溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容主要講解“influxdb的原理是什么”,感興趣的朋友不妨來看看。本文介紹的方法操作簡單快捷,實用性強。下面就讓小編來帶大家學習“influxdb的原理是什么”吧!
參考
LSM樹詳解 https://zhuanlan.zhihu.com/p/181498475
https://www.jianshu.com/p/a3a2f8f5dd65
http://hbasefly.com/2017/12/08/influxdb-1/?qytefg=c4ft23
http://hbasefly.com/2017/11/19/timeseries-database-2/?fypwxu=zot6w
https://blog.fatedier.com/2016/08/05/detailed-in-influxdb-tsm-storage-engine-one/
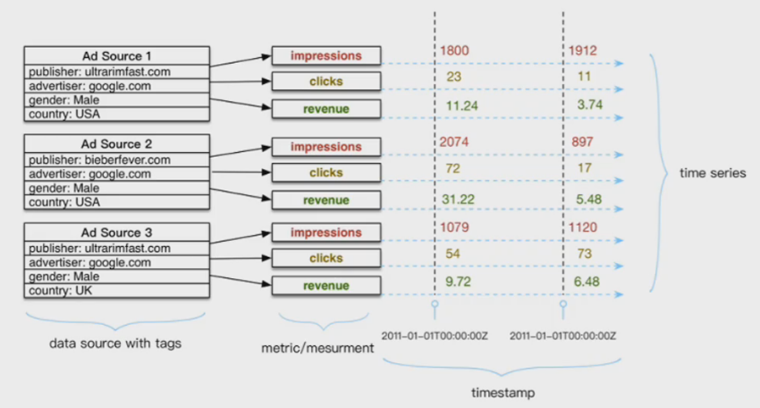
什么是時序數據庫
數據模式: 時序數據隨時間增長,相同維度重復取值,指標平滑變化
寫入: 持續高并發寫入,無更新操作:時序數據庫面對的往往是百萬甚至千萬數量級終端設備的實時數據寫入(如摩拜單車2017年全國車輛數為千萬級),但數據大多表征設備狀態,寫入后不會更新
查詢: 按不同維度對指標進行統計分析,且存在明顯的冷熱數據,一般只會頻繁查詢近期數據
可以看到時序數據庫需要解決以下幾個問題:
時序數據的寫入:如何支持每秒鐘上千萬上億數據點的寫入。
時序數據的讀取:如何支持在秒級對上億數據的分組聚合運算。
成本敏感:由海量數據存儲帶來的是成本問題。如何更低成本的存儲這些數據,將成為時序數據庫需要解決的重中之重。
LSM樹
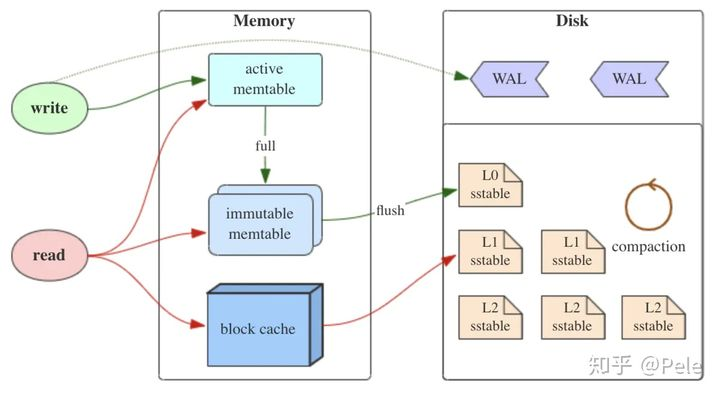
更通俗的講,LSM樹原理就是把一棵大樹拆分成N棵小樹,它首先寫入內存中,隨著小樹越來越大,內存中的小樹會批量flush到磁盤中獨立的文件中以提高IO性能,而為了提高讀性能磁盤中的樹定期可以做merge操作,合并成一棵大樹。
SSTable 就是 MemTable 中的數據在磁盤上的有序存儲,其內部數據是根據 key 從小到大排列的。通常為了加快查找的速度,需要在 SSTable 中加入數據索引,可以快讀定位到指定的 k-v 數據。 
顧名思義,Immutable Memtable 就是在內存中只讀的 MemTable,由于內存是有限的,通常我們會設置一個閥值,當 MemTable 占用的內存達到閥值后就自動轉換為 Immutable Memtable,Immutable Memtable 和 MemTable 的區別就是它是只讀的,系統此時會生成新的 MemTable 供寫操作繼續寫入。之所以要使用 Immutable Memtable,就是為了避免將 MemTable 中的內容序列化到磁盤中時會阻塞寫操作。
MemTable 對應的就是 WAL 文件,是該文件內容在內存中的存儲結構,通常用 SkipList 來實現。MemTable 提供了 k-v 數據的寫入、刪除以及讀取的操作接口。其內部將 k-v 對按照 key 值有序存儲,這樣方便之后快速序列化到 SSTable 文件中,仍然保持數據的有序性。
MemTable
Immutable Memtable
SSTable
TSM(Time-Structured Merge Tree)
InfluxDB底層的存儲引擎經歷了從LevelDB到BlotDB,再到選擇自研TSM的過程,整個選擇轉變的思考可以在其官網文檔里看到。整個思考過程很值得借鑒,對技術選型和轉變的思考總是比平白的描述某個產品特性讓人印象深刻的多。
它的整個存儲引擎選型轉變的過程,第一階段是LevelDB,選型LevelDB的主要原因是其底層數據結構采用LSM,對寫入很友好,能夠提供很高的寫入吞吐量,比較符合時序數據的特性。在LevelDB內,數據是采用KeyValue的方式存儲且按Key排序,InfluxDB使用的Key設計是SeriesKey+Timestamp的組合,所以相同SeriesKey的數據是按timestamp來排序存儲的,能夠提供很高效的按時間范圍的掃描。
不過使用LevelDB的一個最大的問題是,InfluxDB支持歷史數據自動刪除(Retention Policy),在時序數據場景下數據自動刪除通常是大塊的連續時間段的歷史數據刪除。LevelDB不支持Range delete也不支持TTL(time to live),所以要刪除只能是一個一個key的刪除,會造成大量的刪除流量壓力,且在LSM這種數據結構下,真正的物理刪除不是即時的,在compaction時才會生效。
時序數據庫結構
OpenTSDB/HBase
OpenTSDB基于HBase存儲時序數據,在HBase層面設計RowKey規則為:metric+timestamp+datasource(tags)
問題一:存在很多無用的字段。一個KeyValue中只有rowkey是有用的,其他字段諸如columnfamily、column、timestamp以及keytype從理論上來講都沒有任何實際意義,但在HBase的存儲體系里都必須存在,因而耗費了很大的存儲成本。
問題二:數據源和采集指標冗余。KeyValue中rowkey等于metric+timestamp+datasource,試想同一個數據源的同一個采集指標,隨著時間的流逝不斷吐出采集數據,這些數據理論上共用同一個數據源(datasource)和采集指標(metric),但在HBase的這套存儲體系下,共用是無法體現的,因此存在大量的數據冗余,主要是數據源冗余以及采集指標冗余。
問題三:無法有效的壓縮。HBase提供了塊級別的壓縮算法-snappy、gzip等,這些通用壓縮算法并沒有針對時序數據進行設置,壓縮效率比較低。HBase同樣提供了一些編碼算法,比如FastDiff等等,可以起到一定的壓縮效果,但是效果并不佳。效果不佳的主要原因是HBase沒有數據類型的概念,沒有schema的概念,不能針對特定數據類型進行特定編碼,只能選擇通用的編碼,效果可想而知。
問題四:不能完全保證多維查詢能力。HBase本身沒有schema,目前沒有實現倒排索引機制,所有查詢必須指定metric、timestamp以及完整的tags或者前綴tags進行查詢,對于后綴維度查詢也勉為其難。
influxdb
相比OpenTSDB以及Druid,可能很多童鞋對InfluxDB并不特別熟悉,然而在時序數據庫排行榜單上InfluxDB卻是遙遙領先。InfluxDB是一款專業的時序數據庫,只存儲時序數據,因此在數據模型的存儲上可以針對時序數據做非常多的優化工作。
為了保證寫入的高效,InfluxDB也采用LSM結構,數據先寫入內存,當內存容量達到一定閾值之后flush到文件 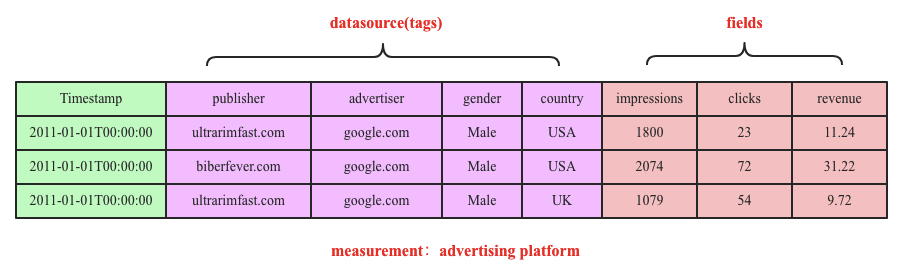 InfluxDB在時序數據模型設計方面提出了一個非常重要的概念:seriesKey,seriesKey實際上就是measurement+datasource(tags).時序數據寫入內存之后按照seriesKey進行組織:
InfluxDB在時序數據模型設計方面提出了一個非常重要的概念:seriesKey,seriesKey實際上就是measurement+datasource(tags).時序數據寫入內存之后按照seriesKey進行組織: 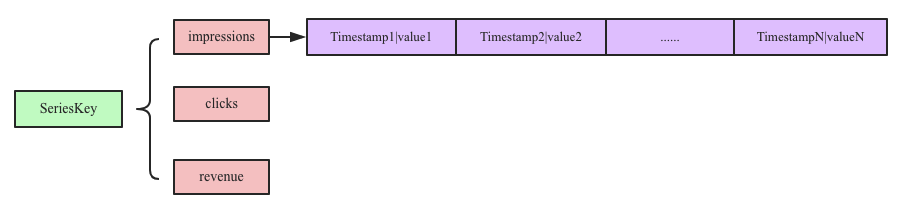
內存中實際上就是一個Map:<SeriesKey+fieldKey, List<Timestamp|Value>>,Map中一個SeriesKey+fieldKey對應一個List,List中存儲時間線數據。數據進來之后根據measurement+datasource(tags)拼成SeriesKey,加上fieldKey,再將Timestamp|Value組合值寫入時間線數據List中。內存中的數據flush的文件后,同樣會將同一個SeriesKey中的時間線數據寫入同一個Block塊內,即一個Block塊內的數據都屬于同一個數據源下的同一個field。
將datasource(tags)和metric拼成SeriesKey,不是也不能實現多維查找。確實是這樣,不過InfluxDB內部實現了倒排索引機制,即實現了tag到SeriesKey的映射關系,如果用戶想根據某個tag查找的話,首先根據tag在倒排索引中找到對應的SeriesKey,再根據SeriesKey定位具體的時間線數據。InfluxDB的這種存儲引擎稱為TSM,全稱為Timestamp-Structure Merge Tree,基本原理類似于LSM。后期筆者將會對InfluxDB的數據寫入、文件格式、倒排索引以及數據讀取進行專題介紹。
InfluxDB 數據模型 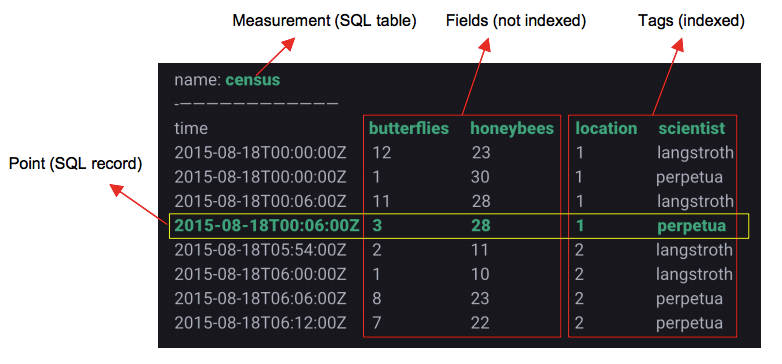
Measurement:從原理上講更像SQL中表的概念
Tags:維度列
在InfluxDB中,表中Tags組合會被作為記錄的主鍵,因此主鍵并不唯一,比如上表中第一行和第三行記錄的主鍵都為’location=1,scientist=langstroth’。所有時序查詢最終都會基于主鍵查詢之后再經過時間戳過濾完成。
Fields:數值列。數值列存放用戶的時序數據
Point:類似SQL中一行記錄,而并不是一個點。
InfluxDB 系統架構 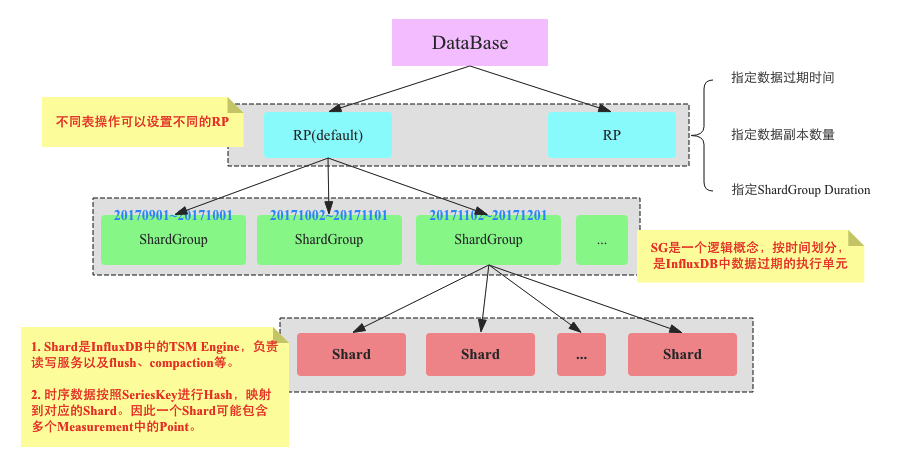
到此,相信大家對“influxdb的原理是什么”有了更深的了解,不妨來實際操作一番吧!這里是億速云網站,更多相關內容可以進入相關頻道進行查詢,關注我們,繼續學習!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





