溫馨提示×
您好,登錄后才能下訂單哦!
點擊 登錄注冊 即表示同意《億速云用戶服務條款》
您好,登錄后才能下訂單哦!
本篇內容介紹了“怎么使用Python庫管理大數據”的有關知識,在實際案例的操作過程中,不少人都會遇到這樣的困境,接下來就讓小編帶領大家學習一下如何處理這些情況吧!希望大家仔細閱讀,能夠學有所成!

BigQuery
谷歌BigQuery是一個非常受歡迎的企業倉庫,由谷歌云平臺(GCP)和Bigtable組合而成。這個云服務可以很好地處理各種大小的數據,并在幾秒鐘內執行復雜的查詢。
BigQuery是一個RESTful網絡服務,它使開發人員能夠結合谷歌云平臺對大量數據集進行交互分析。可以看看下方另一個例子。
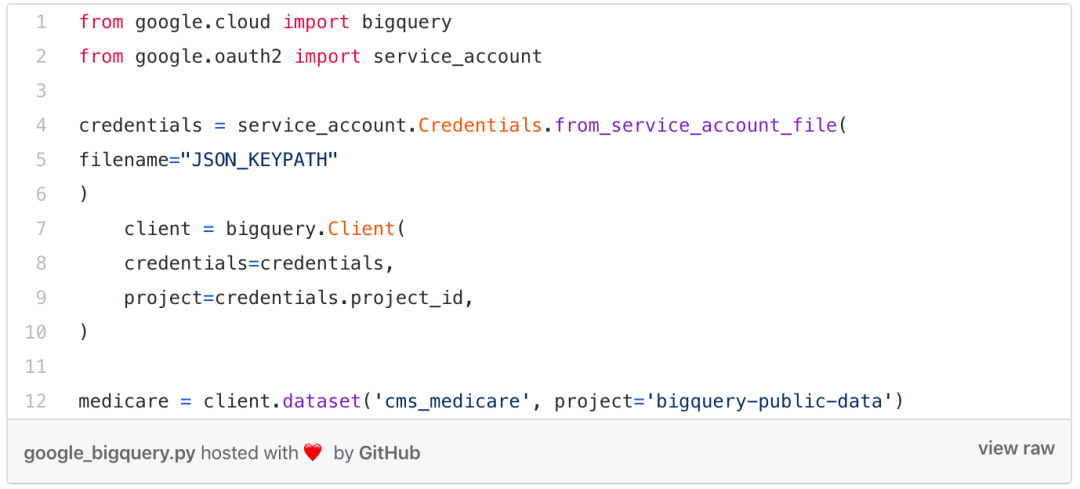
之前寫過一篇文章里有說明如何連接到BigQuery,然后開始獲取有關將與之交互的表和數據集的信息。在這種情況下,Medicare數據集是任何人都可以訪問的開源數據集。
關于BigQuery的另一點是,它是在Bigtable上運行的。重要的是要了解該倉庫不是事務型數據庫。因此,不能將其視為在線交易處理(OLTP)數據庫。它是專為大數據而設計的。所以它的工作與千萬字節(PB)級的數據集的處理保持一致。

Redshift and Sometimes S3
接下來是亞馬遜(Amazon)流行的Redshift和S3。AmazonS3本質上是一項存儲服務,用于從互聯網上的任何地方存儲和檢索大量數據。使用這項服務,你只需為實際使用的存儲空間付費。另一方面,Redshift是一個管理完善的數據倉庫,可以有效地處理千萬字節(PB)級的數據。該服務使用SQL和BI工具可以更快地進行查詢。
Amazon Redshift和S3作為一個強大的組合來處理數據:使用S3可以將大量數據上傳Redshift倉庫。用Python編程時,這個功能強大的工具對開發人員來說非常方便。
這是一個選擇使用psycopg2的基本連接的腳本。我借用了Jaychoo代碼。但是,這再次提供了有關如何連接并從Redshift獲取數據的快速指南。

PySpark
讓我們離開數據存儲系統的世界,來研究有助于我們快速處理數據的工具。Apache Spark是一個非常流行的開源框架,可以執行大規模的分布式數據處理,它也可以用于機器學習。該集群計算框架主要側重于簡化分析。它與彈性分布式數據集(RDD)配合使用,并允許用戶處理Spark集群的管理資源。
它通常與其他Apache產品(例如HBase)結合使用。Spark將快速處理數據,然后將其存儲到其他數據存儲系統上設置的表中。
有時候,安裝PySpark可能是個挑戰,因為它需要依賴項。你可以看到它運行在JVM之上,因此需要Java的底層基礎結構才能運行。然而,在Docker盛行的時代,使用PySpark進行實驗更加方便。
阿里巴巴使用PySpark來個性化網頁和投放目標廣告——正如許多其他大型數據驅動組織一樣。
如果你對Python感興趣,歡迎加入我們【python學習交流】,免費領取學習資料和源碼

Kafka Python
Kafka是一個分布式發布-訂閱消息傳遞系統,它允許用戶在復制和分區主題中維護消息源。
這些主題基本上是從客戶端接收數據并將其存儲在分區中的日志。Kafka Python被設計為與Python接口集成的官方Java客戶端。它最好與新的代理商一起使用,并向后兼容所有舊版本。使用KafkaPython編程同時需要引用使用者(KafkaConsumer)和引用生產者(KafkaProducer)。
在Kafka Python中,這兩個方面并存。KafkaConsumer基本上是一個高級消息使用者,將用作官方Java客戶端。
它要求代理商支持群組API。KafkaProducer是一個異步消息生成器,它的操作方式也非常類似于Java客戶端。生產者可以跨線程使用而沒有問題,而消費者則需要多線程處理。

Pydoop
讓我們解決這個問題。Hadoop本身并不是一個數據存儲系統。Hadoop實際上具幾個組件,包括MapReduce和Hadoop分布式文件系統(HDFS)。因此,Pydoop在此列表中,但是你需要將Hadoop與其他層(例如Hive)配對,以便更輕松地處理數據。
Pydoop是Hadoop-Python界面,允許與HDFSAPI交互,并使用純Python代碼編寫MapReduce工作。
該庫允許開發人員無需了解Java即可訪問重要的MapReduce功能,例如RecordReader和Partitioner。
對于大多數數據工程師而言,Pydoop本身可能有點太基本了。你們中的大多數人很可能會在Airbow中編寫在這些系統之上運行的ETLs。但是,至少對你的工作有一個大致的了解還是很不錯的。
“怎么使用Python庫管理大數據”的內容就介紹到這里了,感謝大家的閱讀。如果想了解更多行業相關的知識可以關注億速云網站,小編將為大家輸出更多高質量的實用文章!
免責聲明:本站發布的內容(圖片、視頻和文字)以原創、轉載和分享為主,文章觀點不代表本網站立場,如果涉及侵權請聯系站長郵箱:is@yisu.com進行舉報,并提供相關證據,一經查實,將立刻刪除涉嫌侵權內容。





