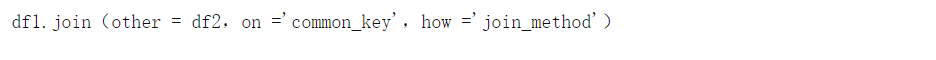
使用聯接時,公共鍵列(類似于 合并中的right_on 和 left_on)必須命名為相同的名稱。how參數是一個字符串,它表示四種連接 方法之一, 可以合并兩個DataFrame:
' left ':包括df1的所有元素, 僅當其鍵為df1的鍵時才 包含df2的元素 。否則,df2的合并DataFrame的丟失部分 將被標記為NaN。
' right ':' left ',但在另一個DataFrame上。包括df2的所有元素, 僅當其鍵是df2的鍵時才 包含df1的元素 。
“outer”:包括來自DataFrames所有元素,即使密鑰不存在于其他的-缺少的元素被標記為NaN的。
“inner”:僅包含元件的鍵是存在于兩個數據幀鍵(交集)。默認合并。
記住:如果您使用過SQL,則單詞“ join”應立即與按列添加相聯系。如果不是,則“ join”和“ merge”在定義方面具有非常相似的含義。
Concat
合并和連接是水平工作,串聯或簡稱為concat,而DataFrame是按行(垂直)連接的。例如,考慮使用pandas.concat([df1,df2])串聯的具有相同列名的 兩個DataFrame df1 和 df2 :
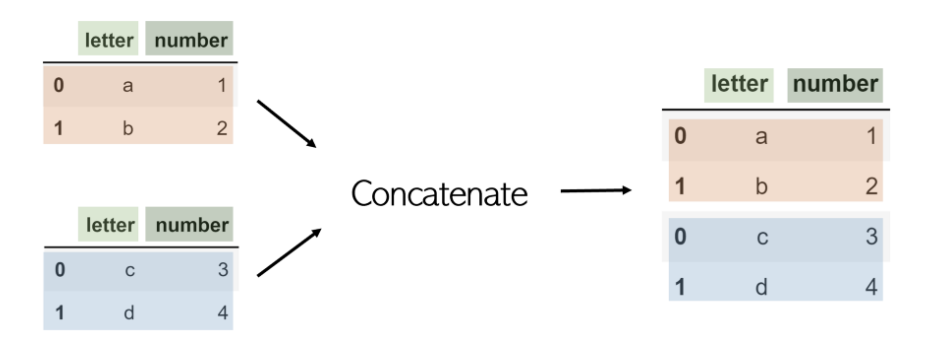
盡管可以通過將axis參數設置為1來使用concat進行列式聯接,但是使用聯接 會更容易。
請注意,concat是pandas函數,而不是DataFrame之一。因此,它接受要連接的DataFrame列表。
如果一個DataFrame的另一列未包含,默認情況下將包含該列,缺失值列為NaN。為了防止這種情況,請添加一個附加參數join ='inner',該參數 只會串聯兩個DataFrame共有的列。

切記:在列表和字符串中,可以串聯其他項。串聯是將附加元素附加到現有主體上,而不是添加新信息(就像逐列聯接一樣)。由于每個索引/行都是一個單獨的項目,因此串聯將其他項目添加到DataFrame中,這可以看作是行的列表。
Append是組合兩個DataFrame的另一種方法,但它執行的功能與concat相同,效率較低且用途廣泛。
到此,關于“DataFrame操作方法有哪些”的學習就結束了,希望能夠解決大家的疑惑。理論與實踐的搭配能更好的幫助大家學習,快去試試吧!若想繼續學習更多相關知識,請繼續關注億速云網站,小編會繼續努力為大家帶來更多實用的文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





